 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeng Wang
TBraTS: Trusted Brain Tumor Segmentation
Jun 19, 2022
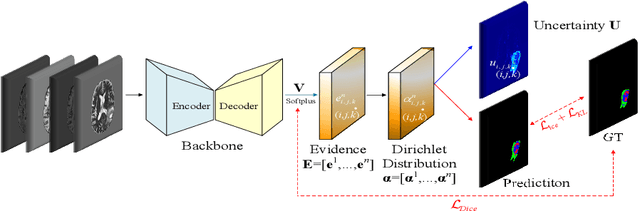

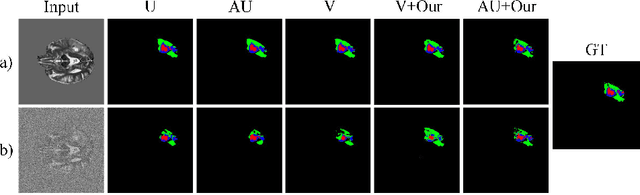
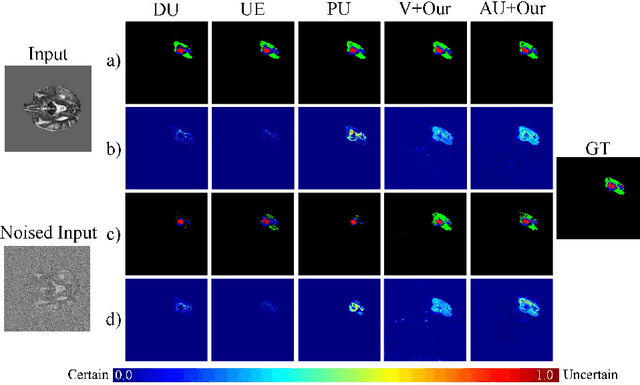
Despite recent improvements in the accuracy of brain tumor segmentation, the results still exhibit low levels of confidence and robustness. Uncertainty estimation is one effective way to change this situation, as it provides a measure of confidence in the segmentation results. In this paper, we propose a trusted brain tumor segmentation network which can generate robust segmentation results and reliable uncertainty estimations without excessive computational burden and modification of the backbone network. In our method, uncertainty is modeled explicitly using subjective logic theory, which treats the predictions of backbone neural network as subjective opinions by parameterizing the class probabilities of the segmentation as a Dirichlet distribution. Meanwhile, the trusted segmentation framework learns the function that gathers reliable evidence from the feature leading to the final segmentation results. Overall, our unified trusted segmentation framework endows the model with reliability and robustness to out-of-distribution samples. To evaluate the effectiveness of our model in robustness and reliability, qualitative and quantitative experiments are conducted on the BraTS 2019 dataset.
A Review-aware Graph Contrastive Learning Framework for Recommendation
May 04, 2022
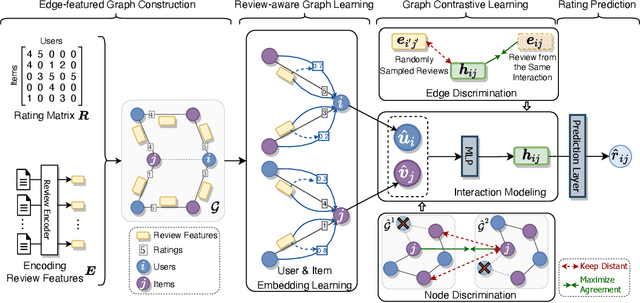
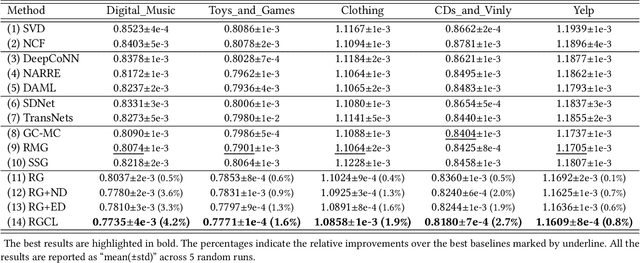
Most modern recommender systems predict users preferences with two components: user and item embedding learning, followed by the user-item interaction modeling. By utilizing the auxiliary review information accompanied with user ratings, many of the existing review-based recommendation models enriched user/item embedding learning ability with historical reviews or better modeled user-item interactions with the help of available user-item target reviews. Though significant progress has been made, we argue that current solutions for review-based recommendation suffer from two drawbacks. First, as review-based recommendation can be naturally formed as a user-item bipartite graph with edge features from corresponding user-item reviews, how to better exploit this unique graph structure for recommendation? Second, while most current models suffer from limited user behaviors, can we exploit the unique self-supervised signals in the review-aware graph to guide two recommendation components better? To this end, in this paper, we propose a novel Review-aware Graph Contrastive Learning (RGCL) framework for review-based recommendation. Specifically, we first construct a review-aware user-item graph with feature-enhanced edges from reviews, where each edge feature is composed of both the user-item rating and the corresponding review semantics. This graph with feature-enhanced edges can help attentively learn each neighbor node weight for user and item representation learning. After that, we design two additional contrastive learning tasks (i.e., Node Discrimination and Edge Discrimination) to provide self-supervised signals for the two components in recommendation process. Finally, extensive experiments over five benchmark datasets demonstrate the superiority of our proposed RGCL compared to the state-of-the-art baselines.
Prediction-Based Reachability Analysis for Collision Risk Assessment on Highways
May 03, 2022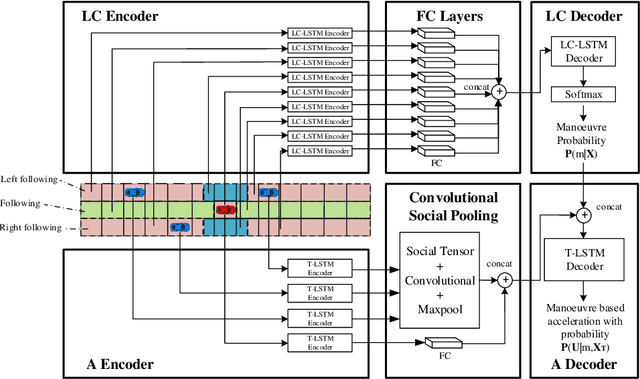
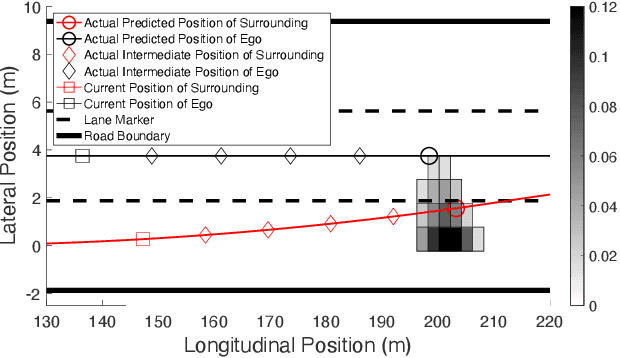
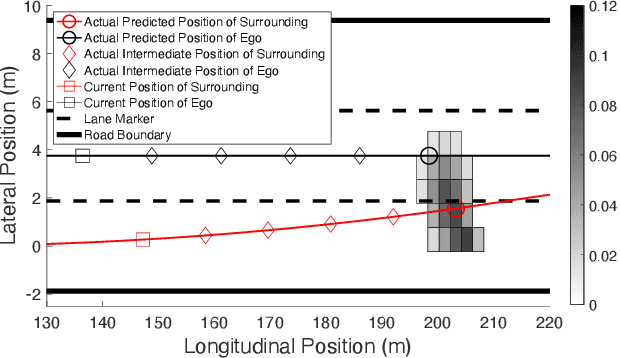
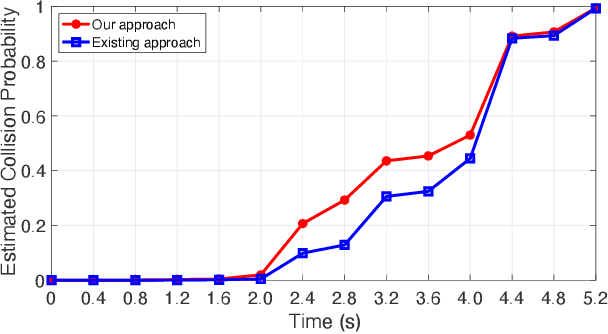
Real-time safety systems are crucial components of intelligent vehicles. This paper introduces a prediction-based collision risk assessment approach on highways. Given a point mass vehicle dynamics system, a stochastic forward reachable set considering two-dimensional motion with vehicle state probability distributions is firstly established. We then develop an acceleration prediction model, which provides multi-modal probabilistic acceleration distributions to propagate vehicle states. The collision probability is calculated by summing up the probabilities of the states where two vehicles spatially overlap. Simulation results show that the prediction model has superior performance in terms of vehicle motion position errors, and the proposed collision detection approach is agile and effective to identify the collision in cut-in crash events.
ClusterQ: Semantic Feature Distribution Alignment for Data-Free Quantization
Apr 30, 2022
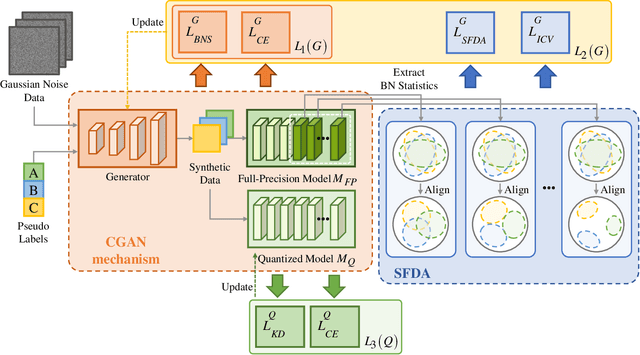
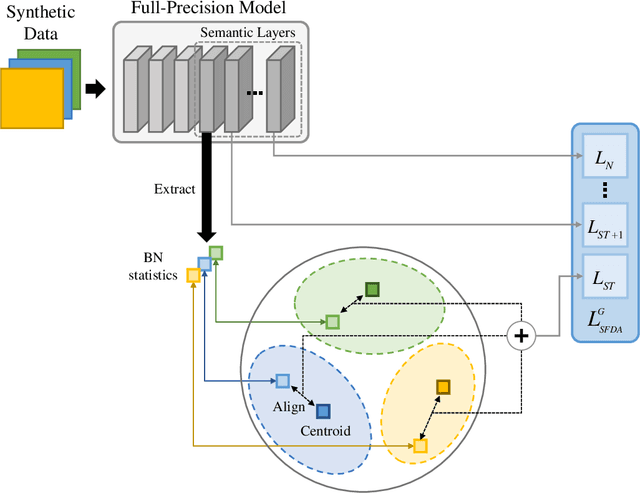
Network quantization has emerged as a promising method for model compression and inference acceleration. However, tradtional quantization methods (such as quantization aware training and post training quantization) require original data for the fine-tuning or calibration of quantized model, which makes them inapplicable to the cases that original data are not accessed due to privacy or security. This gives birth to the data-free quantization with synthetic data generation. While current DFQ methods still suffer from severe performance degradation when quantizing a model into lower bit, caused by the low inter-class separability of semantic features. To this end, we propose a new and effective data-free quantization method termed ClusterQ, which utilizes the semantic feature distribution alignment for synthetic data generation. To obtain high inter-class separability of semantic features, we cluster and align the feature distribution statistics to imitate the distribution of real data, so that the performance degradation is alleviated. Moreover, we incorporate the intra-class variance to solve class-wise mode collapse. We also employ the exponential moving average to update the centroid of each cluster for further feature distribution improvement. Extensive experiments across various deep models (e.g., ResNet-18 and MobileNet-V2) over the ImageNet dataset demonstrate that our ClusterQ obtains state-of-the-art performance.
Audio-Visual Scene Classification Using A Transfer Learning Based Joint Optimization Strategy
Apr 25, 2022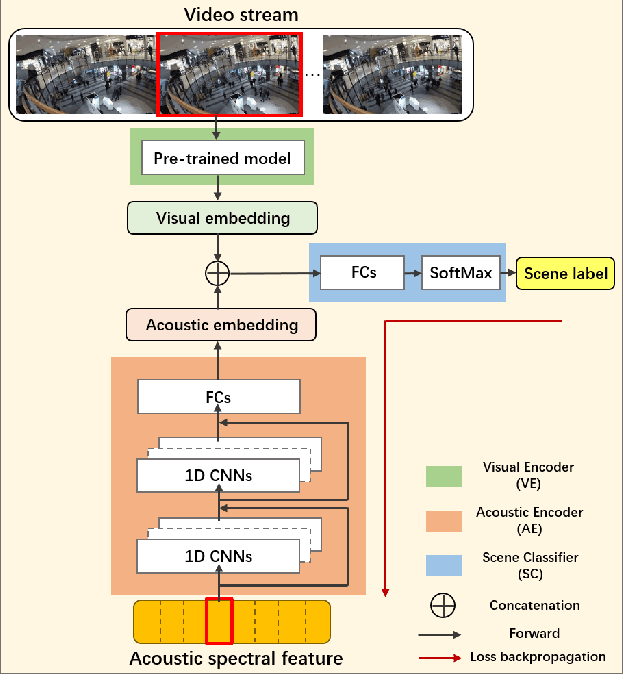


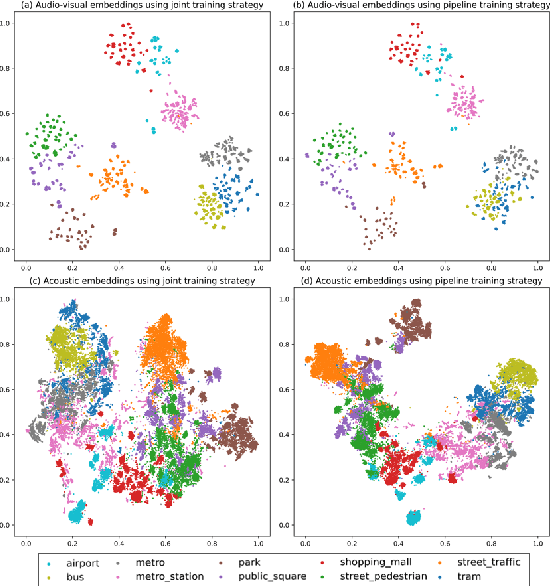
Recently, audio-visual scene classification (AVSC) has attracted increasing attention from multidisciplinary communities. Previous studies tended to adopt a pipeline training strategy, which uses well-trained visual and acoustic encoders to extract high-level representations (embeddings) first, then utilizes them to train the audio-visual classifier. In this way, the extracted embeddings are well suited for uni-modal classifiers, but not necessarily suited for multi-modal ones. In this paper, we propose a joint training framework, using the acoustic features and raw images directly as inputs for the AVSC task. Specifically, we retrieve the bottom layers of pre-trained image models as visual encoder, and jointly optimize the scene classifier and 1D-CNN based acoustic encoder during training. We evaluate the approach on the development dataset of TAU Urban Audio-Visual Scenes 2021. The experimental results show that our proposed approach achieves significant improvement over the conventional pipeline training strategy. Moreover, our best single system outperforms previous state-of-the-art methods, yielding a log loss of 0.1517 and accuracy of 94.59% on the official test fold.
FCL-GAN: A Lightweight and Real-Time Baseline for Unsupervised Blind Image Deblurring
Apr 16, 2022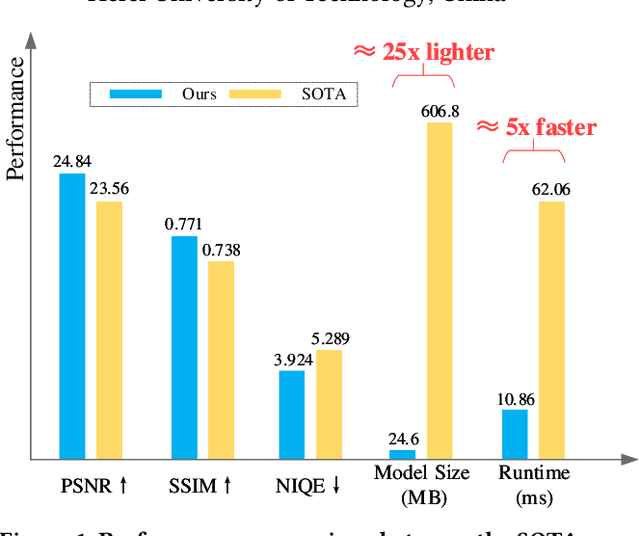
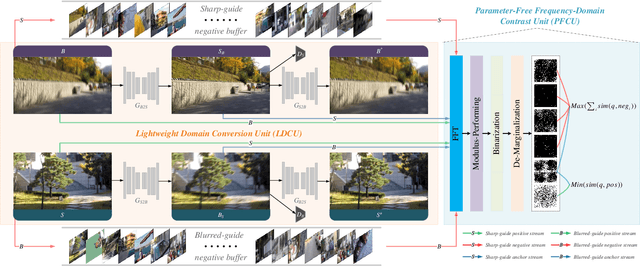
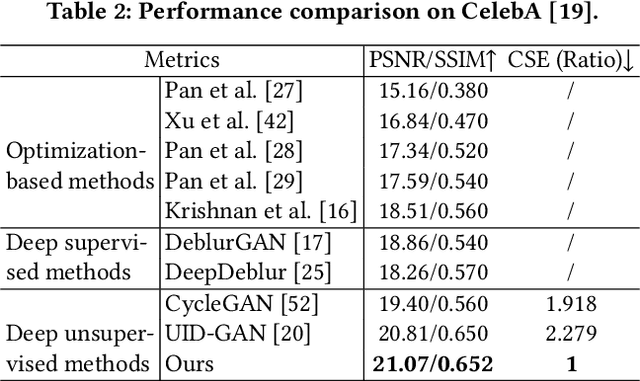

Blind image deblurring (BID) remains a challenging and significant task. Benefiting from the strong fitting ability of deep learning, paired data-driven supervised BID method has obtained great progress. However, paired data are usually synthesized by hand, and the realistic blurs are more complex than synthetic ones, which makes the supervised methods inept at modeling realistic blurs and hinders their real-world applications. As such, unsupervised deep BID method without paired data offers certain advantages, but current methods still suffer from some drawbacks, e.g., bulky model size, long inference time, and strict image resolution and domain requirements. In this paper, we propose a lightweight and real-time unsupervised BID baseline, termed Frequency-domain Contrastive Loss Constrained Lightweight CycleGAN (shortly, FCL-GAN), with attractive properties, i.e., no image domain limitation, no image resolution limitation, 25x lighter than SOTA, and 5x faster than SOTA. To guarantee the lightweight property and performance superiority, two new collaboration units called lightweight domain conversion unit(LDCU) and parameter-free frequency-domain contrastive unit(PFCU) are designed. LDCU mainly implements inter-domain conversion in lightweight manner. PFCU further explores the similarity measure, external difference and internal connection between the blurred domain and sharp domain images in frequency domain, without involving extra parameters. Extensive experiments on several image datasets demonstrate the effectiveness of our FCL-GAN in terms of performance, model size and reference time.
Semi-DRDNet Semi-supervised Detail-recovery Image Deraining Network via Unpaired Contrastive Learning
Apr 06, 2022
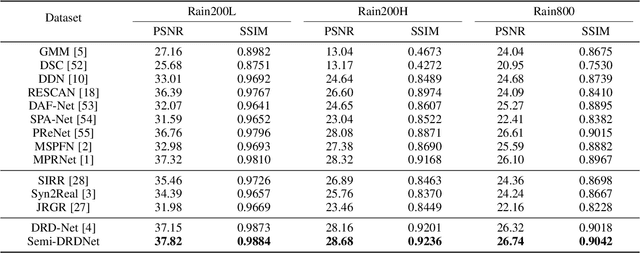
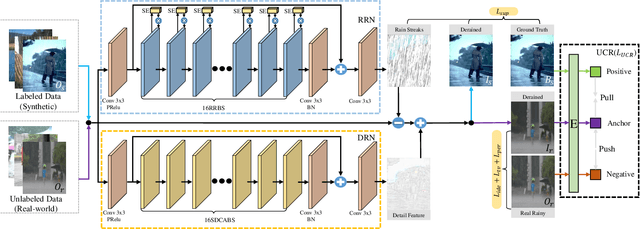

The intricacy of rainy image contents often leads cutting-edge deraining models to image degradation including remnant rain, wrongly-removed details, and distorted appearance. Such degradation is further exacerbated when applying the models trained on synthetic data to real-world rainy images. We raise an intriguing question -- if leveraging both accessible unpaired clean/rainy yet real-world images and additional detail repair guidance, can improve the generalization ability of a deraining model? To answer it, we propose a semi-supervised detail-recovery image deraining network (termed as Semi-DRDNet). Semi-DRDNet consists of three branches: 1) for removing rain streaks without remnants, we present a \textit{squeeze-and-excitation} (SE)-based rain residual network; 2) for encouraging the lost details to return, we construct a \textit{structure detail context aggregation} (SDCAB)-based detail repair network; to our knowledge, this is the first time; and 3) for bridging the domain gap, we develop a novel contrastive regularization network to learn from unpaired positive (clean) and negative (rainy) yet real-world images. As a semi-supervised learning paradigm, Semi-DRDNet operates smoothly on both synthetic and real-world rainy data in terms of deraining robustness and detail accuracy. Comparisons on four datasets show clear visual and numerical improvements of our Semi-DRDNet over thirteen state-of-the-arts.
Thinking inside The Box: Learning Hypercube Representations for Group Recommendation
Apr 06, 2022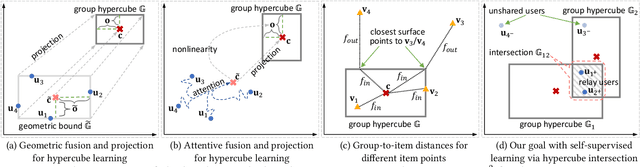
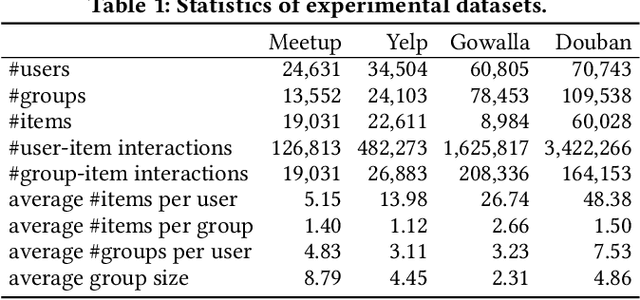
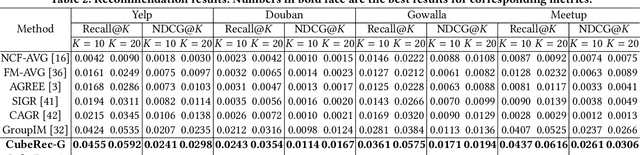
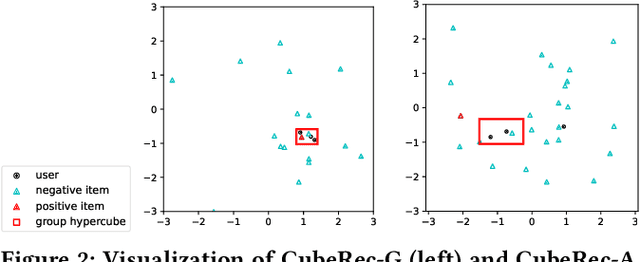
As a step beyond traditional personalized recommendation, group recommendation is the task of suggesting items that can satisfy a group of users. In group recommendation, the core is to design preference aggregation functions to obtain a quality summary of all group members' preferences. Such user and group preferences are commonly represented as points in the vector space (i.e., embeddings), where multiple user embeddings are compressed into one to facilitate ranking for group-item pairs. However, the resulted group representations, as points, lack adequate flexibility and capacity to account for the multi-faceted user preferences. Also, the point embedding-based preference aggregation is a less faithful reflection of a group's decision-making process, where all users have to agree on a certain value in each embedding dimension instead of a negotiable interval. In this paper, we propose a novel representation of groups via the notion of hypercubes, which are subspaces containing innumerable points in the vector space. Specifically, we design the hypercube recommender (CubeRec) to adaptively learn group hypercubes from user embeddings with minimal information loss during preference aggregation, and to leverage a revamped distance metric to measure the affinity between group hypercubes and item points. Moreover, to counteract the long-standing issue of data sparsity in group recommendation, we make full use of the geometric expressiveness of hypercubes and innovatively incorporate self-supervision by intersecting two groups. Experiments on four real-world datasets have validated the superiority of CubeRec over state-of-the-art baselines.
Multi-modal Emotion Estimation for in-the-wild Videos
Mar 31, 2022



In this paper, we briefly introduce our submission to the Valence-Arousal Estimation Challenge of the 3rd Affective Behavior Analysis in-the-wild (ABAW) competition. Our method utilizes the multi-modal information, i.e., the visual and audio information, and employs a temporal encoder to model the temporal context in the videos. Besides, a smooth processor is applied to get more reasonable predictions, and a model ensemble strategy is used to improve the performance of our proposed method. The experiment results show that our method achieves 65.55% ccc for valence and 70.88% ccc for arousal on the validation set of the Aff-Wild2 dataset, which prove the effectiveness of our proposed method.