 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributional View on Multi-Objective Policy Optimization
May 15, 2020
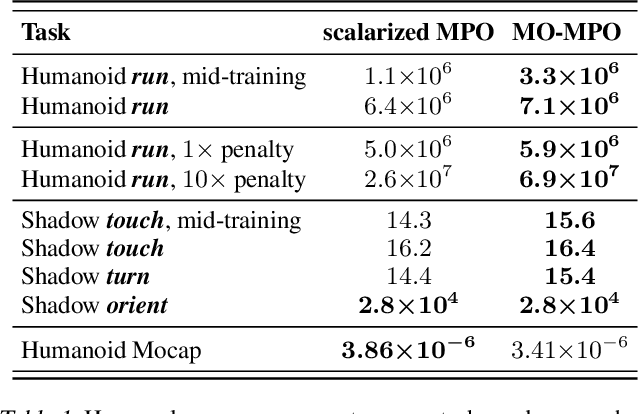
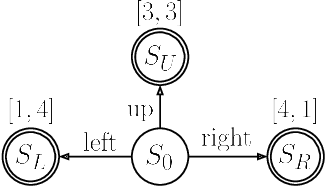
Many real-world problems require trading off multiple competing objectives. However, these objectives are often in different units and/or scales, which can make it challenging for practitioners to express numerical preferences over objectives in their native units. In this paper we propose a novel algorithm for multi-objective reinforcement learning that enables setting desired preferences for objectives in a scale-invariant way. We propose to learn an action distribution for each objective, and we use supervised learning to fit a parametric policy to a combination of these distributions. We demonstrate the effectiveness of our approach on challenging high-dimensional real and simulated robotics tasks, and show that setting different preferences in our framework allows us to trace out the space of nondominated solutions.
Keep Doing What Worked: Behavioral Modelling Priors for Offline Reinforcement Learning
Feb 23, 2020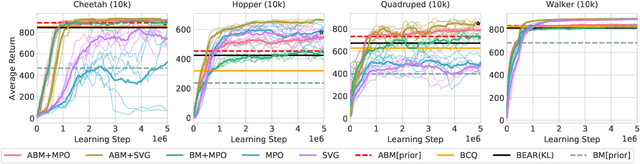

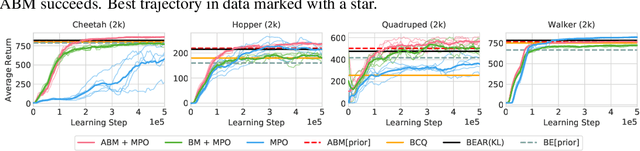
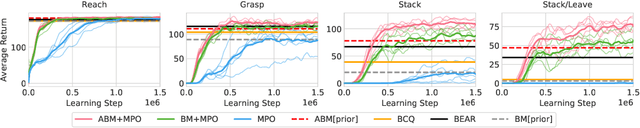
Off-policy reinforcement learning algorithms promise to be applicable in settings where only a fixed data-set (batch) of environment interactions is available and no new experience can be acquired. This property makes these algorithms appealing for real world problems such as robot control. In practice, however, standard off-policy algorithms fail in the batch setting for continuous control. In this paper, we propose a simple solution to this problem. It admits the use of data generated by arbitrary behavior policies and uses a learned prior -- the advantage-weighted behavior model (ABM) -- to bias the RL policy towards actions that have previously been executed and are likely to be successful on the new task. Our method can be seen as an extension of recent work on batch-RL that enables stable learning from conflicting data-sources. We find improvements on competitive baselines in a variety of RL tasks -- including standard continuous control benchmarks and multi-task learning for simulated and real-world robots.
Continuous-Discrete Reinforcement Learning for Hybrid Control in Robotics
Jan 02, 2020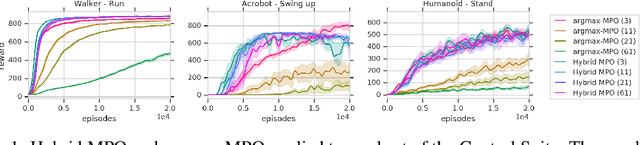



Many real-world control problems involve both discrete decision variables - such as the choice of control modes, gear switching or digital outputs - as well as continuous decision variables - such as velocity setpoints, control gains or analogue outputs. However, when defining the corresponding optimal control or reinforcement learning problem, it is commonly approximated with fully continuous or fully discrete action spaces. These simplifications aim at tailoring the problem to a particular algorithm or solver which may only support one type of action space. Alternatively, expert heuristics are used to remove discrete actions from an otherwise continuous space. In contrast, we propose to treat hybrid problems in their 'native' form by solving them with hybrid reinforcement learning, which optimizes for discrete and continuous actions simultaneously. In our experiments, we first demonstrate that the proposed approach efficiently solves such natively hybrid reinforcement learning problems. We then show, both in simulation and on robotic hardware, the benefits of removing possibly imperfect expert-designed heuristics. Lastly, hybrid reinforcement learning encourages us to rethink problem definitions. We propose reformulating control problems, e.g. by adding meta actions, to improve exploration or reduce mechanical wear and tear.
Quinoa: a Q-function You Infer Normalized Over Actions
Nov 05, 2019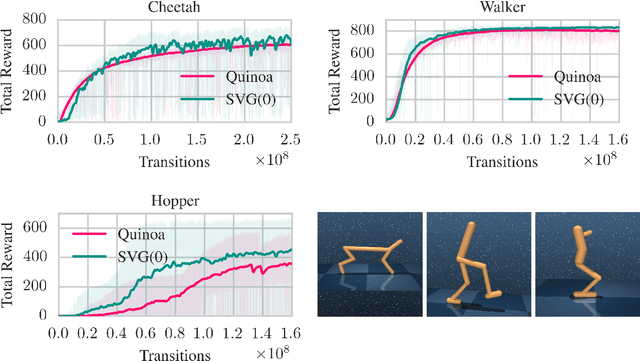
We present an algorithm for learning an approximate action-value soft Q-function in the relative entropy regularised reinforcement learning setting, for which an optimal improved policy can be recovered in closed form. We use recent advances in normalising flows for parametrising the policy together with a learned value-function; and show how this combination can be used to implicitly represent Q-values of an arbitrary policy in continuous action space. Using simple temporal difference learning on the Q-values then leads to a unified objective for policy and value learning. We show how this approach considerably simplifies standard Actor-Critic off-policy algorithms, removing the need for a policy optimisation step. We perform experiments on a range of established reinforcement learning benchmarks, demonstrating that our approach allows for complex, multimodal policy distributions in continuous action spaces, while keeping the process of sampling from the policy both fast and exact.
Imagined Value Gradients: Model-Based Policy Optimization with Transferable Latent Dynamics Models
Oct 09, 2019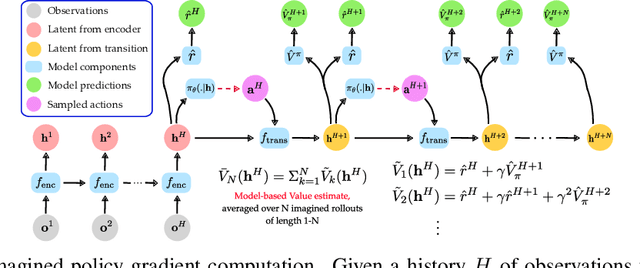



Humans are masters at quickly learning many complex tasks, relying on an approximate understanding of the dynamics of their environments. In much the same way, we would like our learning agents to quickly adapt to new tasks. In this paper, we explore how model-based Reinforcement Learning (RL) can facilitate transfer to new tasks. We develop an algorithm that learns an action-conditional, predictive model of expected future observations, rewards and values from which a policy can be derived by following the gradient of the estimated value along imagined trajectories. We show how robust policy optimization can be achieved in robot manipulation tasks even with approximate models that are learned directly from vision and proprioception. We evaluate the efficacy of our approach in a transfer learning scenario, re-using previously learned models on tasks with different reward structures and visual distractors, and show a significant improvement in learning speed compared to strong off-policy baselines. Videos with results can be found at https://sites.google.com/view/ivg-corl19
V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control
Sep 26, 2019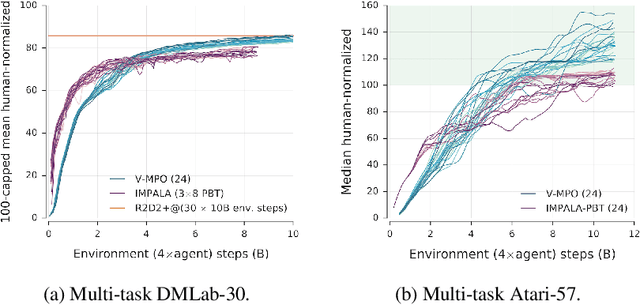
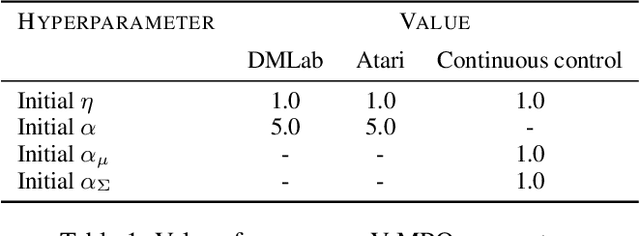
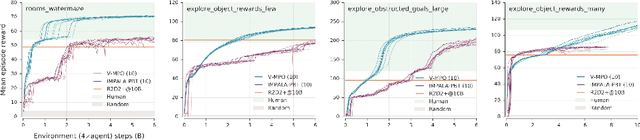

Some of the most successful applications of deep reinforcement learning to challenging domains in discrete and continuous control have used policy gradient methods in the on-policy setting. However, policy gradients can suffer from large variance that may limit performance, and in practice require carefully tuned entropy regularization to prevent policy collapse. As an alternative to policy gradient algorithms, we introduce V-MPO, an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO) that performs policy iteration based on a learned state-value function. We show that V-MPO surpasses previously reported scores for both the Atari-57 and DMLab-30 benchmark suites in the multi-task setting, and does so reliably without importance weighting, entropy regularization, or population-based tuning of hyperparameters. On individual DMLab and Atari levels, the proposed algorithm can achieve scores that are substantially higher than has previously been reported. V-MPO is also applicable to problems with high-dimensional, continuous action spaces, which we demonstrate in the context of learning to control simulated humanoids with 22 degrees of freedom from full state observations and 56 degrees of freedom from pixel observations, as well as example OpenAI Gym tasks where V-MPO achieves substantially higher asymptotic scores than previously reported.
Regularized Hierarchical Policies for Compositional Transfer in Robotics
Jun 27, 2019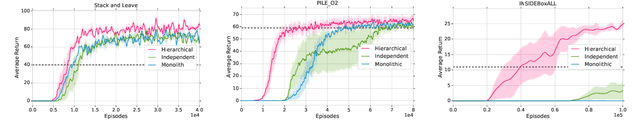
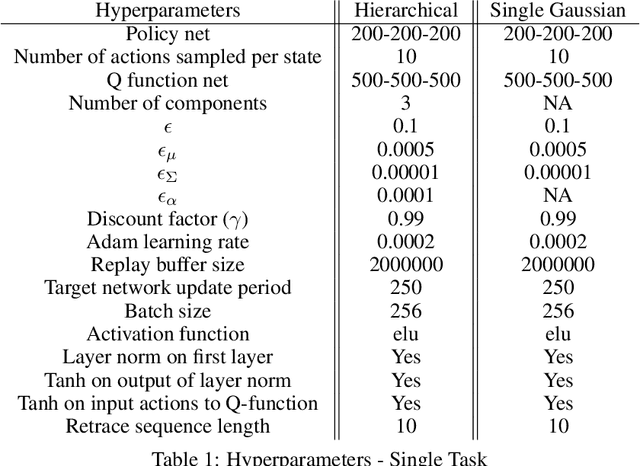

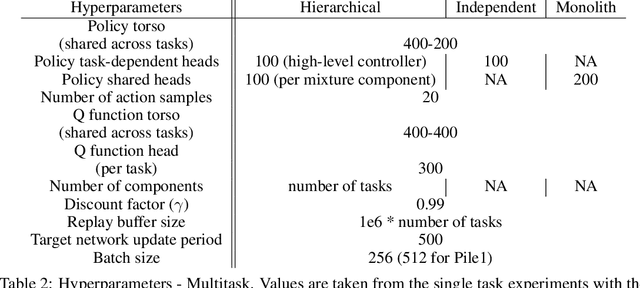
The successful application of flexible, general learning algorithms -- such as deep reinforcement learning -- to real-world robotics applications is often limited by their poor data-efficiency. Domains with more than a single dominant task of interest encourage algorithms that share partial solutions across tasks to limit the required experiment time. We develop and investigate simple hierarchical inductive biases -- in the form of structured policies -- as a mechanism for knowledge transfer across tasks in reinforcement learning (RL). To leverage the power of these structured policies we design an RL algorithm that enables stable and fast learning. We demonstrate the success of our method both in simulated robot environments (using locomotion and manipulation domains) as well as real robot experiments, demonstrating substantially better data-efficiency than competitive baselines.
Robust Reinforcement Learning for Continuous Control with Model Misspecification
Jun 18, 2019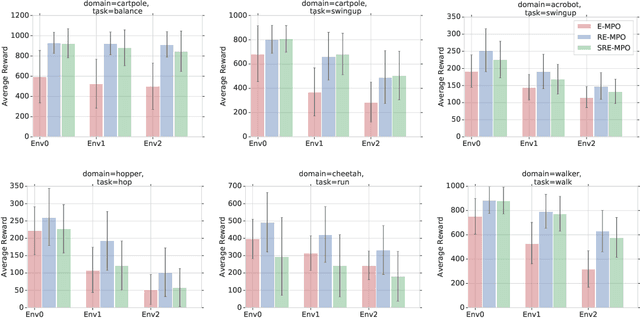

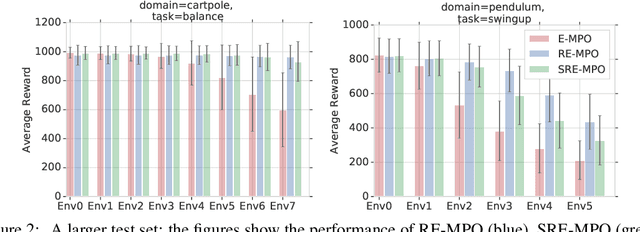
We provide a framework for incorporating robustness -- to perturbations in the transition dynamics which we refer to as model misspecification -- into continuous control Reinforcement Learning (RL) algorithms. We specifically focus on incorporating robustness into a state-of-the-art continuous control RL algorithm called Maximum a-posteriori Policy Optimization (MPO). We achieve this by learning a policy that optimizes for a worst case, entropy-regularized, expected return objective and derive a corresponding robust entropy-regularized Bellman contraction operator. In addition, we introduce a less conservative, soft-robust, entropy-regularized objective with a corresponding Bellman operator. We show that both, robust and soft-robust policies, outperform their non-robust counterparts in nine Mujoco domains with environment perturbations. Finally, we present multiple investigative experiments that provide a deeper insight into the robustness framework; including an adaptation to another continuous control RL algorithm as well as comparing this approach to domain randomization. Performance videos can be found online at https://sites.google.com/view/robust-rl.
Simultaneously Learning Vision and Feature-based Control Policies for Real-world Ball-in-a-Cup
Feb 18, 2019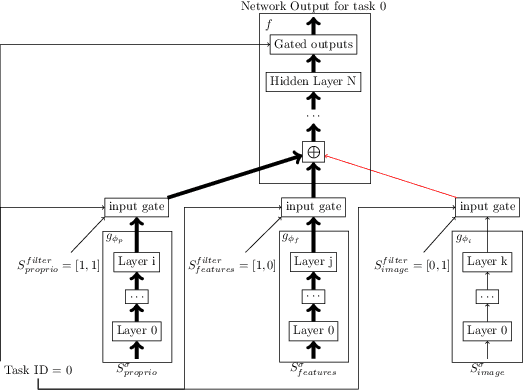

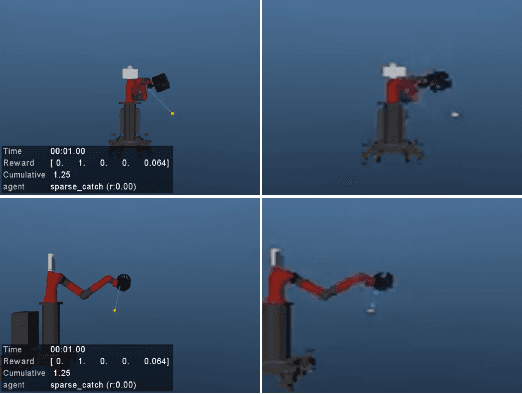

We present a method for fast training of vision based control policies on real robots. The key idea behind our method is to perform multi-task Reinforcement Learning with auxiliary tasks that differ not only in the reward to be optimized but also in the state-space in which they operate. In particular, we allow auxiliary task policies to utilize task features that are available only at training-time. This allows for fast learning of auxiliary policies, which subsequently generate good data for training the main, vision-based control policies. This method can be seen as an extension of the Scheduled Auxiliary Control (SAC-X) framework. We demonstrate the efficacy of our method by using both a simulated and real-world Ball-in-a-Cup game controlled by a robot arm. In simulation, our approach leads to significant learning speed-ups when compared to standard SAC-X. On the real robot we show that the task can be learned from-scratch, i.e., with no transfer from simulation and no imitation learning. Videos of our learned policies running on the real robot can be found at https://sites.google.com/view/rss-2019-sawyer-bic/.
Self-supervised Learning of Image Embedding for Continuous Control
Jan 03, 2019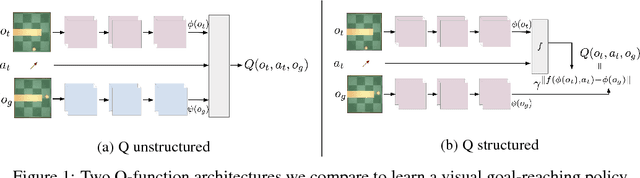
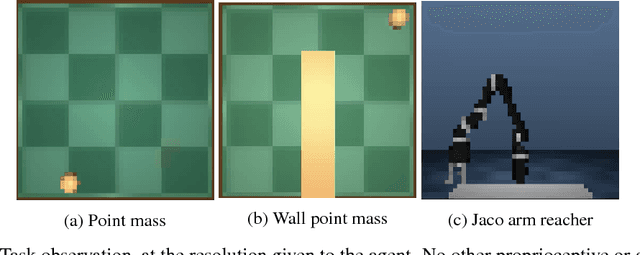
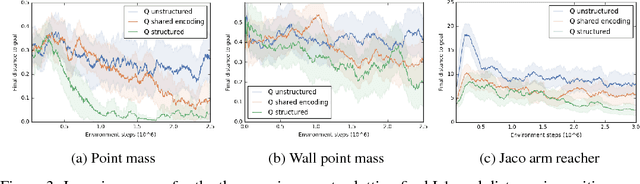
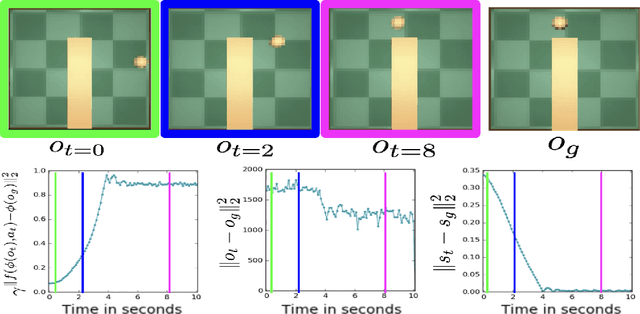
Operating directly from raw high dimensional sensory inputs like images is still a challenge for robotic control. Recently, Reinforcement Learning methods have been proposed to solve specific tasks end-to-end, from pixels to torques. However, these approaches assume the access to a specified reward which may require specialized instrumentation of the environment. Furthermore, the obtained policy and representations tend to be task specific and may not transfer well. In this work we investigate completely self-supervised learning of a general image embedding and control primitives, based on finding the shortest time to reach any state. We also introduce a new structure for the state-action value function that builds a connection between model-free and model-based methods, and improves the performance of the learning algorithm. We experimentally demonstrate these findings in three simulated robotic tasks.