 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollect & Infer -- a fresh look at data-efficient Reinforcement Learning
Aug 23, 2021This position paper proposes a fresh look at Reinforcement Learning (RL) from the perspective of data-efficiency. Data-efficient RL has gone through three major stages: pure on-line RL where every data-point is considered only once, RL with a replay buffer where additional learning is done on a portion of the experience, and finally transition memory based RL, where, conceptually, all transitions are stored and re-used in every update step. While inferring knowledge from all explicitly stored experience has lead to a tremendous gain in data-efficiency, the question of how this data is collected has been vastly understudied. We argue that data-efficiency can only be achieved through careful consideration of both aspects. We propose to make this insight explicit via a paradigm that we call 'Collect and Infer', which explicitly models RL as two separate but interconnected processes, concerned with data collection and knowledge inference respectively. We discuss implications of the paradigm, how its ideas are reflected in the literature, and how it can guide future research into data efficient RL.
On Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021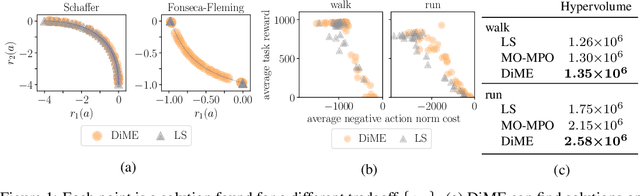
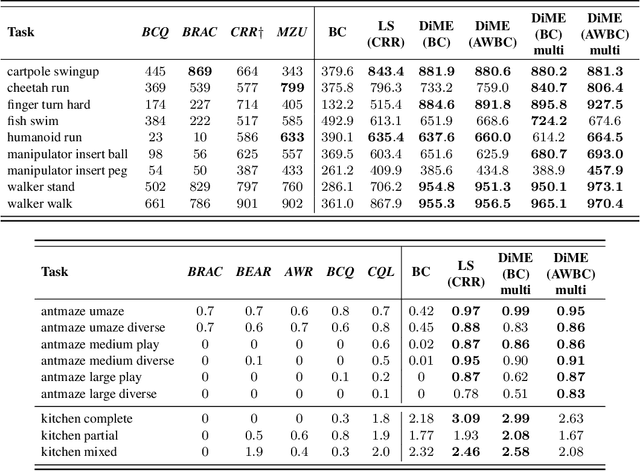
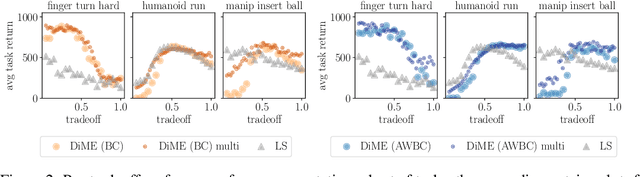

Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
Rethinking Exploration for Sample-Efficient Policy Learning
Jan 23, 2021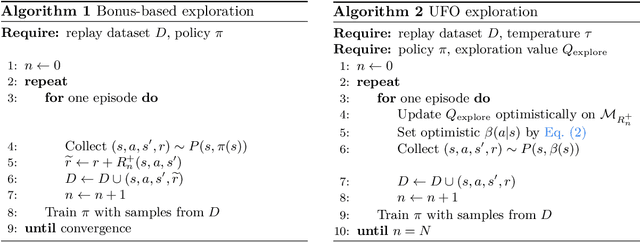
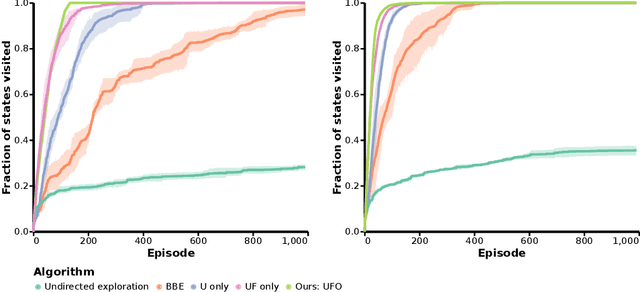
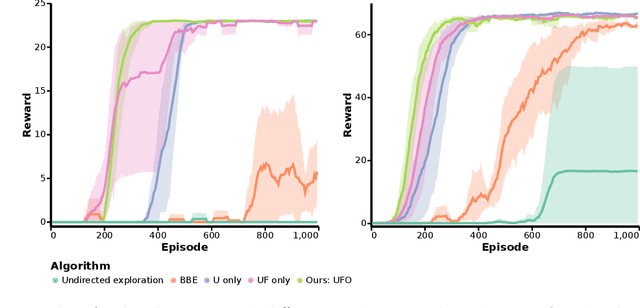
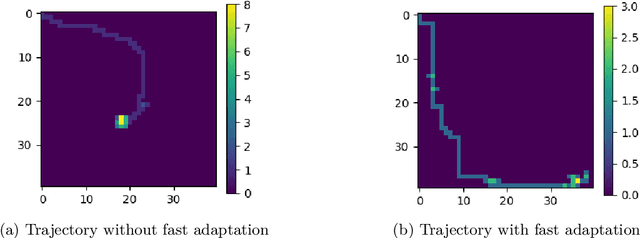
Off-policy reinforcement learning for control has made great strides in terms of performance and sample efficiency. We suggest that for many tasks the sample efficiency of modern methods is now limited by the richness of the data collected rather than the difficulty of policy fitting. We examine the reasons that directed exploration methods in the bonus-based exploration (BBE) family have not been more influential in the sample efficient control problem. Three issues have limited the applicability of BBE: bias with finite samples, slow adaptation to decaying bonuses, and lack of optimism on unseen transitions. We propose modifications to the bonus-based exploration recipe to address each of these limitations. The resulting algorithm, which we call UFO, produces policies that are Unbiased with finite samples, Fast-adapting as the exploration bonus changes, and Optimistic with respect to new transitions. We include experiments showing that rapid directed exploration is a promising direction to improve sample efficiency for control.
Representation Matters: Improving Perception and Exploration for Robotics
Nov 03, 2020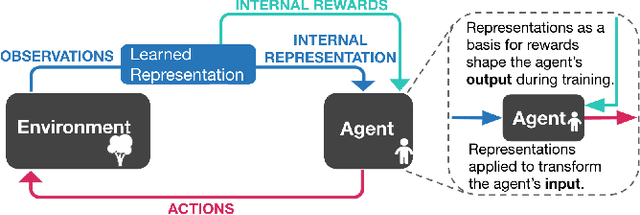
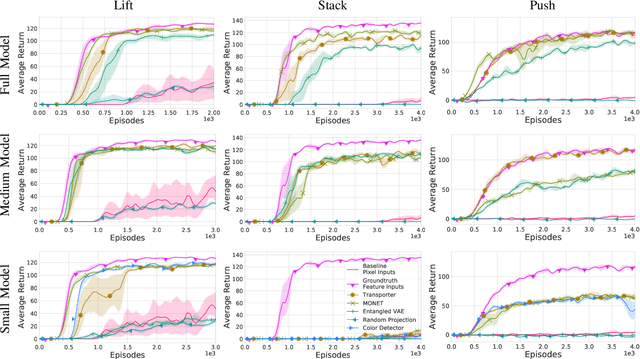
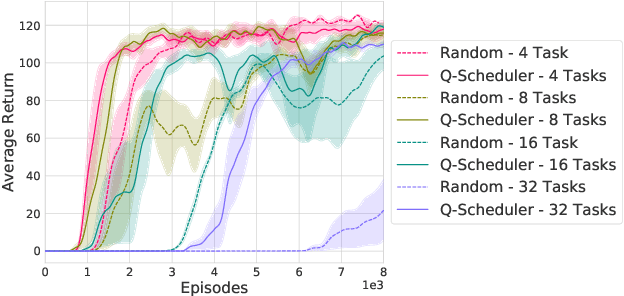

Projecting high-dimensional environment observations into lower-dimensional structured representations can considerably improve data-efficiency for reinforcement learning in domains with limited data such as robotics. Can a single generally useful representation be found? In order to answer this question, it is important to understand how the representation will be used by the agent and what properties such a 'good' representation should have. In this paper we systematically evaluate a number of common learnt and hand-engineered representations in the context of three robotics tasks: lifting, stacking and pushing of 3D blocks. The representations are evaluated in two use-cases: as input to the agent, or as a source of auxiliary tasks. Furthermore, the value of each representation is evaluated in terms of three properties: dimensionality, observability and disentanglement. We can significantly improve performance in both use-cases and demonstrate that some representations can perform commensurate to simulator states as agent inputs. Finally, our results challenge common intuitions by demonstrating that: 1) dimensionality strongly matters for task generation, but is negligible for inputs, 2) observability of task-relevant aspects mostly affects the input representation use-case, and 3) disentanglement leads to better auxiliary tasks, but has only limited benefits for input representations. This work serves as a step towards a more systematic understanding of what makes a 'good' representation for control in robotics, enabling practitioners to make more informed choices for developing new learned or hand-engineered representations.
"What, not how": Solving an under-actuated insertion task from scratch
Oct 30, 2020

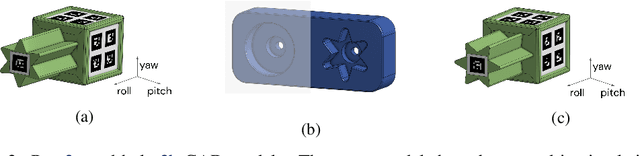
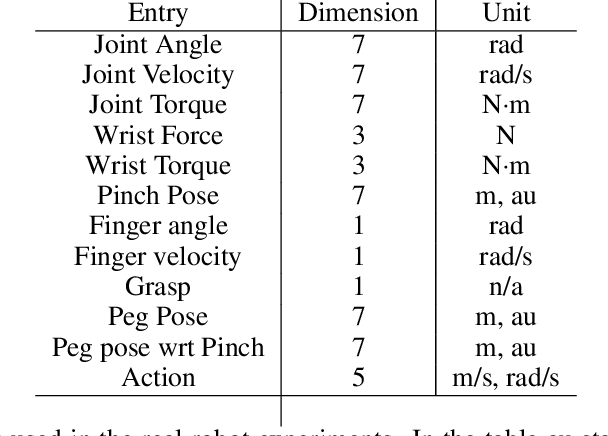
Robot manipulation requires a complex set of skills that need to be carefully combined and coordinated to solve a task. Yet, most ReinforcementLearning (RL) approaches in robotics study tasks which actually consist only of a single manipulation skill, such as grasping an object or inserting a pre-grasped object. As a result the skill ('how' to solve the task) but not the actual goal of a complete manipulation ('what' to solve) is specified. In contrast, we study a complex manipulation goal that requires an agent to learn and combine diverse manipulation skills. We propose a challenging, highly under-actuated peg-in-hole task with a free, rotational asymmetrical peg, requiring a broad range of manipulation skills. While correct peg (re-)orientation is a requirement for successful insertion, there is no reward associated with it. Hence an agent needs to understand this pre-condition and learn the skill to fulfil it. The final insertion reward is sparse, allowing freedom in the solution and leading to complex emerging behaviour not envisioned during the task design. We tackle the problem in a multi-task RL framework using Scheduled Auxiliary Control (SAC-X) combined with Regularized Hierarchical Policy Optimization (RHPO) which successfully solves the task in simulation and from scratch on a single robot where data is severely limited.
Robust Constrained Reinforcement Learning for Continuous Control with Model Misspecification
Oct 20, 2020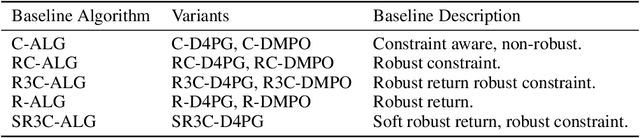
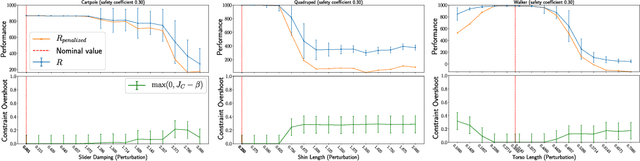
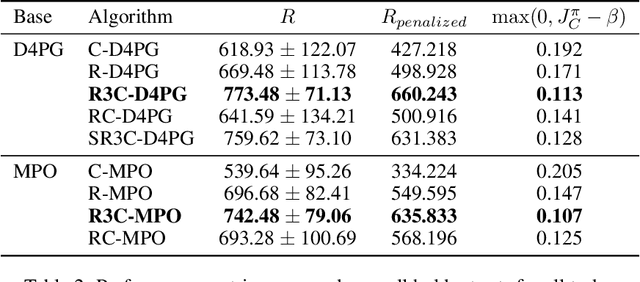
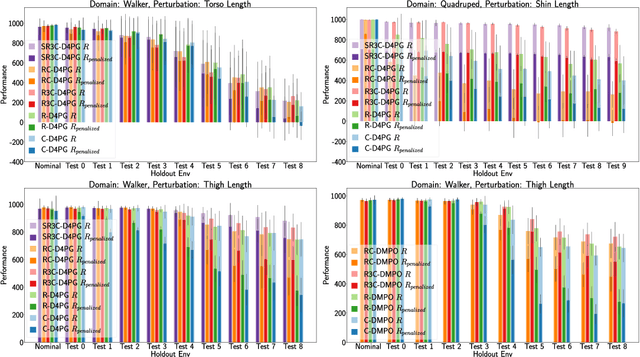
Many real-world physical control systems are required to satisfy constraints upon deployment. Furthermore, real-world systems are often subject to effects such as non-stationarity, wear-and-tear, uncalibrated sensors and so on. Such effects effectively perturb the system dynamics and can cause a policy trained successfully in one domain to perform poorly when deployed to a perturbed version of the same domain. This can affect a policy's ability to maximize future rewards as well as the extent to which it satisfies constraints. We refer to this as constrained model misspecification. We present an algorithm with theoretical guarantees that mitigates this form of misspecification, and showcase its performance in multiple Mujoco tasks from the Real World Reinforcement Learning (RWRL) suite.
Local Search for Policy Iteration in Continuous Control
Oct 12, 2020
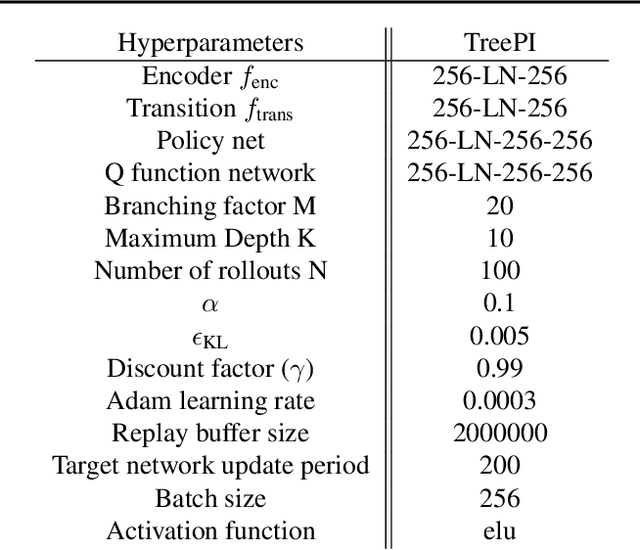
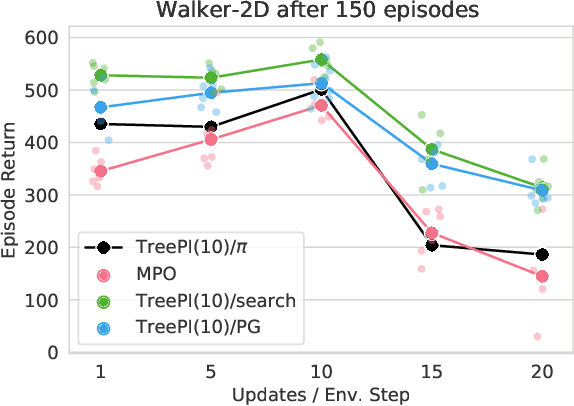

We present an algorithm for local, regularized, policy improvement in reinforcement learning (RL) that allows us to formulate model-based and model-free variants in a single framework. Our algorithm can be interpreted as a natural extension of work on KL-regularized RL and introduces a form of tree search for continuous action spaces. We demonstrate that additional computation spent on model-based policy improvement during learning can improve data efficiency, and confirm that model-based policy improvement during action selection can also be beneficial. Quantitatively, our algorithm improves data efficiency on several continuous control benchmarks (when a model is learned in parallel), and it provides significant improvements in wall-clock time in high-dimensional domains (when a ground truth model is available). The unified framework also helps us to better understand the space of model-based and model-free algorithms. In particular, we demonstrate that some benefits attributed to model-based RL can be obtained without a model, simply by utilizing more computation.
Towards General and Autonomous Learning of Core Skills: A Case Study in Locomotion
Aug 06, 2020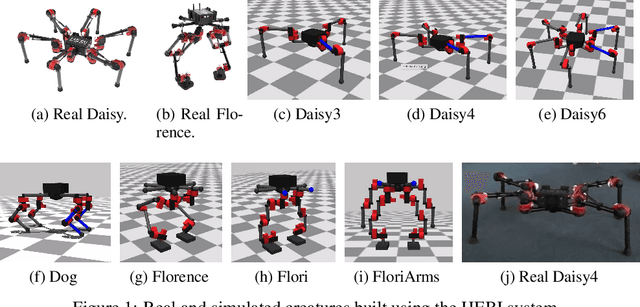
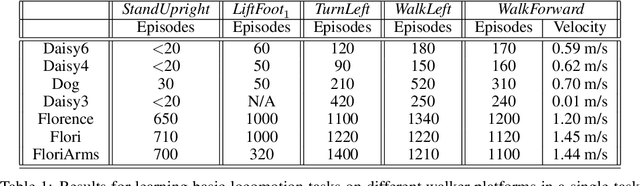
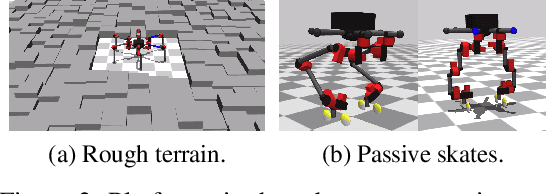

Modern Reinforcement Learning (RL) algorithms promise to solve difficult motor control problems directly from raw sensory inputs. Their attraction is due in part to the fact that they can represent a general class of methods that allow to learn a solution with a reasonably set reward and minimal prior knowledge, even in situations where it is difficult or expensive for a human expert. For RL to truly make good on this promise, however, we need algorithms and learning setups that can work across a broad range of problems with minimal problem specific adjustments or engineering. In this paper, we study this idea of generality in the locomotion domain. We develop a learning framework that can learn sophisticated locomotion behavior for a wide spectrum of legged robots, such as bipeds, tripeds, quadrupeds and hexapods, including wheeled variants. Our learning framework relies on a data-efficient, off-policy multi-task RL algorithm and a small set of reward functions that are semantically identical across robots. To underline the general applicability of the method, we keep the hyper-parameter settings and reward definitions constant across experiments and rely exclusively on on-board sensing. For nine different types of robots, including a real-world quadruped robot, we demonstrate that the same algorithm can rapidly learn diverse and reusable locomotion skills without any platform specific adjustments or additional instrumentation of the learning setup.
Data-efficient Hindsight Off-policy Option Learning
Jul 30, 2020
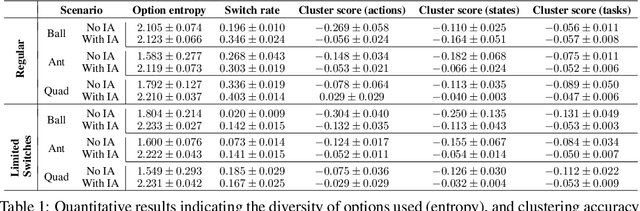


Solutions to most complex tasks can be decomposed into simpler, intermediate skills, reusable across wider ranges of problems. We follow this concept and introduce Hindsight Off-policy Options (HO2), a new algorithm for efficient and robust option learning. The algorithm relies on critic-weighted maximum likelihood estimation and an efficient dynamic programming inference procedure over off-policy trajectories. We can backpropagate through the inference procedure through time and the policy components for every time-step, making it possible to train all component's parameters off-policy, independently of the data-generating behavior policy. Experimentally, we demonstrate that HO2 outperforms competitive baselines and solves demanding robot stacking and ball-in-cup tasks from raw pixel inputs in simulation. We further compare autoregressive option policies with simple mixture policies, providing insights into the relative impact of two types of abstractions common in the options framework: action abstraction and temporal abstraction. Finally, we illustrate challenges caused by stale data in off-policy options learning and provide effective solutions.
Simple Sensor Intentions for Exploration
May 15, 2020
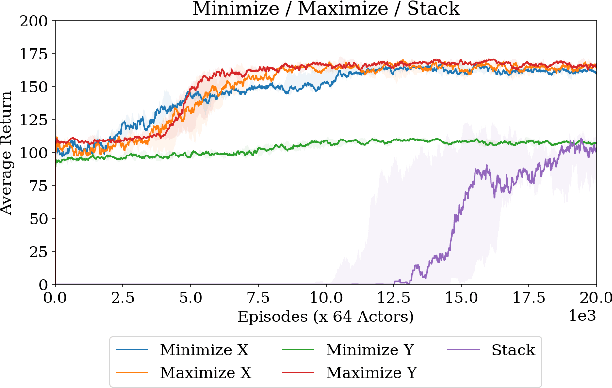
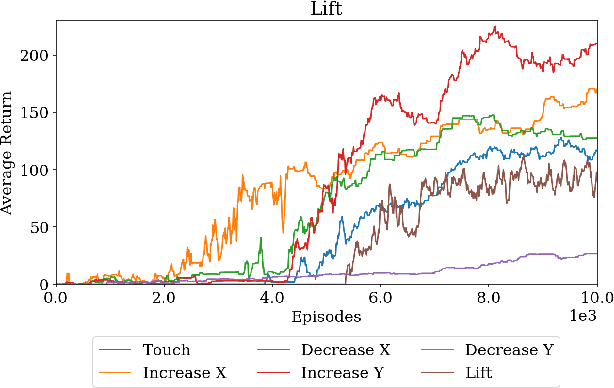
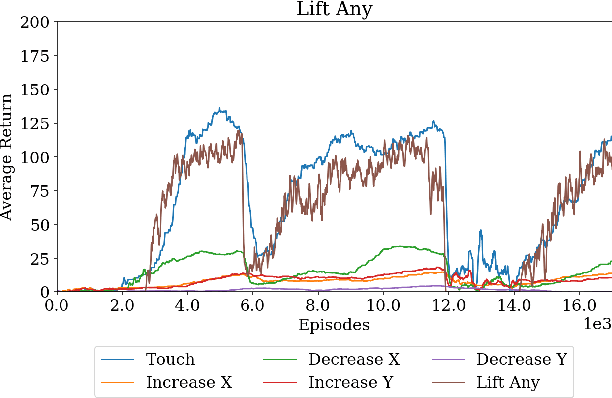
Modern reinforcement learning algorithms can learn solutions to increasingly difficult control problems while at the same time reduce the amount of prior knowledge needed for their application. One of the remaining challenges is the definition of reward schemes that appropriately facilitate exploration without biasing the solution in undesirable ways, and that can be implemented on real robotic systems without expensive instrumentation. In this paper we focus on a setting in which goal tasks are defined via simple sparse rewards, and exploration is facilitated via agent-internal auxiliary tasks. We introduce the idea of simple sensor intentions (SSIs) as a generic way to define auxiliary tasks. SSIs reduce the amount of prior knowledge that is required to define suitable rewards. They can further be computed directly from raw sensor streams and thus do not require expensive and possibly brittle state estimation on real systems. We demonstrate that a learning system based on these rewards can solve complex robotic tasks in simulation and in real world settings. In particular, we show that a real robotic arm can learn to grasp and lift and solve a Ball-in-a-Cup task from scratch, when only raw sensor streams are used for both controller input and in the auxiliary reward definition.