 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskBit: Embedding-free Image Generation via Bit Tokens
Sep 24, 2024



Masked transformer models for class-conditional image generation have become a compelling alternative to diffusion models. Typically comprising two stages - an initial VQGAN model for transitioning between latent space and image space, and a subsequent Transformer model for image generation within latent space - these frameworks offer promising avenues for image synthesis. In this study, we present two primary contributions: Firstly, an empirical and systematic examination of VQGANs, leading to a modernized VQGAN. Secondly, a novel embedding-free generation network operating directly on bit tokens - a binary quantized representation of tokens with rich semantics. The first contribution furnishes a transparent, reproducible, and high-performing VQGAN model, enhancing accessibility and matching the performance of current state-of-the-art methods while revealing previously undisclosed details. The second contribution demonstrates that embedding-free image generation using bit tokens achieves a new state-of-the-art FID of 1.52 on the ImageNet 256x256 benchmark, with a compact generator model of mere 305M parameters.
MICDrop: Masking Image and Depth Features via Complementary Dropout for Domain-Adaptive Semantic Segmentation
Aug 29, 2024



Unsupervised Domain Adaptation (UDA) is the task of bridging the domain gap between a labeled source domain, e.g., synthetic data, and an unlabeled target domain. We observe that current UDA methods show inferior results on fine structures and tend to oversegment objects with ambiguous appearance. To address these shortcomings, we propose to leverage geometric information, i.e., depth predictions, as depth discontinuities often coincide with segmentation boundaries. We show that naively incorporating depth into current UDA methods does not fully exploit the potential of this complementary information. To this end, we present MICDrop, which learns a joint feature representation by masking image encoder features while inversely masking depth encoder features. With this simple yet effective complementary masking strategy, we enforce the use of both modalities when learning the joint feature representation. To aid this process, we propose a feature fusion module to improve both global as well as local information sharing while being robust to errors in the depth predictions. We show that our method can be plugged into various recent UDA methods and consistently improve results across standard UDA benchmarks, obtaining new state-of-the-art performances.
An Image is Worth 32 Tokens for Reconstruction and Generation
Jun 11, 2024



Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 x 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64x, leading to 410x faster generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
The Shape of Money Laundering: Subgraph Representation Learning on the Blockchain with the Elliptic2 Dataset
May 01, 2024



Subgraph representation learning is a technique for analyzing local structures (or shapes) within complex networks. Enabled by recent developments in scalable Graph Neural Networks (GNNs), this approach encodes relational information at a subgroup level (multiple connected nodes) rather than at a node level of abstraction. We posit that certain domain applications, such as anti-money laundering (AML), are inherently subgraph problems and mainstream graph techniques have been operating at a suboptimal level of abstraction. This is due in part to the scarcity of annotated datasets of real-world size and complexity, as well as the lack of software tools for managing subgraph GNN workflows at scale. To enable work in fundamental algorithms as well as domain applications in AML and beyond, we introduce Elliptic2, a large graph dataset containing 122K labeled subgraphs of Bitcoin clusters within a background graph consisting of 49M node clusters and 196M edge transactions. The dataset provides subgraphs known to be linked to illicit activity for learning the set of "shapes" that money laundering exhibits in cryptocurrency and accurately classifying new criminal activity. Along with the dataset we share our graph techniques, software tooling, promising early experimental results, and new domain insights already gleaned from this approach. Taken together, we find immediate practical value in this approach and the potential for a new standard in anti-money laundering and forensic analytics in cryptocurrencies and other financial networks.
DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation
Mar 23, 2022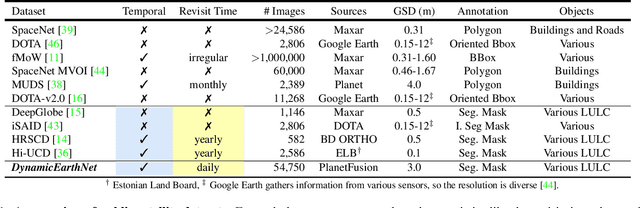
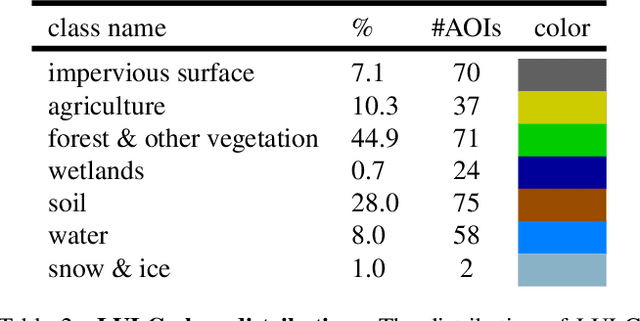

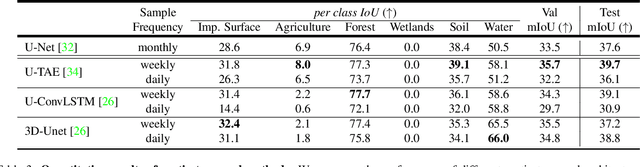
Earth observation is a fundamental tool for monitoring the evolution of land use in specific areas of interest. Observing and precisely defining change, in this context, requires both time-series data and pixel-wise segmentations. To that end, we propose the DynamicEarthNet dataset that consists of daily, multi-spectral satellite observations of 75 selected areas of interest distributed over the globe with imagery from Planet Labs. These observations are paired with pixel-wise monthly semantic segmentation labels of 7 land use and land cover (LULC) classes. DynamicEarthNet is the first dataset that provides this unique combination of daily measurements and high-quality labels. In our experiments, we compare several established baselines that either utilize the daily observations as additional training data (semi-supervised learning) or multiple observations at once (spatio-temporal learning) as a point of reference for future research. Finally, we propose a new evaluation metric SCS that addresses the specific challenges associated with time-series semantic change segmentation. The data is available at: https://mediatum.ub.tum.de/1650201.
DeepLab2: A TensorFlow Library for Deep Labeling
Jun 17, 2021


DeepLab2 is a TensorFlow library for deep labeling, aiming to provide a state-of-the-art and easy-to-use TensorFlow codebase for general dense pixel prediction problems in computer vision. DeepLab2 includes all our recently developed DeepLab model variants with pretrained checkpoints as well as model training and evaluation code, allowing the community to reproduce and further improve upon the state-of-art systems. To showcase the effectiveness of DeepLab2, our Panoptic-DeepLab employing Axial-SWideRNet as network backbone achieves 68.0% PQ or 83.5% mIoU on Cityscaspes validation set, with only single-scale inference and ImageNet-1K pretrained checkpoints. We hope that publicly sharing our library could facilitate future research on dense pixel labeling tasks and envision new applications of this technology. Code is made publicly available at \url{https://github.com/google-research/deeplab2}.
4D Panoptic LiDAR Segmentation
Feb 24, 2021
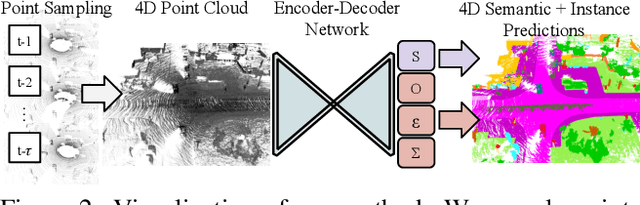
Temporal semantic scene understanding is critical for self-driving cars or robots operating in dynamic environments. In this paper, we propose 4D panoptic LiDAR segmentation to assign a semantic class and a temporally-consistent instance ID to a sequence of 3D points. To this end, we present an approach and a point-centric evaluation metric. Our approach determines a semantic class for every point while modeling object instances as probability distributions in the 4D spatio-temporal domain. We process multiple point clouds in parallel and resolve point-to-instance associations, effectively alleviating the need for explicit temporal data association. Inspired by recent advances in benchmarking of multi-object tracking, we propose to adopt a new evaluation metric that separates the semantic and point-to-instance association aspects of the task. With this work, we aim at paving the road for future developments of temporal LiDAR panoptic perception.
STEP: Segmenting and Tracking Every Pixel
Feb 23, 2021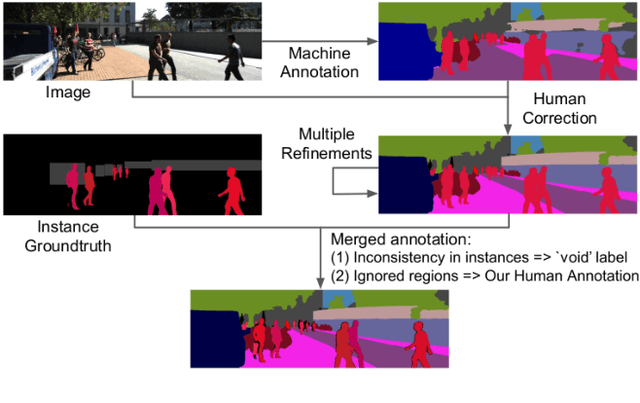
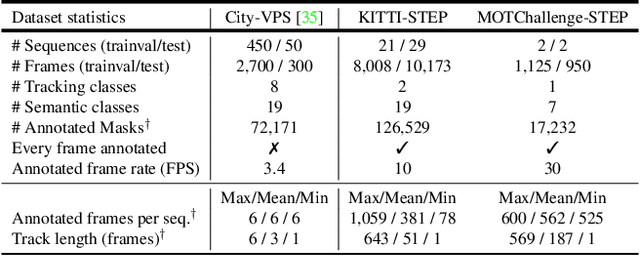


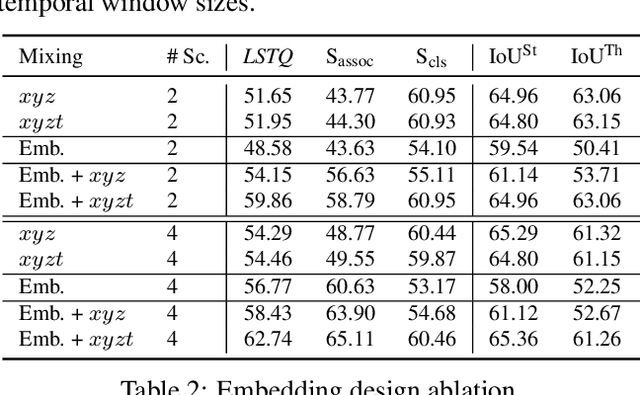
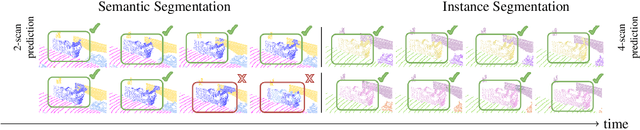
In this paper, we tackle video panoptic segmentation, a task that requires assigning semantic classes and track identities to all pixels in a video. To study this important problem in a setting that requires a continuous interpretation of sensory data, we present a new benchmark: Segmenting and Tracking Every Pixel (STEP), encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP together with a new evaluation metric. Our work is the first that targets this task in a real-world setting that requires dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. By contrast, our datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking. For measuring the performance, we propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is suitable for evaluating sequences of arbitrary length. We will make our datasets, metric, and baselines publicly available.
Single-Shot Panoptic Segmentation
Nov 02, 2019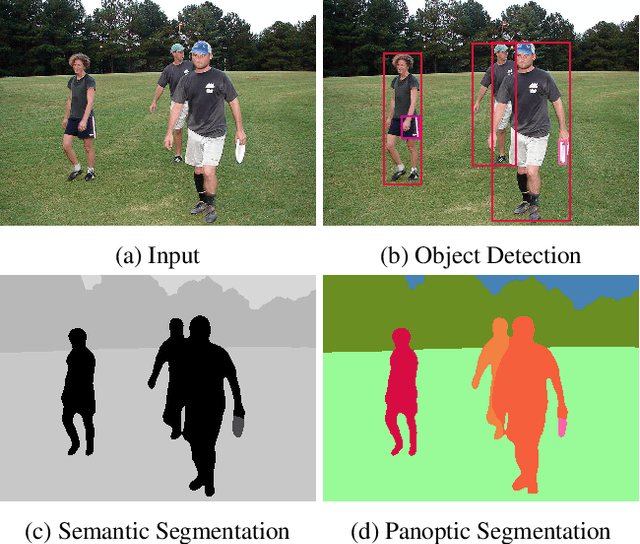
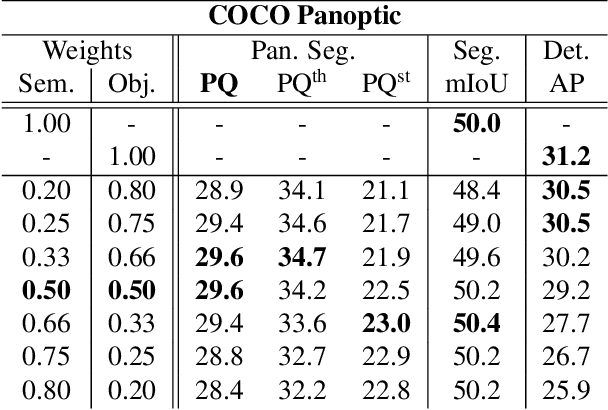
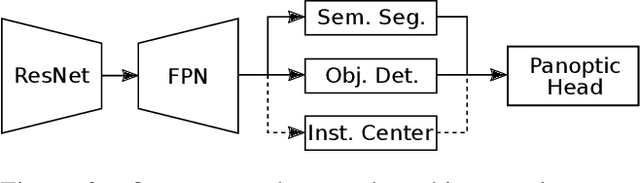
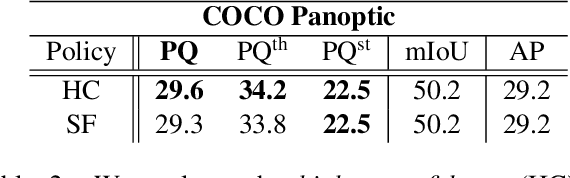
We present a novel end-to-end single-shot method that segments countable object instances (things) as well as background regions (stuff) into a non-overlapping panoptic segmentation at almost video frame rate. Current state-of-the-art methods are far from reaching video frame rate and mostly rely on merging instance segmentation with semantic background segmentation. Our approach relaxes this requirement by using an object detector but is still able to resolve inter- and intra-class overlaps to achieve a non-overlapping segmentation. On top of a shared encoder-decoder backbone, we utilize multiple branches for semantic segmentation, object detection, and instance center prediction. Finally, our panoptic head combines all outputs into a panoptic segmentation and can even handle conflicting predictions between branches as well as certain false predictions. Our network achieves 32.6% PQ on MS-COCO at 21.8 FPS, opening up panoptic segmentation to a broader field of applications.
Anti-Money Laundering in Bitcoin: Experimenting with Graph Convolutional Networks for Financial Forensics
Jul 31, 2019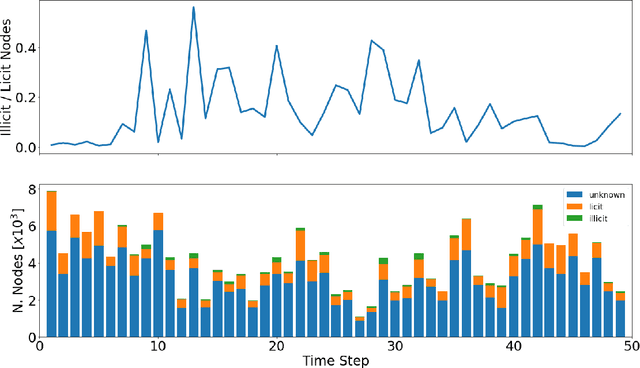
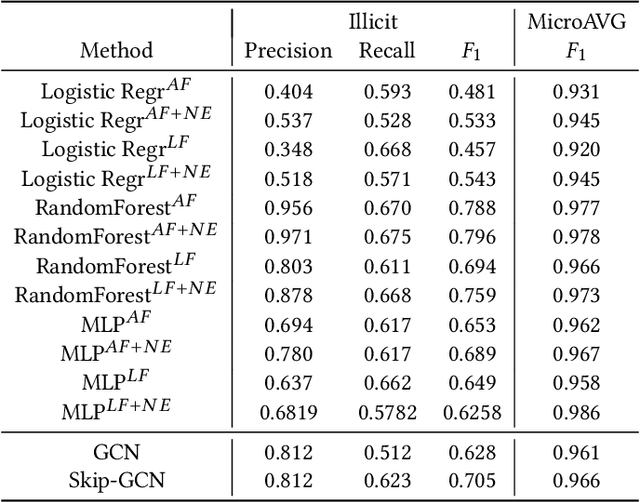
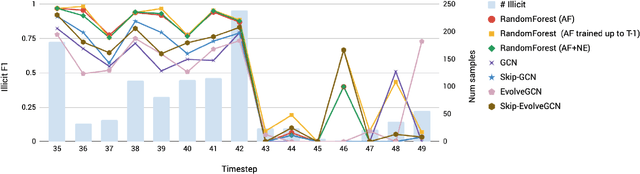

Anti-money laundering (AML) regulations play a critical role in safeguarding financial systems, but bear high costs for institutions and drive financial exclusion for those on the socioeconomic and international margins. The advent of cryptocurrency has introduced an intriguing paradox: pseudonymity allows criminals to hide in plain sight, but open data gives more power to investigators and enables the crowdsourcing of forensic analysis. Meanwhile advances in learning algorithms show great promise for the AML toolkit. In this workshop tutorial, we motivate the opportunity to reconcile the cause of safety with that of financial inclusion. We contribute the Elliptic Data Set, a time series graph of over 200K Bitcoin transactions (nodes), 234K directed payment flows (edges), and 166 node features, including ones based on non-public data; to our knowledge, this is the largest labelled transaction data set publicly available in any cryptocurrency. We share results from a binary classification task predicting illicit transactions using variations of Logistic Regression (LR), Random Forest (RF), Multilayer Perceptrons (MLP), and Graph Convolutional Networks (GCN), with GCN being of special interest as an emergent new method for capturing relational information. The results show the superiority of Random Forest (RF), but also invite algorithmic work to combine the respective powers of RF and graph methods. Lastly, we consider visualization for analysis and explainability, which is difficult given the size and dynamism of real-world transaction graphs, and we offer a simple prototype capable of navigating the graph and observing model performance on illicit activity over time. With this tutorial and data set, we hope to a) invite feedback in support of our ongoing inquiry, and b) inspire others to work on this societally important challenge.