 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Memory: Fixed-Size Recurrent State for Long-Horizon Transformers
May 26, 2026Transformers process images and videos by flattening space and time into long token sequences. While attention and KV caching preserve past features, their memory grows with sequence length and they lack an explicit, persistent spatial state, making long-horizon video understanding and occlusion-sensitive reasoning difficult. We propose Tensor Memory, a lightweight module that augments Transformer blocks with a fixed-size recurrent 3D memory tensor: tokens write into a voxel grid via a differentiable soft write that deposits content as a Gaussian-weighted volume around a predicted continuous 3D location, the memory is updated with an efficient local interaction operator and gated recurrent dynamics, and tokens read back context via continuous sampling with gated residual fusion. Because the memory tensor has a constant size, Tensor Memory decouples state capacity from input length while preserving a spatial inductive bias. We evaluate the module on standard language, image, and video benchmarks and on a controlled toy diagnostic suite designed to isolate when persistent state is beneficial; it integrates with standard Transformer training pipelines and can be attached to or removed from existing blocks without other architectural changes.
Hurwitz Quaternion Multiplicative Quantization for KV Cache Compression
May 26, 2026We propose \textbf{Hurwitz Quaternion Multiplicative Quantization (HQMQ)}, a \textbf{calibration-free} method for KV cache compression of large language models. HQMQ treats each 4-element chunk of K or V as a quaternion and quantizes its unit direction to the \emph{product} $q_p \cdot q_s$, where $q_p$ ranges over the 24-element Hurwitz group $2T$ (the 24 vertices of the 24-cell on $S^3$, pairwise angle $60^\circ$) and $q_s$ ranges over a per-(layer, head) secondary codebook of $S$ \emph{random} unit quaternions. The multiplicative composition yields $24S$ effective codewords at $S$ stored parameters; random initialization suffices because left-multiplication is an $S^3$ isometry, so seeded codebooks vary in end-task ppl by $<1.5\%$. A per-batch median-multiplier outlier extraction step ($C{=}3$, no calibration) handles modern outlier-heavy architectures. We evaluate on five modern open models: Mistral-7B (dense MHA), Llama-3-8B and Qwen2.5-7B and Qwen3-8B (dense GQA), and gpt-oss-20b (sparse MoE). On Mistral-7B and Qwen3-8B, HQMQ matches fp16 within $0.02$--$0.03$ ppl points at $\sim$5 bits. On Qwen2.5-7B and Qwen3-8B, where naive int4 collapses to $10^4{+}$ ppl, HQMQ + Med3$\times$ recovers fp16 quality within $0.02$--$0.10$ ppl points at $\sim$5 bits. HQMQ Pareto-dominates naive int by $3$--$1900\times$ at matched bits across all five models, and downstream zero-shot accuracy matches fp16 at $3.79$ bits on Mistral. Against the strongest calibrated KV-quantization baseline, HQMQ at $3.79$ bits matches KIVI-4 ($\sim 4.5$ bits) within ${\sim}1$ pt on CoQA, $0.6$ pts on TruthfulQA, and $2.3$ pts on GSM8K, at $16\%$ fewer bits and without a calibration pass. At the storage level, HQMQ delivers up to $5.05\times$ KV compression, shrinking a Llama-3-70B 128k-context cache from 43 GB to 8.5 GB.
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Small Models, Smarter Learning: The Power of Joint Task Training
May 23, 2025



The ability of a model to learn a task depends strongly on both the task difficulty and the model size. We aim to understand how task difficulty relates to the minimum number of parameters required for learning specific tasks in small transformer models. Our study focuses on the ListOps dataset, which consists of nested mathematical operations. We gradually increase task difficulty by introducing new operations or combinations of operations into the training data. We observe that sum modulo n is the hardest to learn. Curiously, when combined with other operations such as maximum and median, the sum operation becomes easier to learn and requires fewer parameters. We show that joint training not only improves performance but also leads to qualitatively different model behavior. We show evidence that models trained only on SUM might be memorizing and fail to capture the number structure in the embeddings. In contrast, models trained on a mixture of SUM and other operations exhibit number-like representations in the embedding space, and a strong ability to distinguish parity. Furthermore, the SUM-only model relies more heavily on its feedforward layers, while the jointly trained model activates the attention mechanism more. Finally, we show that learning pure SUM can be induced in models below the learning threshold of pure SUM, by pretraining them on MAX+MED. Our findings indicate that emergent abilities in language models depend not only on model size, but also the training curriculum.
AutoDOViz: Human-Centered Automation for Decision Optimization
Feb 19, 2023



We present AutoDOViz, an interactive user interface for automated decision optimization (AutoDO) using reinforcement learning (RL). Decision optimization (DO) has classically being practiced by dedicated DO researchers where experts need to spend long periods of time fine tuning a solution through trial-and-error. AutoML pipeline search has sought to make it easier for a data scientist to find the best machine learning pipeline by leveraging automation to search and tune the solution. More recently, these advances have been applied to the domain of AutoDO, with a similar goal to find the best reinforcement learning pipeline through algorithm selection and parameter tuning. However, Decision Optimization requires significantly more complex problem specification when compared to an ML problem. AutoDOViz seeks to lower the barrier of entry for data scientists in problem specification for reinforcement learning problems, leverage the benefits of AutoDO algorithms for RL pipeline search and finally, create visualizations and policy insights in order to facilitate the typical interactive nature when communicating problem formulation and solution proposals between DO experts and domain experts. In this paper, we report our findings from semi-structured expert interviews with DO practitioners as well as business consultants, leading to design requirements for human-centered automation for DO with RL. We evaluate a system implementation with data scientists and find that they are significantly more open to engage in DO after using our proposed solution. AutoDOViz further increases trust in RL agent models and makes the automated training and evaluation process more comprehensible. As shown for other automation in ML tasks, we also conclude automation of RL for DO can benefit from user and vice-versa when the interface promotes human-in-the-loop.
FiberStars: Visual Comparison of Diffusion Tractography Data between Multiple Subjects
May 16, 2020
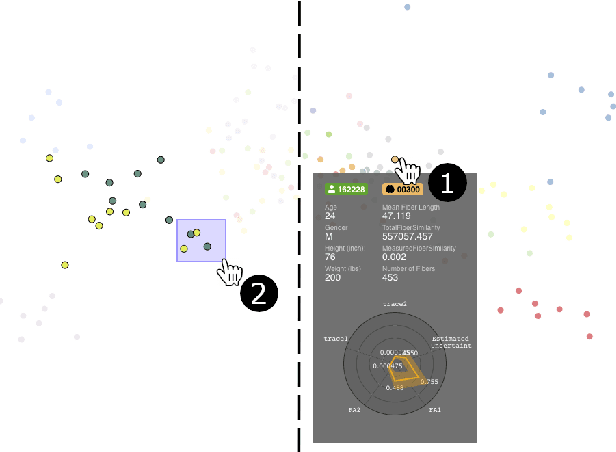


Tractography from high-dimensional diffusion magnetic resonance imaging (dMRI) data allows brain's structural connectivity analysis. Recent dMRI studies aim to compare connectivity patterns across thousands of subjects to understand subtle abnormalities in brain's white matter connectivity across disease populations. Besides connectivity differences, researchers are also interested in investigating distributions of biologically sensitive dMRI derived metrics across subject groups. Existing software products focus solely on the anatomy or are not intuitive and restrict the comparison of multiple subjects. In this paper, we present the design and implementation of FiberStars, a visual analysis tool for tractography data that allows the interactive and scalable visualization of brain fiber clusters in 2D and 3D. With FiberStars, researchers can analyze and compare multiple subjects in large collections of brain fibers. To evaluate the usability of our software, we performed a quantitative user study. We asked non-experts to find patterns in a large tractography dataset with either FiberStars or AFQ-Browser, an existing dMRI exploration tool. Our results show that participants using FiberStars can navigate extensive collections of tractography faster and more accurately. We discuss our findings and provide an analysis of the requirements for comparative visualizations of tractography data. All our research, software, and results are available openly.
AutoAIViz: Opening the Blackbox of Automated Artificial Intelligence with Conditional Parallel Coordinates
Jan 17, 2020
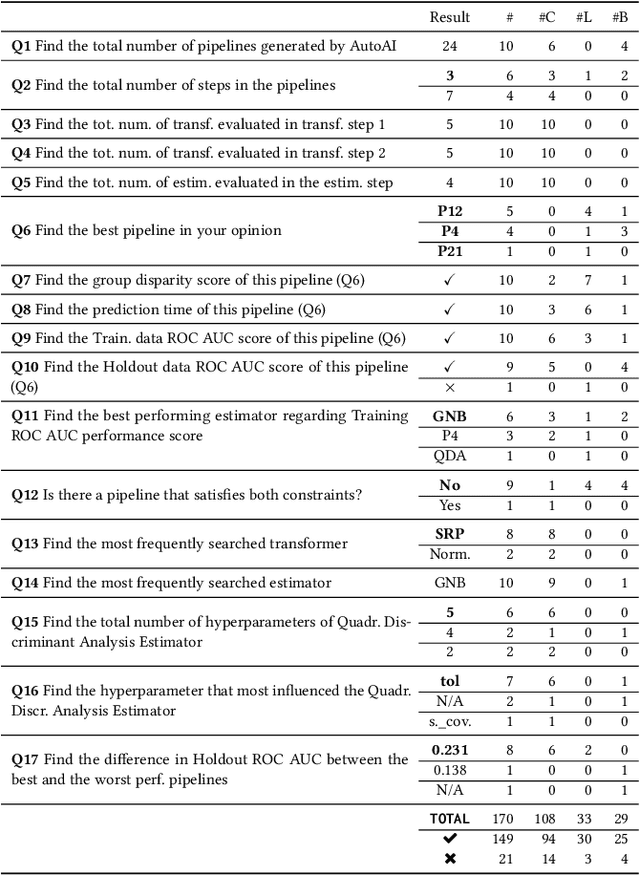
Artificial Intelligence (AI) can now automate the algorithm selection, feature engineering, and hyperparameter tuning steps in a machine learning workflow. Commonly known as AutoML or AutoAI, these technologies aim to relieve data scientists from the tedious manual work. However, today's AutoAI systems often present only limited to no information about the process of how they select and generate model results. Thus, users often do not understand the process, neither do they trust the outputs. In this short paper, we provide a first user evaluation by 10 data scientists of an experimental system, AutoAIViz, that aims to visualize AutoAI's model generation process. We find that the proposed system helps users to complete the data science tasks, and increases their understanding, toward the goal of increasing trust in the AutoAI system.
Anti-Money Laundering in Bitcoin: Experimenting with Graph Convolutional Networks for Financial Forensics
Jul 31, 2019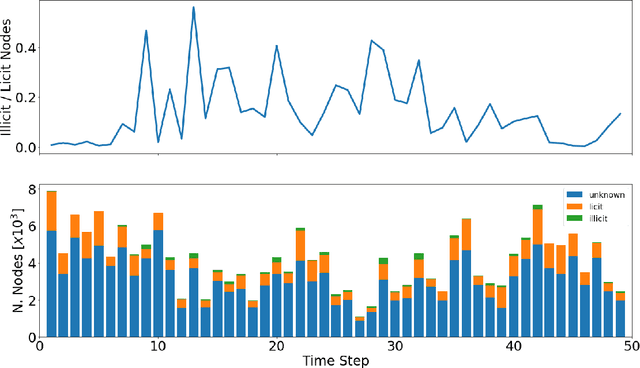
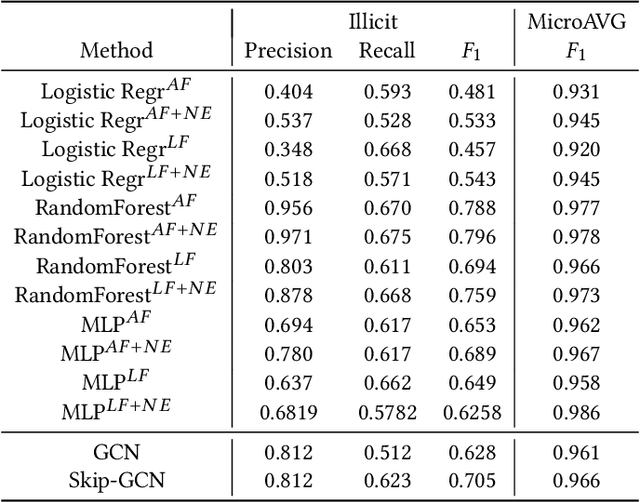
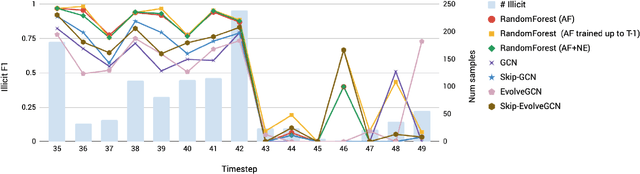

Anti-money laundering (AML) regulations play a critical role in safeguarding financial systems, but bear high costs for institutions and drive financial exclusion for those on the socioeconomic and international margins. The advent of cryptocurrency has introduced an intriguing paradox: pseudonymity allows criminals to hide in plain sight, but open data gives more power to investigators and enables the crowdsourcing of forensic analysis. Meanwhile advances in learning algorithms show great promise for the AML toolkit. In this workshop tutorial, we motivate the opportunity to reconcile the cause of safety with that of financial inclusion. We contribute the Elliptic Data Set, a time series graph of over 200K Bitcoin transactions (nodes), 234K directed payment flows (edges), and 166 node features, including ones based on non-public data; to our knowledge, this is the largest labelled transaction data set publicly available in any cryptocurrency. We share results from a binary classification task predicting illicit transactions using variations of Logistic Regression (LR), Random Forest (RF), Multilayer Perceptrons (MLP), and Graph Convolutional Networks (GCN), with GCN being of special interest as an emergent new method for capturing relational information. The results show the superiority of Random Forest (RF), but also invite algorithmic work to combine the respective powers of RF and graph methods. Lastly, we consider visualization for analysis and explainability, which is difficult given the size and dynamism of real-world transaction graphs, and we offer a simple prototype capable of navigating the graph and observing model performance on illicit activity over time. With this tutorial and data set, we hope to a) invite feedback in support of our ongoing inquiry, and b) inspire others to work on this societally important challenge.