 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthCues: Evaluating Monocular Depth Perception in Large Vision Models
Nov 26, 2024



Large-scale pre-trained vision models are becoming increasingly prevalent, offering expressive and generalizable visual representations that benefit various downstream tasks. Recent studies on the emergent properties of these models have revealed their high-level geometric understanding, in particular in the context of depth perception. However, it remains unclear how depth perception arises in these models without explicit depth supervision provided during pre-training. To investigate this, we examine whether the monocular depth cues, similar to those used by the human visual system, emerge in these models. We introduce a new benchmark, DepthCues, designed to evaluate depth cue understanding, and present findings across 20 diverse and representative pre-trained vision models. Our analysis shows that human-like depth cues emerge in more recent larger models. We also explore enhancing depth perception in large vision models by fine-tuning on DepthCues, and find that even without dense depth supervision, this improves depth estimation. To support further research, our benchmark and evaluation code will be made publicly available for studying depth perception in vision models.
Enhancing 2D Representation Learning with a 3D Prior
Jun 04, 2024



Learning robust and effective representations of visual data is a fundamental task in computer vision. Traditionally, this is achieved by training models with labeled data which can be expensive to obtain. Self-supervised learning attempts to circumvent the requirement for labeled data by learning representations from raw unlabeled visual data alone. However, unlike humans who obtain rich 3D information from their binocular vision and through motion, the majority of current self-supervised methods are tasked with learning from monocular 2D image collections. This is noteworthy as it has been demonstrated that shape-centric visual processing is more robust compared to texture-biased automated methods. Inspired by this, we propose a new approach for strengthening existing self-supervised methods by explicitly enforcing a strong 3D structural prior directly into the model during training. Through experiments, across a range of datasets, we demonstrate that our 3D aware representations are more robust compared to conventional self-supervised baselines.
SAOR: Single-View Articulated Object Reconstruction
Mar 23, 2023We introduce SAOR, a novel approach for estimating the 3D shape, texture, and viewpoint of an articulated object from a single image captured in the wild. Unlike prior approaches that rely on pre-defined category-specific 3D templates or tailored 3D skeletons, SAOR learns to articulate shapes from single-view image collections with a skeleton-free part-based model without requiring any 3D object shape priors. To prevent ill-posed solutions, we propose a cross-instance consistency loss that exploits disentangled object shape deformation and articulation. This is helped by a new silhouette-based sampling mechanism to enhance viewpoint diversity during training. Our method only requires estimated object silhouettes and relative depth maps from off-the-shelf pre-trained networks during training. At inference time, given a single-view image, it efficiently outputs an explicit mesh representation. We obtain improved qualitative and quantitative results on challenging quadruped animals compared to relevant existing work.
Demystifying Unsupervised Semantic Correspondence Estimation
Jul 11, 2022
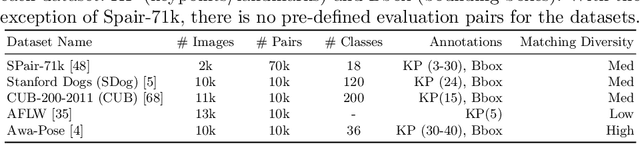

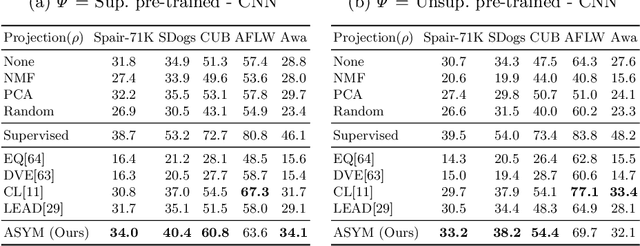
We explore semantic correspondence estimation through the lens of unsupervised learning. We thoroughly evaluate several recently proposed unsupervised methods across multiple challenging datasets using a standardized evaluation protocol where we vary factors such as the backbone architecture, the pre-training strategy, and the pre-training and finetuning datasets. To better understand the failure modes of these methods, and in order to provide a clearer path for improvement, we provide a new diagnostic framework along with a new performance metric that is better suited to the semantic matching task. Finally, we introduce a new unsupervised correspondence approach which utilizes the strength of pre-trained features while encouraging better matches during training. This results in significantly better matching performance compared to current state-of-the-art methods.
4D Panoptic LiDAR Segmentation
Feb 24, 2021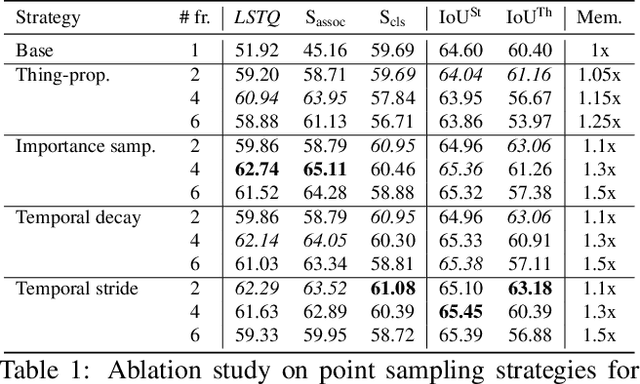
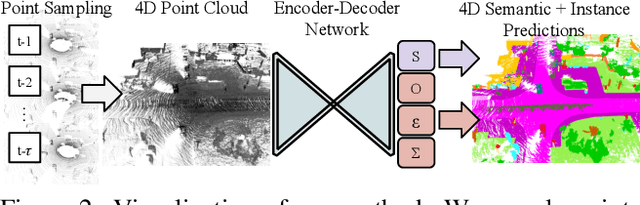
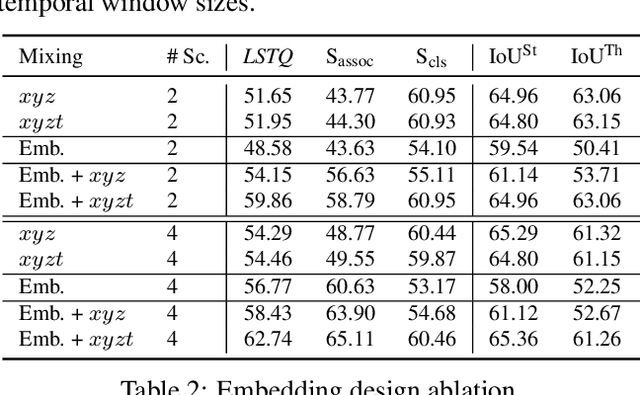
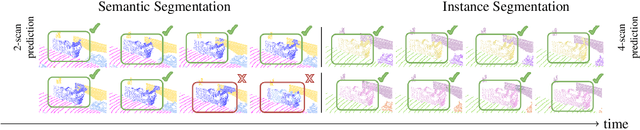
Temporal semantic scene understanding is critical for self-driving cars or robots operating in dynamic environments. In this paper, we propose 4D panoptic LiDAR segmentation to assign a semantic class and a temporally-consistent instance ID to a sequence of 3D points. To this end, we present an approach and a point-centric evaluation metric. Our approach determines a semantic class for every point while modeling object instances as probability distributions in the 4D spatio-temporal domain. We process multiple point clouds in parallel and resolve point-to-instance associations, effectively alleviating the need for explicit temporal data association. Inspired by recent advances in benchmarking of multi-object tracking, we propose to adopt a new evaluation metric that separates the semantic and point-to-instance association aspects of the task. With this work, we aim at paving the road for future developments of temporal LiDAR panoptic perception.
Unsupervised Dense Shape Correspondence using Heat Kernels
Oct 23, 2020
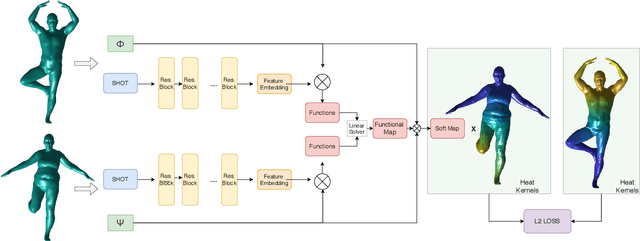
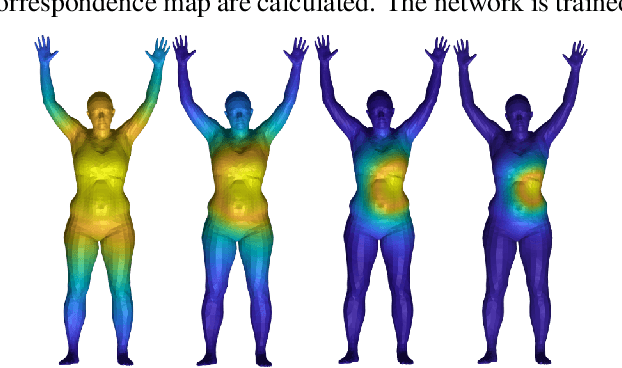
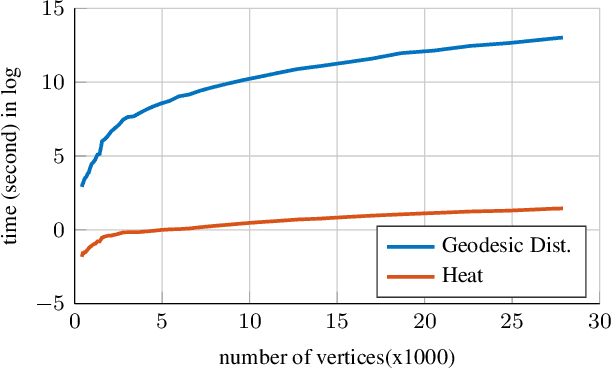
In this work, we propose an unsupervised method for learning dense correspondences between shapes using a recent deep functional map framework. Instead of depending on ground-truth correspondences or the computationally expensive geodesic distances, we use heat kernels. These can be computed quickly during training as the supervisor signal. Moreover, we propose a curriculum learning strategy using different heat diffusion times which provide different levels of difficulty during optimization without any sampling mechanism or hard example mining. We present the results of our method on different benchmarks which have various challenges like partiality, topological noise and different connectivity.
Multi Modal Convolutional Neural Networks for Brain Tumor Segmentation
Sep 20, 2018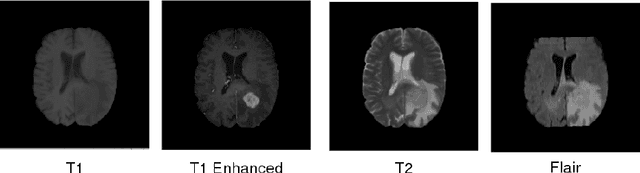

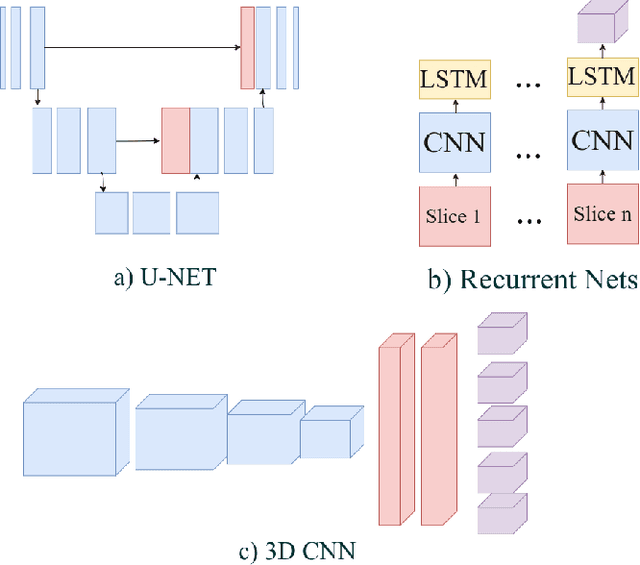
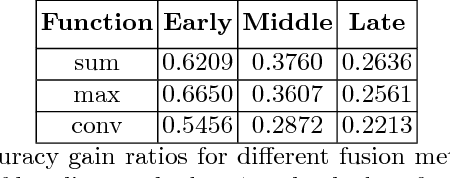
In this work, we propose a multi-modal Convolutional Neural Network (CNN) approach for brain tumor segmentation. We investigate how to combine different modalities efficiently in the CNN framework.We adapt various fusion methods, which are previously employed on video recognition problem, to the brain tumor segmentation problem,and we investigate their efficiency in terms of memory and performance.Our experiments, which are performed on BRATS dataset, lead us to the conclusion that learning separate representations for each modality and combining them for brain tumor segmentation could increase the performance of CNN systems.
Exploiting Convolution Filter Patterns for Transfer Learning
Aug 23, 2017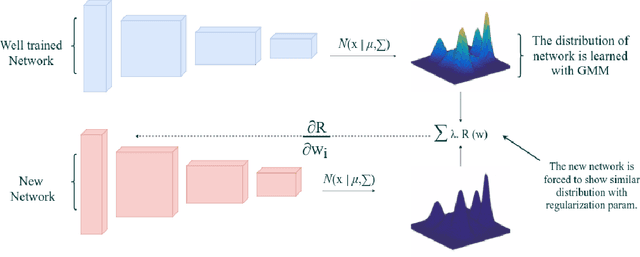
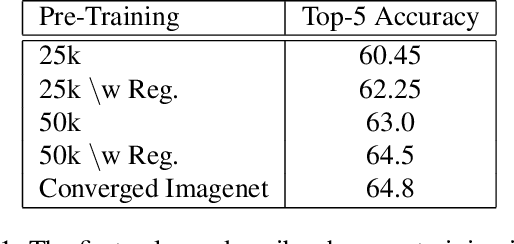

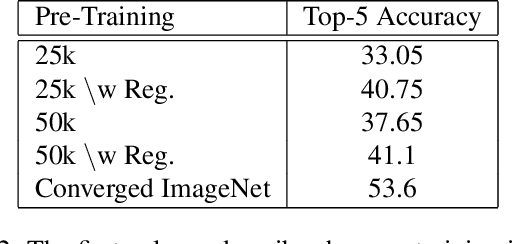
In this paper, we introduce a new regularization technique for transfer learning. The aim of the proposed approach is to capture statistical relationships among convolution filters learned from a well-trained network and transfer this knowledge to another network. Since convolution filters of the prevalent deep Convolutional Neural Network (CNN) models share a number of similar patterns, in order to speed up the learning procedure, we capture such correlations by Gaussian Mixture Models (GMMs) and transfer them using a regularization term. We have conducted extensive experiments on the CIFAR10, Places2, and CMPlaces datasets to assess generalizability, task transferability, and cross-model transferability of the proposed approach, respectively. The experimental results show that the feature representations have efficiently been learned and transferred through the proposed statistical regularization scheme. Moreover, our method is an architecture independent approach, which is applicable for a variety of CNN architectures.