 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Generalist Approach for Panoptic Segmentation
Aug 29, 2024Generalist vision models aim for one and the same architecture for a variety of vision tasks. While such shared architecture may seem attractive, generalist models tend to be outperformed by their bespoken counterparts, especially in the case of panoptic segmentation. We address this problem by introducing two key contributions, without compromising the desirable properties of generalist models. These contributions are: (i) a positional-embedding (PE) based loss for improved centroid regressions; (ii) Edge Distance Sampling (EDS) for the better separation of instance boundaries. The PE-based loss facilitates a better per-pixel regression of the associated instance's centroid, whereas EDS contributes by carefully handling the void regions (caused by missing labels) and smaller instances. These two simple yet effective modifications significantly improve established baselines, while achieving state-of-the-art results among all generalist solutions. More specifically, our method achieves a panoptic quality(PQ) of 52.5 on the COCO dataset, which is an improvement of 10 points over the best model with similar approach (Painter), and is superior by 2 to the best performing diffusion-based method Pix2Seq-$\mathcal{D}$. Furthermore, we provide insights into and an in-depth analysis of our contributions through exhaustive experiments. Our source code and model weights will be made publicly available.
Physically Feasible Semantic Segmentation
Aug 26, 2024



State-of-the-art semantic segmentation models are typically optimized in a data-driven fashion, minimizing solely per-pixel classification objectives on their training data. This purely data-driven paradigm often leads to absurd segmentations, especially when the domain of input images is shifted from the one encountered during training. For instance, state-of-the-art models may assign the label ``road'' to a segment which is located above a segment that is respectively labeled as ``sky'', although our knowledge of the physical world dictates that such a configuration is not feasible for images captured by forward-facing upright cameras. Our method, Physically Feasible Semantic Segmentation (PhyFea), extracts explicit physical constraints that govern spatial class relations from the training sets of semantic segmentation datasets and enforces a differentiable loss function that penalizes violations of these constraints to promote prediction feasibility. PhyFea yields significant performance improvements in mIoU over each state-of-the-art network we use as baseline across ADE20K, Cityscapes and ACDC, notably a $1.5\%$ improvement on ADE20K and a $2.1\%$ improvement on ACDC.
ShapeSplat: A Large-scale Dataset of Gaussian Splats and Their Self-Supervised Pretraining
Aug 20, 2024



3D Gaussian Splatting (3DGS) has become the de facto method of 3D representation in many vision tasks. This calls for the 3D understanding directly in this representation space. To facilitate the research in this direction, we first build a large-scale dataset of 3DGS using the commonly used ShapeNet and ModelNet datasets. Our dataset ShapeSplat consists of 65K objects from 87 unique categories, whose labels are in accordance with the respective datasets. The creation of this dataset utilized the compute equivalent of 2 GPU years on a TITAN XP GPU. We utilize our dataset for unsupervised pretraining and supervised finetuning for classification and segmentation tasks. To this end, we introduce \textbf{\textit{Gaussian-MAE}}, which highlights the unique benefits of representation learning from Gaussian parameters. Through exhaustive experiments, we provide several valuable insights. In particular, we show that (1) the distribution of the optimized GS centroids significantly differs from the uniformly sampled point cloud (used for initialization) counterpart; (2) this change in distribution results in degradation in classification but improvement in segmentation tasks when using only the centroids; (3) to leverage additional Gaussian parameters, we propose Gaussian feature grouping in a normalized feature space, along with splats pooling layer, offering a tailored solution to effectively group and embed similar Gaussians, which leads to notable improvement in finetuning tasks.
Locate Anything on Earth: Advancing Open-Vocabulary Object Detection for Remote Sensing Community
Aug 17, 2024Object detection, particularly open-vocabulary object detection, plays a crucial role in Earth sciences, such as environmental monitoring, natural disaster assessment, and land-use planning. However, existing open-vocabulary detectors, primarily trained on natural-world images, struggle to generalize to remote sensing images due to a significant data domain gap. Thus, this paper aims to advance the development of open-vocabulary object detection in remote sensing community. To achieve this, we first reformulate the task as Locate Anything on Earth (LAE) with the goal of detecting any novel concepts on Earth. We then developed the LAE-Label Engine which collects, auto-annotates, and unifies up to 10 remote sensing datasets creating the LAE-1M - the first large-scale remote sensing object detection dataset with broad category coverage. Using the LAE-1M, we further propose and train the novel LAE-DINO Model, the first open-vocabulary foundation object detector for the LAE task, featuring Dynamic Vocabulary Construction (DVC) and Visual-Guided Text Prompt Learning (VisGT) modules. DVC dynamically constructs vocabulary for each training batch, while VisGT maps visual features to semantic space, enhancing text features. We comprehensively conduct experiments on established remote sensing benchmark DIOR, DOTAv2.0, as well as our newly introduced 80-class LAE-80C benchmark. Results demonstrate the advantages of the LAE-1M dataset and the effectiveness of the LAE-DINO method.
VF-NeRF: Learning Neural Vector Fields for Indoor Scene Reconstruction
Aug 16, 2024



Implicit surfaces via neural radiance fields (NeRF) have shown surprising accuracy in surface reconstruction. Despite their success in reconstructing richly textured surfaces, existing methods struggle with planar regions with weak textures, which account for the majority of indoor scenes. In this paper, we address indoor dense surface reconstruction by revisiting key aspects of NeRF in order to use the recently proposed Vector Field (VF) as the implicit representation. VF is defined by the unit vector directed to the nearest surface point. It therefore flips direction at the surface and equals to the explicit surface normals. Except for this flip, VF remains constant along planar surfaces and provides a strong inductive bias in representing planar surfaces. Concretely, we develop a novel density-VF relationship and a training scheme that allows us to learn VF via volume rendering By doing this, VF-NeRF can model large planar surfaces and sharp corners accurately. We show that, when depth cues are available, our method further improves and achieves state-of-the-art results in reconstructing indoor scenes and rendering novel views. We extensively evaluate VF-NeRF on indoor datasets and run ablations of its components.
Mipmap-GS: Let Gaussians Deform with Scale-specific Mipmap for Anti-aliasing Rendering
Aug 12, 20243D Gaussian Splatting (3DGS) has attracted great attention in novel view synthesis because of its superior rendering efficiency and high fidelity. However, the trained Gaussians suffer from severe zooming degradation due to non-adjustable representation derived from single-scale training. Though some methods attempt to tackle this problem via post-processing techniques such as selective rendering or filtering techniques towards primitives, the scale-specific information is not involved in Gaussians. In this paper, we propose a unified optimization method to make Gaussians adaptive for arbitrary scales by self-adjusting the primitive properties (e.g., color, shape and size) and distribution (e.g., position). Inspired by the mipmap technique, we design pseudo ground-truth for the target scale and propose a scale-consistency guidance loss to inject scale information into 3D Gaussians. Our method is a plug-in module, applicable for any 3DGS models to solve the zoom-in and zoom-out aliasing. Extensive experiments demonstrate the effectiveness of our method. Notably, our method outperforms 3DGS in PSNR by an average of 9.25 dB for zoom-in and 10.40 dB for zoom-out on the NeRF Synthetic dataset.
Sun Off, Lights On: Photorealistic Monocular Nighttime Simulation for Robust Semantic Perception
Jul 29, 2024



Nighttime scenes are hard to semantically perceive with learned models and annotate for humans. Thus, realistic synthetic nighttime data become all the more important for learning robust semantic perception at night, thanks to their accurate and cheap semantic annotations. However, existing data-driven or hand-crafted techniques for generating nighttime images from daytime counterparts suffer from poor realism. The reason is the complex interaction of highly spatially varying nighttime illumination, which differs drastically from its daytime counterpart, with objects of spatially varying materials in the scene, happening in 3D and being very hard to capture with such 2D approaches. The above 3D interaction and illumination shift have proven equally hard to model in the literature, as opposed to other conditions such as fog or rain. Our method, named Sun Off, Lights On (SOLO), is the first to perform nighttime simulation on single images in a photorealistic fashion by operating in 3D. It first explicitly estimates the 3D geometry, the materials and the locations of light sources of the scene from the input daytime image and relights the scene by probabilistically instantiating light sources in a way that accounts for their semantics and then running standard ray tracing. Not only is the visual quality and photorealism of our nighttime images superior to competing approaches including diffusion models, but the former images are also proven more beneficial for semantic nighttime segmentation in day-to-night adaptation. Code and data will be made publicly available.
PIV3CAMS: a multi-camera dataset for multiple computer vision problems and its application to novel view-point synthesis
Jul 26, 2024
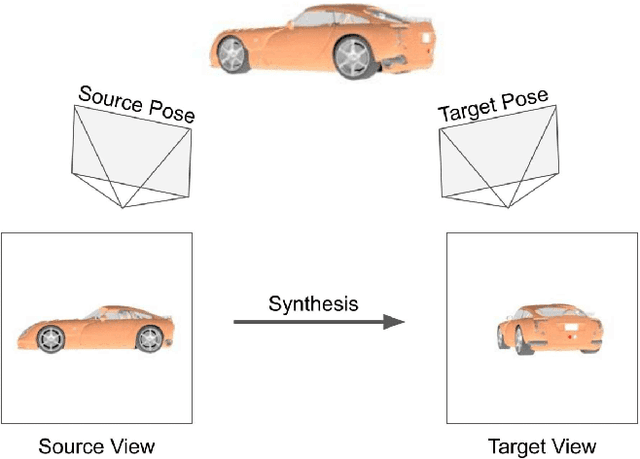


The modern approaches for computer vision tasks significantly rely on machine learning, which requires a large number of quality images. While there is a plethora of image datasets with a single type of images, there is a lack of datasets collected from multiple cameras. In this thesis, we introduce Paired Image and Video data from three CAMeraS, namely PIV3CAMS, aimed at multiple computer vision tasks. The PIV3CAMS dataset consists of 8385 pairs of images and 82 pairs of videos taken from three different cameras: Canon D5 Mark IV, Huawei P20, and ZED stereo camera. The dataset includes various indoor and outdoor scenes from different locations in Zurich (Switzerland) and Cheonan (South Korea). Some of the computer vision applications that can benefit from the PIV3CAMS dataset are image/video enhancement, view interpolation, image matching, and much more. We provide a careful explanation of the data collection process and detailed analysis of the data. The second part of this thesis studies the usage of depth information in the view synthesizing task. In addition to the regeneration of a current state-of-the-art algorithm, we investigate several proposed alternative models that integrate depth information geometrically. Through extensive experiments, we show that the effect of depth is crucial in small view changes. Finally, we apply our model to the introduced PIV3CAMS dataset to synthesize novel target views as an example application of PIV3CAMS.
Any Image Restoration with Efficient Automatic Degradation Adaptation
Jul 18, 2024



With the emergence of mobile devices, there is a growing demand for an efficient model to restore any degraded image for better perceptual quality. However, existing models often require specific learning modules tailored for each degradation, resulting in complex architectures and high computation costs. Different from previous work, in this paper, we propose a unified manner to achieve joint embedding by leveraging the inherent similarities across various degradations for efficient and comprehensive restoration. Specifically, we first dig into the sub-latent space of each input to analyze the key components and reweight their contributions in a gated manner. The intrinsic awareness is further integrated with contextualized attention in an X-shaped scheme, maximizing local-global intertwining. Extensive comparison on benchmarking all-in-one restoration setting validates our efficiency and effectiveness, i.e., our network sets new SOTA records while reducing model complexity by approximately -82% in trainable parameters and -85\% in FLOPs. Our code will be made publicly available at:https://github.com/Amazingren/AnyIR.
Bringing Masked Autoencoders Explicit Contrastive Properties for Point Cloud Self-Supervised Learning
Jul 08, 2024



Contrastive learning (CL) for Vision Transformers (ViTs) in image domains has achieved performance comparable to CL for traditional convolutional backbones. However, in 3D point cloud pretraining with ViTs, masked autoencoder (MAE) modeling remains dominant. This raises the question: Can we take the best of both worlds? To answer this question, we first empirically validate that integrating MAE-based point cloud pre-training with the standard contrastive learning paradigm, even with meticulous design, can lead to a decrease in performance. To address this limitation, we reintroduce CL into the MAE-based point cloud pre-training paradigm by leveraging the inherent contrastive properties of MAE. Specifically, rather than relying on extensive data augmentation as commonly used in the image domain, we randomly mask the input tokens twice to generate contrastive input pairs. Subsequently, a weight-sharing encoder and two identically structured decoders are utilized to perform masked token reconstruction. Additionally, we propose that for an input token masked by both masks simultaneously, the reconstructed features should be as similar as possible. This naturally establishes an explicit contrastive constraint within the generative MAE-based pre-training paradigm, resulting in our proposed method, Point-CMAE. Consequently, Point-CMAE effectively enhances the representation quality and transfer performance compared to its MAE counterpart. Experimental evaluations across various downstream applications, including classification, part segmentation, and few-shot learning, demonstrate the efficacy of our framework in surpassing state-of-the-art techniques under standard ViTs and single-modal settings. The source code and trained models are available at: https://github.com/Amazingren/Point-CMAE.