 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefign: Align and Refine for Adaptation of Semantic Segmentation to Adverse Conditions
Jul 14, 2022
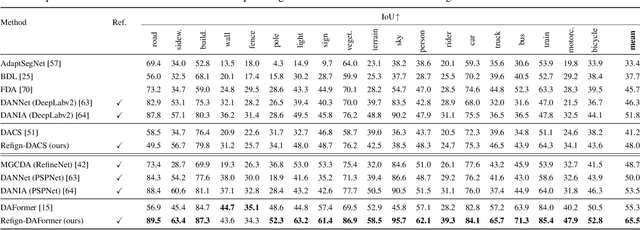
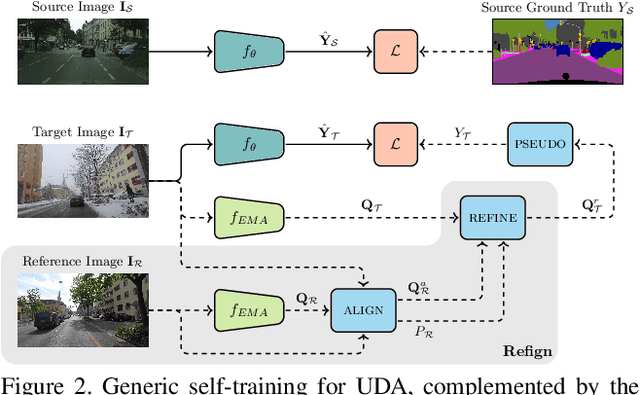
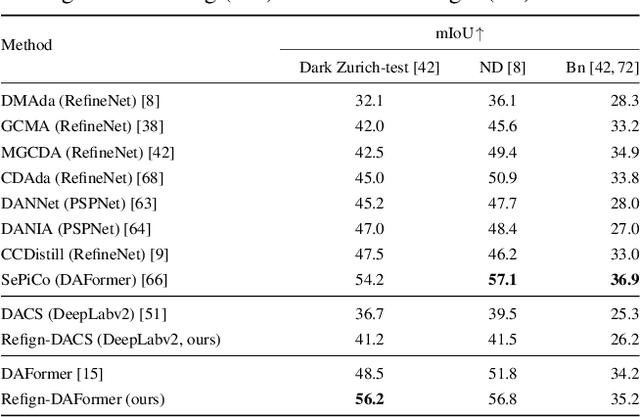
Due to the scarcity of dense pixel-level semantic annotations for images recorded in adverse visual conditions, there has been a keen interest in unsupervised domain adaptation (UDA) for the semantic segmentation of such images. UDA adapts models trained on normal conditions to the target adverse-condition domains. Meanwhile, multiple datasets with driving scenes provide corresponding images of the same scenes across multiple conditions, which can serve as a form of weak supervision for domain adaptation. We propose Refign, a generic extension to self-training-based UDA methods which leverages these cross-domain correspondences. Refign consists of two steps: (1) aligning the normal-condition image to the corresponding adverse-condition image using an uncertainty-aware dense matching network, and (2) refining the adverse prediction with the normal prediction using an adaptive label correction mechanism. We design custom modules to streamline both steps and set the new state of the art for domain-adaptive semantic segmentation on several adverse-condition benchmarks, including ACDC and Dark Zurich. The approach introduces no extra training parameters, minimal computational overhead -- during training only -- and can be used as a drop-in extension to improve any given self-training-based UDA method. Code is available at https://github.com/brdav/refign.
OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers
Jul 08, 2022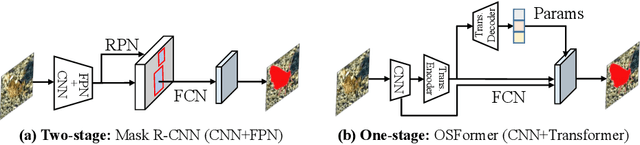
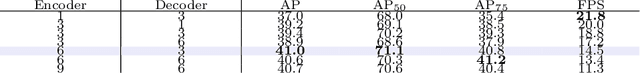

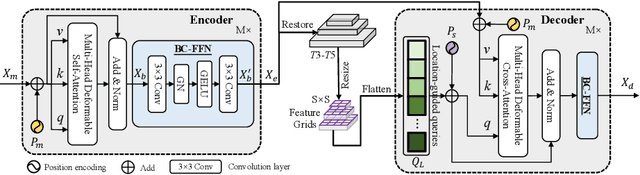
We present OSFormer, the first one-stage transformer framework for camouflaged instance segmentation (CIS). OSFormer is based on two key designs. First, we design a location-sensing transformer (LST) to obtain the location label and instance-aware parameters by introducing the location-guided queries and the blend-convolution feedforward network. Second, we develop a coarse-to-fine fusion (CFF) to merge diverse context information from the LST encoder and CNN backbone. Coupling these two components enables OSFormer to efficiently blend local features and long-range context dependencies for predicting camouflaged instances. Compared with two-stage frameworks, our OSFormer reaches 41% AP and achieves good convergence efficiency without requiring enormous training data, i.e., only 3,040 samples under 60 epochs. Code link: https://github.com/PJLallen/OSFormer.
Lasers to Events: Automatic Extrinsic Calibration of Lidars and Event Cameras
Jul 03, 2022



Despite significant academic and corporate efforts, autonomous driving under adverse visual conditions still proves challenging. As neuromorphic technology has matured, its application to robotics and autonomous vehicle systems has become an area of active research. Low-light and latency-demanding situations can benefit. To enable event cameras to operate alongside staple sensors like lidar in perception tasks, we propose a direct, temporally-decoupled calibration method between event cameras and lidars. The high dynamic range and low-light operation of event cameras are exploited to directly register lidar laser returns, allowing information-based correlation methods to optimize for the 6-DoF extrinsic calibration between the two sensors. This paper presents the first direct calibration method between event cameras and lidars, removing dependencies on frame-based camera intermediaries and/or highly-accurate hand measurements. Code will be made publicly available.
HRFuser: A Multi-resolution Sensor Fusion Architecture for 2D Object Detection
Jun 30, 2022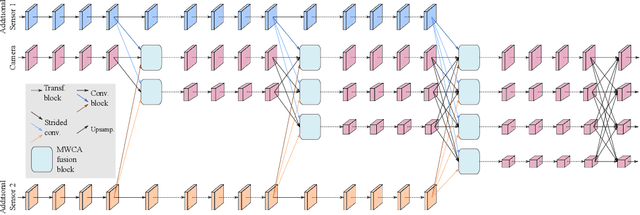
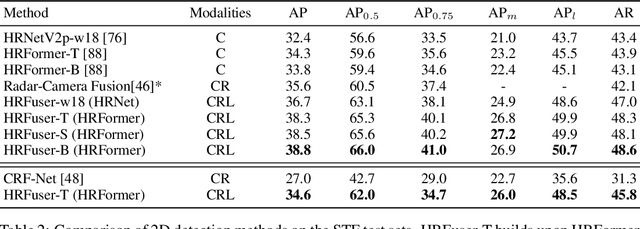
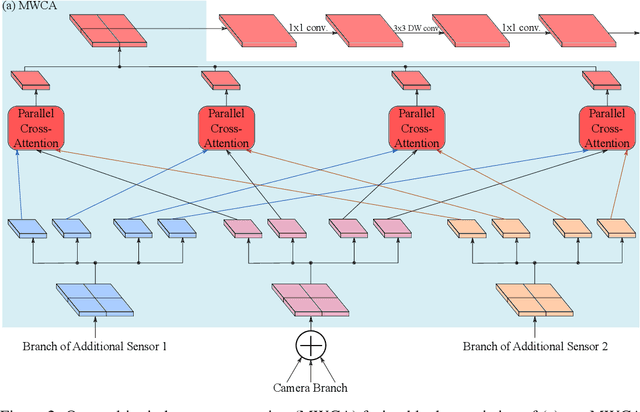

Besides standard cameras, autonomous vehicles typically include multiple additional sensors, such as lidars and radars, which help acquire richer information for perceiving the content of the driving scene. While several recent works focus on fusing certain pairs of sensors - such as camera and lidar or camera and radar - by using architectural components specific to the examined setting, a generic and modular sensor fusion architecture is missing from the literature. In this work, we focus on 2D object detection, a fundamental high-level task which is defined on the 2D image domain, and propose HRFuser, a multi-resolution sensor fusion architecture that scales straightforwardly to an arbitrary number of input modalities. The design of HRFuser is based on state-of-the-art high-resolution networks for image-only dense prediction and incorporates a novel multi-window cross-attention block as the means to perform fusion of multiple modalities at multiple resolutions. Even though cameras alone provide very informative features for 2D detection, we demonstrate via extensive experiments on the nuScenes and Seeing Through Fog datasets that our model effectively leverages complementary features from additional modalities, substantially improving upon camera-only performance and consistently outperforming state-of-the-art fusion methods for 2D detection both in normal and adverse conditions. The source code will be made publicly available.
3D-Aware Video Generation
Jun 29, 2022
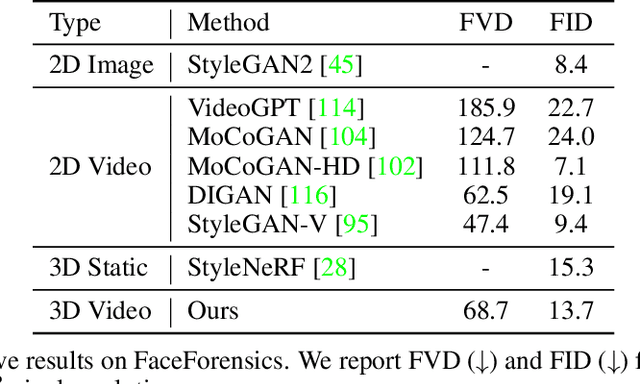
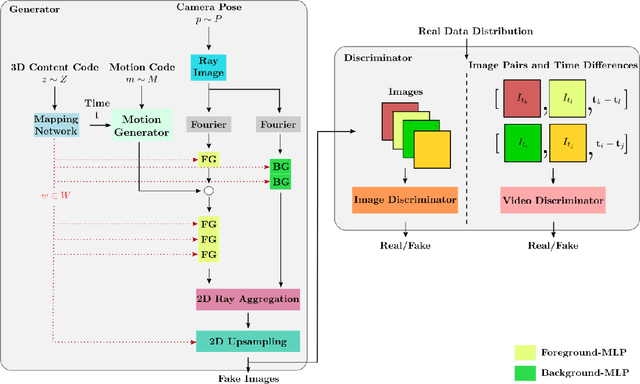

Generative models have emerged as an essential building block for many image synthesis and editing tasks. Recent advances in this field have also enabled high-quality 3D or video content to be generated that exhibits either multi-view or temporal consistency. With our work, we explore 4D generative adversarial networks (GANs) that learn unconditional generation of 3D-aware videos. By combining neural implicit representations with time-aware discriminator, we develop a GAN framework that synthesizes 3D video supervised only with monocular videos. We show that our method learns a rich embedding of decomposable 3D structures and motions that enables new visual effects of spatio-temporal renderings while producing imagery with quality comparable to that of existing 3D or video GANs.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022
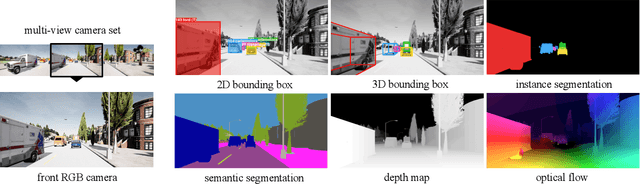

Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
Residual Sparsity Connection Learning for Efficient Video Super-Resolution
Jun 15, 2022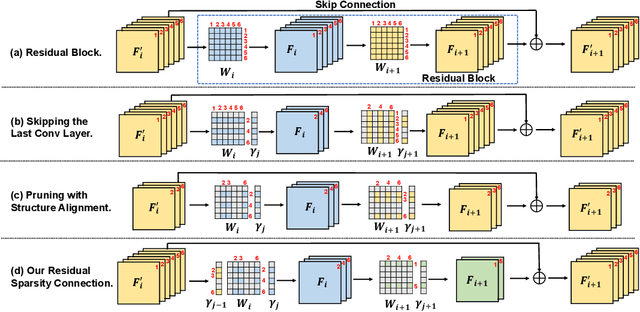
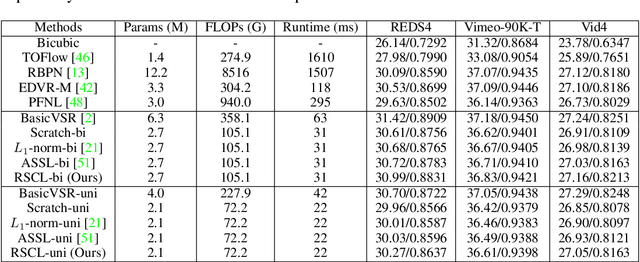
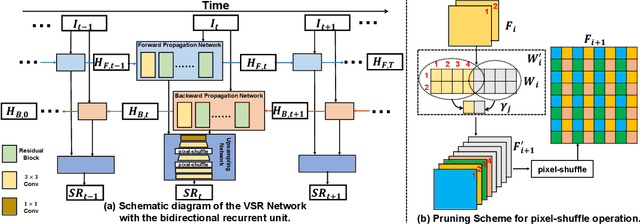
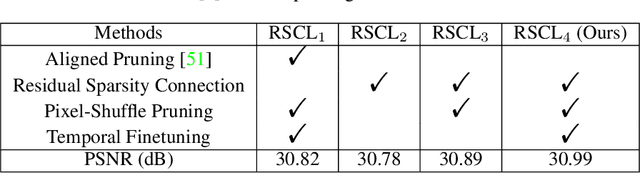
Lighter and faster models are crucial for the deployment of video super-resolution (VSR) on resource-limited devices, e.g., smartphones and wearable devices. In this paper, we develop Residual Sparsity Connection Learning (RSCL), a structured pruning scheme, to reduce the redundancy of convolution kernels and obtain a compact VSR network with a minor performance drop. However, residual blocks require the pruned filter indices of skip and residual connections to be the same, which is tricky for pruning. Thus, to mitigate the pruning restrictions of residual blocks, we design a Residual Sparsity Connection (RSC) scheme by preserving the feature channels and only operating on the important channels. Moreover, for the pixel-shuffle operation, we design a special pruning scheme by grouping several filters as pruning units to guarantee the accuracy of feature channel-space conversion after pruning. In addition, we introduce Temporal Finetuning (TF) to reduce the pruning error amplification of hidden states with temporal propagation. Extensive experiments show that the proposed RSCL significantly outperforms recent methods quantitatively and qualitatively. Codes and models will be released.
Discovering Object Masks with Transformers for Unsupervised Semantic Segmentation
Jun 13, 2022
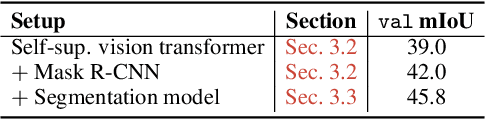
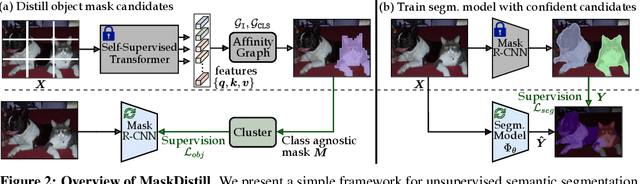
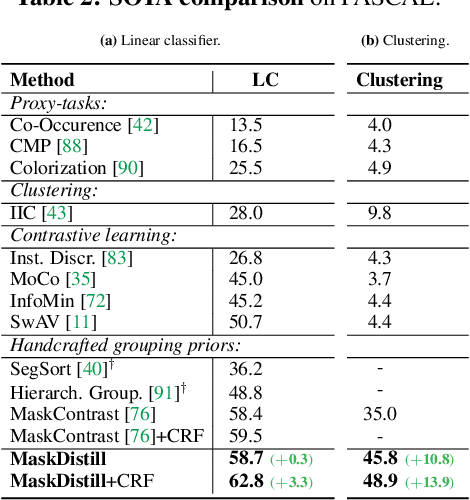
The task of unsupervised semantic segmentation aims to cluster pixels into semantically meaningful groups. Specifically, pixels assigned to the same cluster should share high-level semantic properties like their object or part category. This paper presents MaskDistill: a novel framework for unsupervised semantic segmentation based on three key ideas. First, we advocate a data-driven strategy to generate object masks that serve as a pixel grouping prior for semantic segmentation. This approach omits handcrafted priors, which are often designed for specific scene compositions and limit the applicability of competing frameworks. Second, MaskDistill clusters the object masks to obtain pseudo-ground-truth for training an initial object segmentation model. Third, we leverage this model to filter out low-quality object masks. This strategy mitigates the noise in our pixel grouping prior and results in a clean collection of masks which we use to train a final segmentation model. By combining these components, we can considerably outperform previous works for unsupervised semantic segmentation on PASCAL (+11% mIoU) and COCO (+4% mask AP50). Interestingly, as opposed to existing approaches, our framework does not latch onto low-level image cues and is not limited to object-centric datasets. The code and models will be made available.
Recurrent Video Restoration Transformer with Guided Deformable Attention
Jun 05, 2022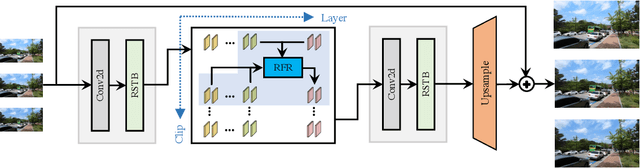
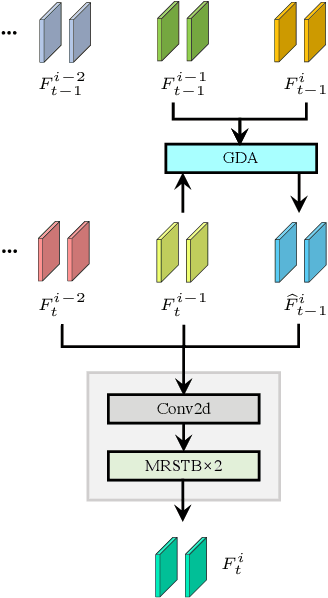
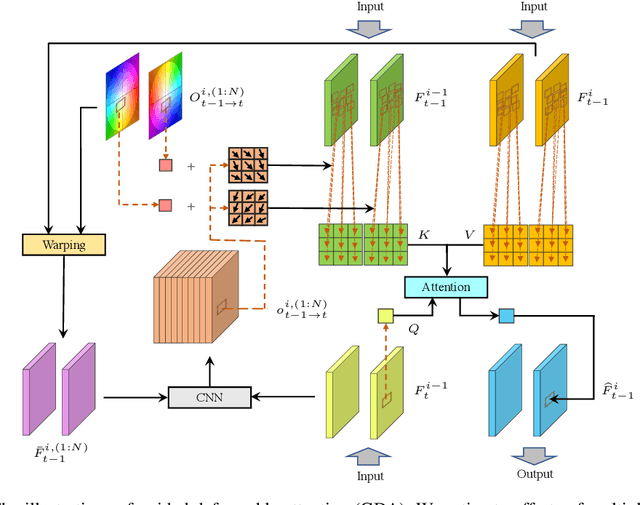
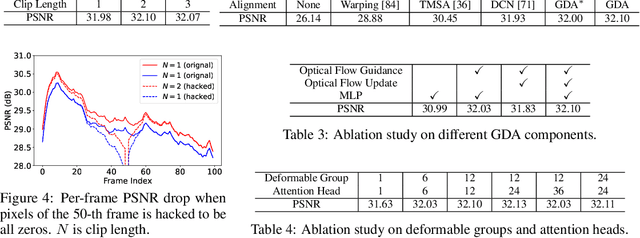
Video restoration aims at restoring multiple high-quality frames from multiple low-quality frames. Existing video restoration methods generally fall into two extreme cases, i.e., they either restore all frames in parallel or restore the video frame by frame in a recurrent way, which would result in different merits and drawbacks. Typically, the former has the advantage of temporal information fusion. However, it suffers from large model size and intensive memory consumption; the latter has a relatively small model size as it shares parameters across frames; however, it lacks long-range dependency modeling ability and parallelizability. In this paper, we attempt to integrate the advantages of the two cases by proposing a recurrent video restoration transformer, namely RVRT. RVRT processes local neighboring frames in parallel within a globally recurrent framework which can achieve a good trade-off between model size, effectiveness, and efficiency. Specifically, RVRT divides the video into multiple clips and uses the previously inferred clip feature to estimate the subsequent clip feature. Within each clip, different frame features are jointly updated with implicit feature aggregation. Across different clips, the guided deformable attention is designed for clip-to-clip alignment, which predicts multiple relevant locations from the whole inferred clip and aggregates their features by the attention mechanism. Extensive experiments on video super-resolution, deblurring, and denoising show that the proposed RVRT achieves state-of-the-art performance on benchmark datasets with balanced model size, testing memory and runtime.
Gradient Obfuscation Checklist Test Gives a False Sense of Security
Jun 03, 2022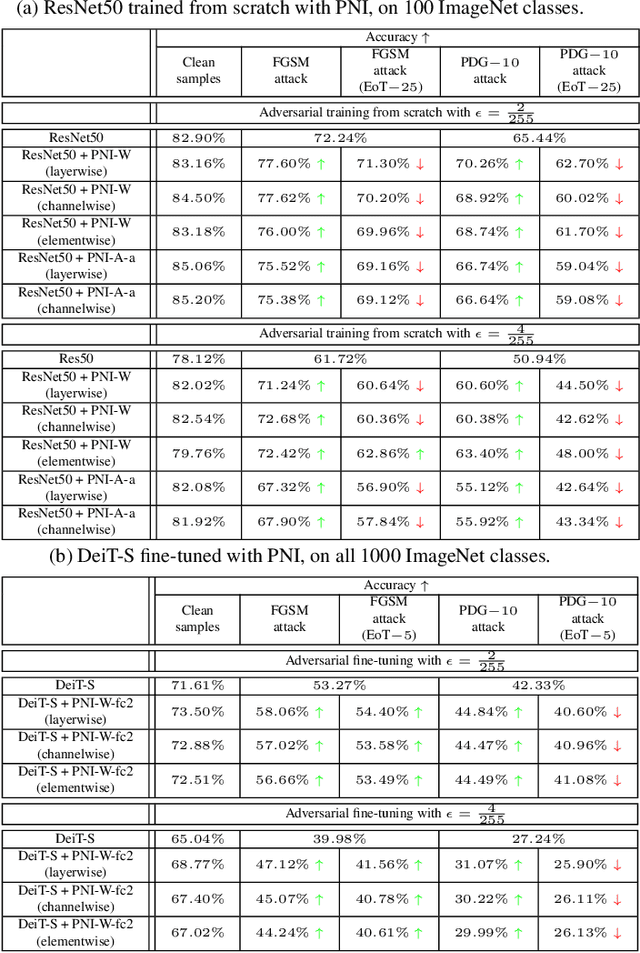
One popular group of defense techniques against adversarial attacks is based on injecting stochastic noise into the network. The main source of robustness of such stochastic defenses however is often due to the obfuscation of the gradients, offering a false sense of security. Since most of the popular adversarial attacks are optimization-based, obfuscated gradients reduce their attacking ability, while the model is still susceptible to stronger or specifically tailored adversarial attacks. Recently, five characteristics have been identified, which are commonly observed when the improvement in robustness is mainly caused by gradient obfuscation. It has since become a trend to use these five characteristics as a sufficient test, to determine whether or not gradient obfuscation is the main source of robustness. However, these characteristics do not perfectly characterize all existing cases of gradient obfuscation, and therefore can not serve as a basis for a conclusive test. In this work, we present a counterexample, showing this test is not sufficient for concluding that gradient obfuscation is not the main cause of improvements in robustness.