 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
Apr 13, 2025



Existing evaluation of large language model (LLM) agents on scientific discovery lacks objective baselines and metrics to assess the viability of their proposed methods. To address this issue, we introduce MLRC-Bench, a benchmark designed to quantify how effectively language agents can tackle challenging Machine Learning (ML) Research Competitions. Our benchmark highlights open research problems that demand novel methodologies, in contrast to recent benchmarks such as OpenAI's MLE-Bench (Chan et al., 2024) and METR's RE-Bench (Wijk et al., 2024), which focus on well-established research tasks that are largely solvable through sufficient engineering effort. Unlike prior work, e.g., AI Scientist (Lu et al., 2024b), which evaluates the end-to-end agentic pipeline by using LLM-as-a-judge, MLRC-Bench measures the key steps of proposing and implementing novel research methods and evaluates them with newly proposed rigorous protocol and objective metrics. Our curated suite of 7 competition tasks reveals significant challenges for LLM agents. Even the best-performing tested agent (gemini-exp-1206 under MLAB (Huang et al., 2024a)) closes only 9.3% of the gap between baseline and top human participant scores. Furthermore, our analysis reveals a misalignment between the LLM-judged innovation and their actual performance on cutting-edge ML research problems. MLRC-Bench is a dynamic benchmark, which is designed to continually grow with new ML competitions to encourage rigorous and objective evaluations of AI's research capabilities.
Detection-Friendly Nonuniformity Correction: A Union Framework for Infrared UAVTarget Detection
Apr 05, 2025



Infrared unmanned aerial vehicle (UAV) images captured using thermal detectors are often affected by temperature dependent low-frequency nonuniformity, which significantly reduces the contrast of the images. Detecting UAV targets under nonuniform conditions is crucial in UAV surveillance applications. Existing methods typically treat infrared nonuniformity correction (NUC) as a preprocessing step for detection, which leads to suboptimal performance. Balancing the two tasks while enhancing detection beneficial information remains challenging. In this paper, we present a detection-friendly union framework, termed UniCD, that simultaneously addresses both infrared NUC and UAV target detection tasks in an end-to-end manner. We first model NUC as a small number of parameter estimation problem jointly driven by priors and data to generate detection-conducive images. Then, we incorporate a new auxiliary loss with target mask supervision into the backbone of the infrared UAV target detection network to strengthen target features while suppressing the background. To better balance correction and detection, we introduce a detection-guided self-supervised loss to reduce feature discrepancies between the two tasks, thereby enhancing detection robustness to varying nonuniformity levels. Additionally, we construct a new benchmark composed of 50,000 infrared images in various nonuniformity types, multi-scale UAV targets and rich backgrounds with target annotations, called IRBFD. Extensive experiments on IRBFD demonstrate that our UniCD is a robust union framework for NUC and UAV target detection while achieving real-time processing capabilities. Dataset can be available at https://github.com/IVPLaboratory/UniCD.
VEM: Environment-Free Exploration for Training GUI Agent with Value Environment Model
Feb 26, 2025



Training Vision-Language Models (VLMs) for Graphical User Interfaces (GUI) agents via Reinforcement Learning (RL) faces critical challenges: environment-based RL requires costly interactions, while environment-free methods struggle with distribution shift and reward generalization. We propose an environment-free RL framework that decouples value estimation from policy optimization by leveraging a pretrained Value Environment Model (VEM). VEM predicts state-action values directly from offline data, distilling human-like priors about GUI interaction outcomes without requiring next-state prediction or environmental feedback. This avoids compounding errors and enhances resilience to UI changes by focusing on semantic reasoning (e.g., Does this action advance the user's goal?). The framework operates in two stages: (1) pretraining VEM to estimate long-term action utilities and (2) guiding policy exploration with frozen VEM signals, enabling layout-agnostic GUI automation. Evaluated on Android-in-the-Wild benchmarks, VEM achieves state-of-the-art performance in both offline and online settings, outperforming environment-free baselines significantly and matching environment-based approaches without interaction costs. Importantly, VEM demonstrates that semantic-aware value estimation can achieve comparable performance with online-trained methods.
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?
Feb 26, 2025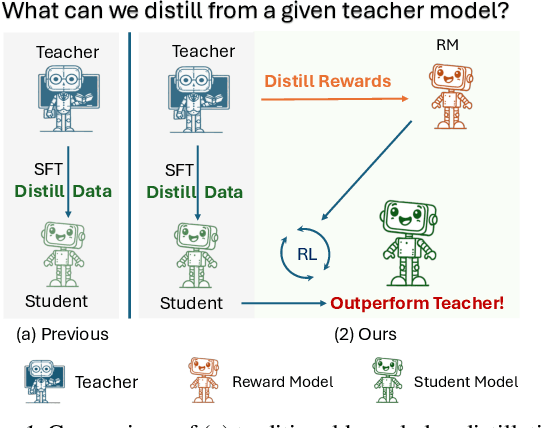

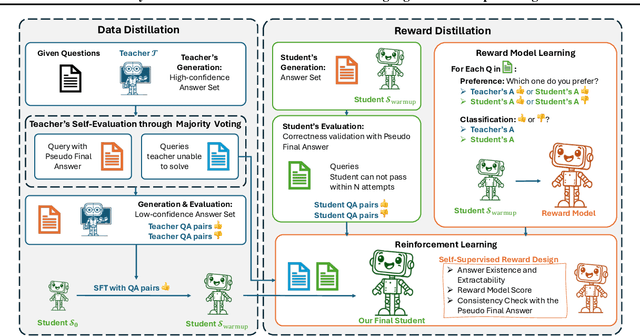
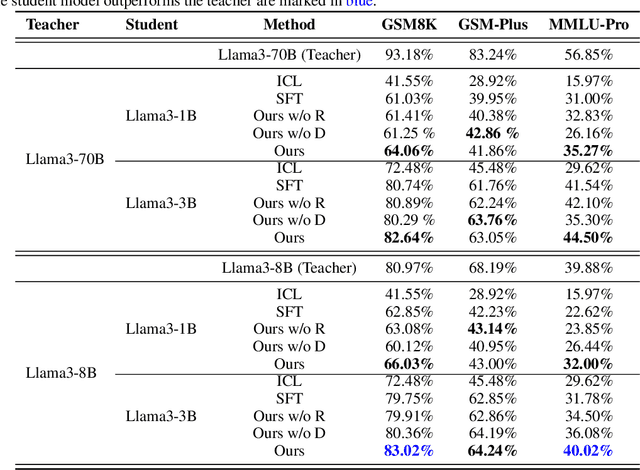
Distilling large language models (LLMs) typically involves transferring the teacher model's responses through supervised fine-tuning (SFT). However, this approach neglects the potential to distill both data (output content) and reward signals (quality evaluations). Extracting reliable reward signals directly from teacher models is challenging, as LLMs are optimized for generation rather than evaluation, often resulting in biased or inconsistent assessments. To address this limitation, we propose a novel distillation pipeline that transfers both responses and rewards. Our method generates pseudo-rewards through a self-supervised mechanism that leverages the inherent structure of both teacher and student responses, enabling reward learning without explicit external evaluation. The reward model subsequently guides reinforcement learning (RL), allowing iterative refinement of the student model after an SFT warm-up phase. Experiments on GSM8K and MMLU-PRO demonstrate that our method consistently outperforms traditional SFT-based approaches, enabling student models to surpass the performance of their teachers. This work highlights the potential for scalable, efficient distillation through structured self-supervised reward learning, reducing dependence on external reward supervision.
Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance
Feb 24, 2025Proximal Policy Optimization (PPO)-based Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human preferences. It requires joint training of an actor and critic with a pretrained, fixed reward model for guidance. This approach increases computational complexity and instability due to actor-critic interdependence. Additionally, PPO lacks access to true environment rewards in LLM tasks, limiting its adaptability. Under such conditions, pretraining a value model or a reward model becomes equivalent, as both provide fixed supervisory signals without new ground-truth feedback. To address these issues, we propose \textbf{Decoupled Value Policy Optimization (DVPO)}, a lean framework that replaces traditional reward modeling with a pretrained \emph{global value model (GVM)}. The GVM is conditioned on policy trajectories and predicts token-level return-to-go estimates. By decoupling value model from policy training (via frozen GVM-driven RL objectives), DVPO eliminates actor-critic interdependence, reducing GPU memory usage by 40\% and training time by 35\% compared to conventional RLHF. Experiments across benchmarks show DVPO outperforms efficient RLHF methods (e.g., DPO) while matching state-of-the-art PPO in performance.
Unstructured Evidence Attribution for Long Context Query Focused Summarization
Feb 20, 2025Large language models (LLMs) are capable of generating coherent summaries from very long contexts given a user query. Extracting and properly citing evidence spans could help improve the transparency and reliability of these summaries. At the same time, LLMs suffer from positional biases in terms of which information they understand and attend to, which could affect evidence citation. Whereas previous work has focused on evidence citation with predefined levels of granularity (e.g. sentence, paragraph, document, etc.), we propose the task of long-context query focused summarization with unstructured evidence citation. We show how existing systems struggle to generate and properly cite unstructured evidence from their context, and that evidence tends to be "lost-in-the-middle". To help mitigate this, we create the Summaries with Unstructured Evidence Text dataset (SUnsET), a synthetic dataset generated using a novel domain-agnostic pipeline which can be used as supervision to adapt LLMs to this task. We demonstrate across 5 LLMs of different sizes and 4 datasets with varying document types and lengths that LLMs adapted with SUnsET data generate more relevant and factually consistent evidence than their base models, extract evidence from more diverse locations in their context, and can generate more relevant and consistent summaries.
IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System
Feb 08, 2025



Recently, large language model (LLM) based text-to-speech (TTS) systems have gradually become the mainstream in the industry due to their high naturalness and powerful zero-shot voice cloning capabilities.Here, we introduce the IndexTTS system, which is mainly based on the XTTS and Tortoise model. We add some novel improvements. Specifically, in Chinese scenarios, we adopt a hybrid modeling method that combines characters and pinyin, making the pronunciations of polyphonic characters and long-tail characters controllable. We also performed a comparative analysis of the Vector Quantization (VQ) with Finite-Scalar Quantization (FSQ) for codebook utilization of acoustic speech tokens. To further enhance the effect and stability of voice cloning, we introduce a conformer-based speech conditional encoder and replace the speechcode decoder with BigVGAN2. Compared with XTTS, it has achieved significant improvements in naturalness, content consistency, and zero-shot voice cloning. As for the popular TTS systems in the open-source, such as Fish-Speech, CosyVoice2, FireRedTTS and F5-TTS, IndexTTS has a relatively simple training process, more controllable usage, and faster inference speed. Moreover, its performance surpasses that of these systems. Our demos are available at https://index-tts.github.io.
Boosting Sclera Segmentation through Semi-supervised Learning with Fewer Labels
Jan 13, 2025



Sclera segmentation is crucial for developing automatic eye-related medical computer-aided diagnostic systems, as well as for personal identification and verification, because the sclera contains distinct personal features. Deep learning-based sclera segmentation has achieved significant success compared to traditional methods that rely on hand-crafted features, primarily because it can autonomously extract critical output-related features without the need to consider potential physical constraints. However, achieving accurate sclera segmentation using these methods is challenging due to the scarcity of high-quality, fully labeled datasets, which depend on costly, labor-intensive medical acquisition and expertise. To address this challenge, this paper introduces a novel sclera segmentation framework that excels with limited labeled samples. Specifically, we employ a semi-supervised learning method that integrates domain-specific improvements and image-based spatial transformations to enhance segmentation performance. Additionally, we have developed a real-world eye diagnosis dataset to enrich the evaluation process. Extensive experiments on our dataset and two additional public datasets demonstrate the effectiveness and superiority of our proposed method, especially with significantly fewer labeled samples.
From Conversation to Automation: Leveraging Large Language Models to Analyze Strategies in Problem Solving Therapy
Jan 10, 2025



Problem-solving therapy (PST) is a structured psychological approach that helps individuals manage stress and resolve personal issues by guiding them through problem identification, solution brainstorming, decision-making, and outcome evaluation. As mental health care increasingly integrates technologies like chatbots and large language models (LLMs), understanding how PST can be effectively automated is important. This study leverages anonymized therapy transcripts to analyze and classify therapeutic interventions using various LLMs and transformer-based models. Our results show that GPT-4o achieved the highest accuracy (0.76) in identifying PST strategies, outperforming other models. Additionally, we introduced a new dimension of communication strategies that enhances the current PST framework, offering deeper insights into therapist-client interactions. This research demonstrates the potential of LLMs to automate complex therapeutic dialogue analysis, providing a scalable, efficient tool for mental health interventions. Our annotation framework can enhance the accessibility, effectiveness, and personalization of PST, supporting therapists in real-time with more precise, targeted interventions.
Resource Allocation for ISAC Networks with Application to Target Tracking
Dec 29, 2024


Future 6G networks are expected to empower communication systems by integrating sensing capabilities, resulting in integrated sensing and communication (ISAC) systems. However, this integration may exacerbate the data traffic congestion in existing communication systems due to limited resources. Therefore, the resources of ISAC systems must be carefully allocated to ensure high performance. Given the increasing demands for both sensing and communication services, current methods are inadequate for tracking targets frequently in every frame while simultaneously communicating with users. To address this gap, this work formulates an optimization problem that jointly allocates resources in the time, frequency, power, and spatial domains for targets and users, accounting for the movement of targets and time-varying communication channels. Specifically, we minimize the trace of posterior Cram\'er-Rao bound for target tracking subject to communication throughput and resource allocation constraints. To solve this non-convex problem, we develop a block coordinate descent (BCD) algorithm based on the penalty method, successive convex approximation (SCA), and one-dimensional search. Simulation results demonstrate the validity of the proposed algorithm and the performance trade-off between sensing and communication.