 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Oct 10, 2025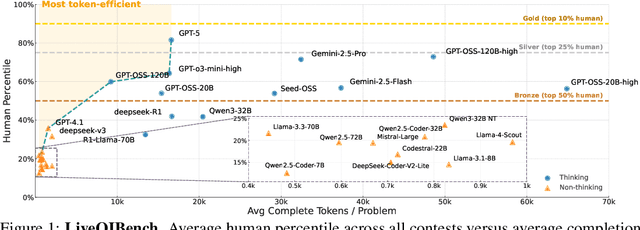
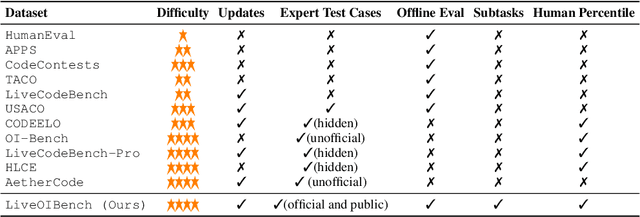
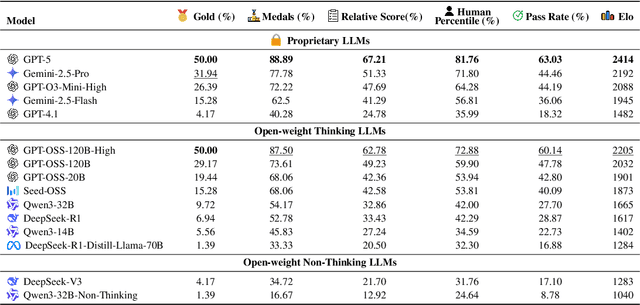
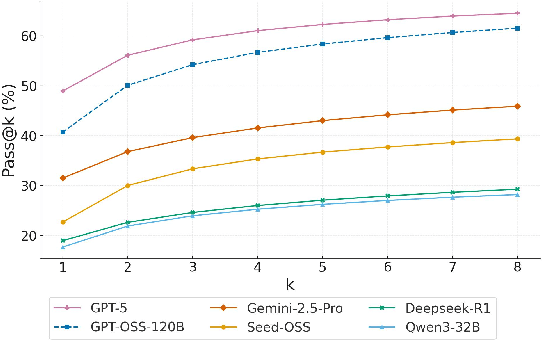
Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of large language models (LLMs) due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025. LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing humans; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments. Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81.76th percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration. All data, code, and leaderboard results will be made publicly available on our website.
MLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
Apr 13, 2025



Existing evaluation of large language model (LLM) agents on scientific discovery lacks objective baselines and metrics to assess the viability of their proposed methods. To address this issue, we introduce MLRC-Bench, a benchmark designed to quantify how effectively language agents can tackle challenging Machine Learning (ML) Research Competitions. Our benchmark highlights open research problems that demand novel methodologies, in contrast to recent benchmarks such as OpenAI's MLE-Bench (Chan et al., 2024) and METR's RE-Bench (Wijk et al., 2024), which focus on well-established research tasks that are largely solvable through sufficient engineering effort. Unlike prior work, e.g., AI Scientist (Lu et al., 2024b), which evaluates the end-to-end agentic pipeline by using LLM-as-a-judge, MLRC-Bench measures the key steps of proposing and implementing novel research methods and evaluates them with newly proposed rigorous protocol and objective metrics. Our curated suite of 7 competition tasks reveals significant challenges for LLM agents. Even the best-performing tested agent (gemini-exp-1206 under MLAB (Huang et al., 2024a)) closes only 9.3% of the gap between baseline and top human participant scores. Furthermore, our analysis reveals a misalignment between the LLM-judged innovation and their actual performance on cutting-edge ML research problems. MLRC-Bench is a dynamic benchmark, which is designed to continually grow with new ML competitions to encourage rigorous and objective evaluations of AI's research capabilities.