 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Greedy Algorithm for Optimal Sensor Placement Problem in Urban Sewage Surveillance
Sep 25, 2024



Designing a cost-effective sensor placement plan for sewage surveillance is a crucial task because it allows cost-effective early pandemic outbreak detection as supplementation for individual testing. However, this problem is computationally challenging to solve, especially for massive sewage networks having complicated topologies. In this paper, we formulate this problem as a multi-objective optimization problem to consider the conflicting objectives and put forward a novel evolutionary greedy algorithm (EG) to enable efficient and effective optimization for large-scale directed networks. The proposed model is evaluated on both small-scale synthetic networks and a large-scale, real-world sewage network in Hong Kong. The experiments on small-scale synthetic networks demonstrate a consistent efficiency improvement with reasonable optimization performance and the real-world application shows that our method is effective in generating optimal sensor placement plans to guide policy-making.
MusicAOG: an Energy-Based Model for Learning and Sampling a Hierarchical Representation of Symbolic Music
Jan 05, 2024In addressing the challenge of interpretability and generalizability of artificial music intelligence, this paper introduces a novel symbolic representation that amalgamates both explicit and implicit musical information across diverse traditions and granularities. Utilizing a hierarchical and-or graph representation, the model employs nodes and edges to encapsulate a broad spectrum of musical elements, including structures, textures, rhythms, and harmonies. This hierarchical approach expands the representability across various scales of music. This representation serves as the foundation for an energy-based model, uniquely tailored to learn musical concepts through a flexible algorithm framework relying on the minimax entropy principle. Utilizing an adapted Metropolis-Hastings sampling technique, the model enables fine-grained control over music generation. A comprehensive empirical evaluation, contrasting this novel approach with existing methodologies, manifests considerable advancements in interpretability and controllability. This study marks a substantial contribution to the fields of music analysis, composition, and computational musicology.
SSLCL: An Efficient Model-Agnostic Supervised Contrastive Learning Framework for Emotion Recognition in Conversations
Oct 25, 2023



Emotion recognition in conversations (ERC) is a rapidly evolving task within the natural language processing community, which aims to detect the emotions expressed by speakers during a conversation. Recently, a growing number of ERC methods have focused on leveraging supervised contrastive learning (SCL) to enhance the robustness and generalizability of learned features. However, current SCL-based approaches in ERC are impeded by the constraint of large batch sizes and the lack of compatibility with most existing ERC models. To address these challenges, we propose an efficient and model-agnostic SCL framework named Supervised Sample-Label Contrastive Learning with Soft-HGR Maximal Correlation (SSLCL), which eliminates the need for a large batch size and can be seamlessly integrated with existing ERC models without introducing any model-specific assumptions. Specifically, we introduce a novel perspective on utilizing label representations by projecting discrete labels into dense embeddings through a shallow multilayer perceptron, and formulate the training objective to maximize the similarity between sample features and their corresponding ground-truth label embeddings, while minimizing the similarity between sample features and label embeddings of disparate classes. Moreover, we innovatively adopt the Soft-HGR maximal correlation as a measure of similarity between sample features and label embeddings, leading to significant performance improvements over conventional similarity measures. Additionally, multimodal cues of utterances are effectively leveraged by SSLCL as data augmentations to boost model performances. Extensive experiments on two ERC benchmark datasets, IEMOCAP and MELD, demonstrate the compatibility and superiority of our proposed SSLCL framework compared to existing state-of-the-art SCL methods. Our code is available at \url{https://github.com/TaoShi1998/SSLCL}.
Reducing Information Loss for Spiking Neural Networks
Jul 10, 2023



The Spiking Neural Network (SNN) has attracted more and more attention recently. It adopts binary spike signals to transmit information. Benefitting from the information passing paradigm of SNNs, the multiplications of activations and weights can be replaced by additions, which are more energy-efficient. However, its ``Hard Reset" mechanism for the firing activity would ignore the difference among membrane potentials when the membrane potential is above the firing threshold, causing information loss. Meanwhile, quantifying the membrane potential to 0/1 spikes at the firing instants will inevitably introduce the quantization error thus bringing about information loss too. To address these problems, we propose to use the ``Soft Reset" mechanism for the supervised training-based SNNs, which will drive the membrane potential to a dynamic reset potential according to its magnitude, and Membrane Potential Rectifier (MPR) to reduce the quantization error via redistributing the membrane potential to a range close to the spikes. Results show that the SNNs with the ``Soft Reset" mechanism and MPR outperform their vanilla counterparts on both static and dynamic datasets.
Personalized Federated Learning with Feature Alignment and Classifier Collaboration
Jun 20, 2023



Data heterogeneity is one of the most challenging issues in federated learning, which motivates a variety of approaches to learn personalized models for participating clients. One such approach in deep neural networks based tasks is employing a shared feature representation and learning a customized classifier head for each client. However, previous works do not utilize the global knowledge during local representation learning and also neglect the fine-grained collaboration between local classifier heads, which limit the model generalization ability. In this work, we conduct explicit local-global feature alignment by leveraging global semantic knowledge for learning a better representation. Moreover, we quantify the benefit of classifier combination for each client as a function of the combining weights and derive an optimization problem for estimating optimal weights. Finally, extensive evaluation results on benchmark datasets with various heterogeneous data scenarios demonstrate the effectiveness of our proposed method. Code is available at https://github.com/JianXu95/FedPAC
Real Spike: Learning Real-valued Spikes for Spiking Neural Networks
Oct 13, 2022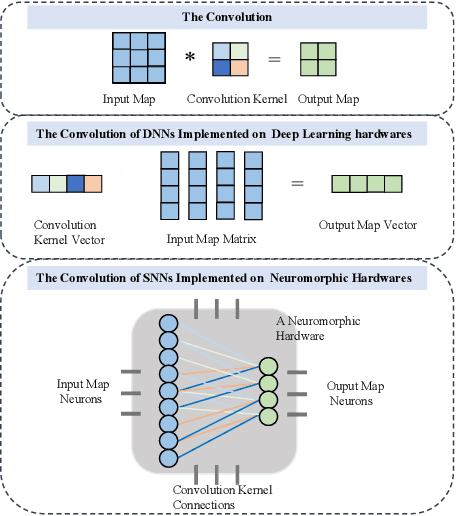
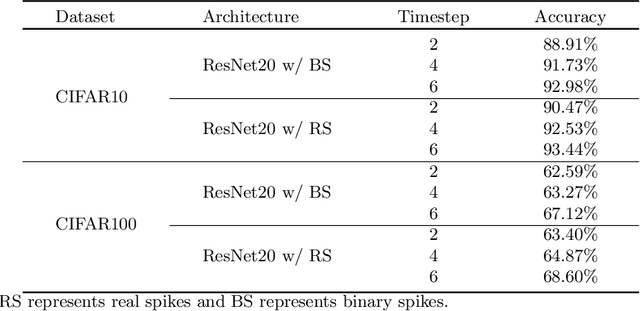
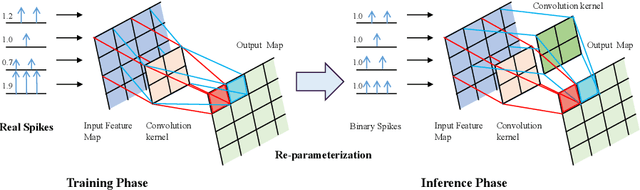
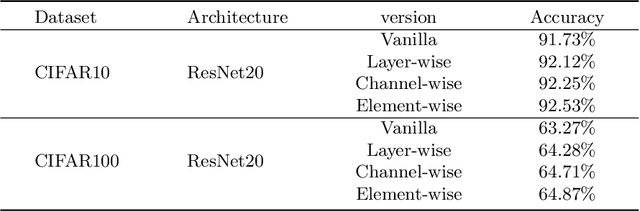
Brain-inspired spiking neural networks (SNNs) have recently drawn more and more attention due to their event-driven and energy-efficient characteristics. The integration of storage and computation paradigm on neuromorphic hardwares makes SNNs much different from Deep Neural Networks (DNNs). In this paper, we argue that SNNs may not benefit from the weight-sharing mechanism, which can effectively reduce parameters and improve inference efficiency in DNNs, in some hardwares, and assume that an SNN with unshared convolution kernels could perform better. Motivated by this assumption, a training-inference decoupling method for SNNs named as Real Spike is proposed, which not only enjoys both unshared convolution kernels and binary spikes in inference-time but also maintains both shared convolution kernels and Real-valued Spikes during training. This decoupling mechanism of SNN is realized by a re-parameterization technique. Furthermore, based on the training-inference-decoupled idea, a series of different forms for implementing Real Spike on different levels are presented, which also enjoy shared convolutions in the inference and are friendly to both neuromorphic and non-neuromorphic hardware platforms. A theoretical proof is given to clarify that the Real Spike-based SNN network is superior to its vanilla counterpart. Experimental results show that all different Real Spike versions can consistently improve the SNN performance. Moreover, the proposed method outperforms the state-of-the-art models on both non-spiking static and neuromorphic datasets.
An Information-theoretic Method for Collaborative Distributed Learning with Limited Communication
May 18, 2022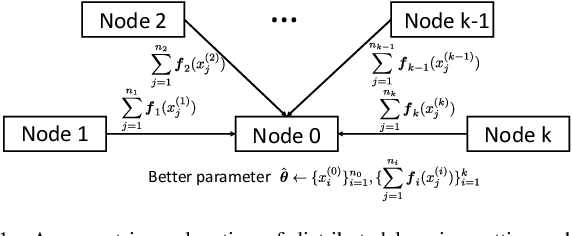
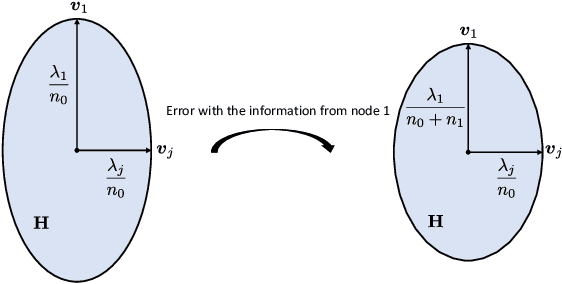

In this paper, we study the information transmission problem under the distributed learning framework, where each worker node is merely permitted to transmit a $m$-dimensional statistic to improve learning results of the target node. Specifically, we evaluate the corresponding expected population risk (EPR) under the regime of large sample sizes. We prove that the performance can be enhanced since the transmitted statistics contribute to estimating the underlying distribution under the mean square error measured by the EPR norm matrix. Accordingly, the transmitted statistics correspond to the eigenvectors of this matrix, and the desired transmission allocates these eigenvectors among the statistics such that the EPR is minimal. Moreover, we provide the analytical solution of the desired statistics for single-node and two-node transmission, where a geometrical interpretation is given to explain the eigenvector selection. For the general case, an efficient algorithm that can output the allocation solution is developed based on the node partitions.
Differentially Private ERM Based on Data Perturbation
Feb 20, 2020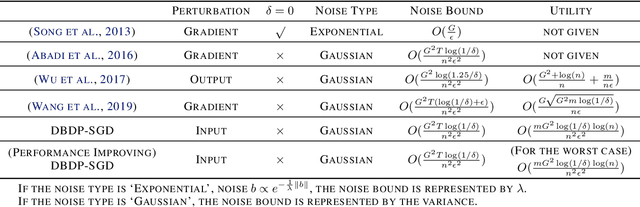
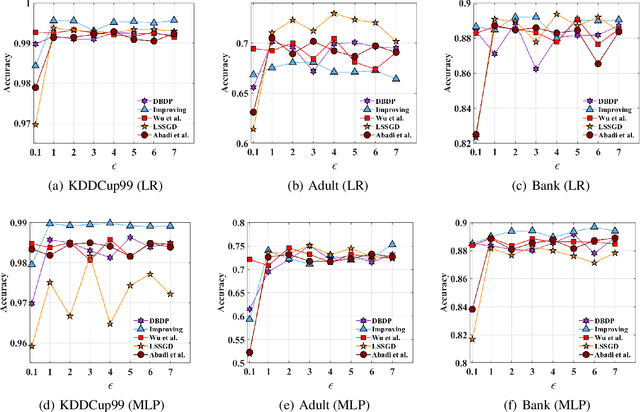
In this paper, after observing that different training data instances affect the machine learning model to different extents, we attempt to improve the performance of differentially private empirical risk minimization (DP-ERM) from a new perspective. Specifically, we measure the contributions of various training data instances on the final machine learning model, and select some of them to add random noise. Considering that the key of our method is to measure each data instance separately, we propose a new `Data perturbation' based (DB) paradigm for DP-ERM: adding random noise to the original training data and achieving ($\epsilon,\delta$)-differential privacy on the final machine learning model, along with the preservation on the original data. By introducing the Influence Function (IF), we quantitatively measure the impact of the training data on the final model. Theoretical and experimental results show that our proposed DBDP-ERM paradigm enhances the model performance significantly.
Input Perturbation: A New Paradigm between Central and Local Differential Privacy
Feb 20, 2020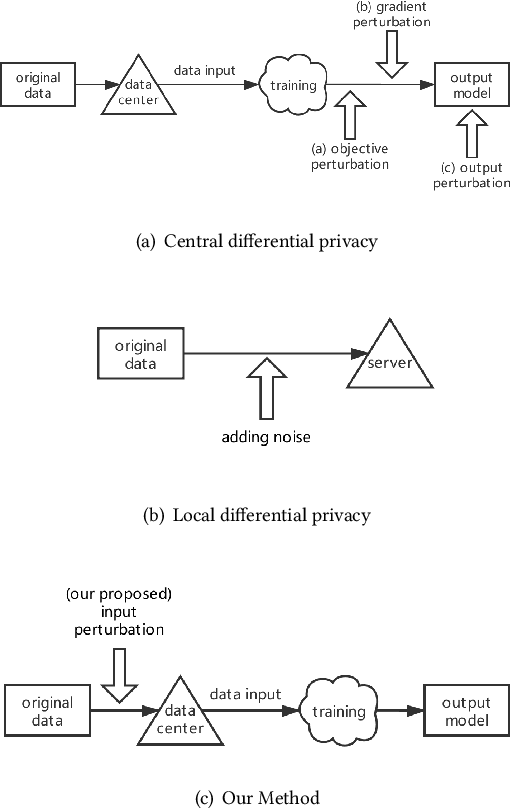
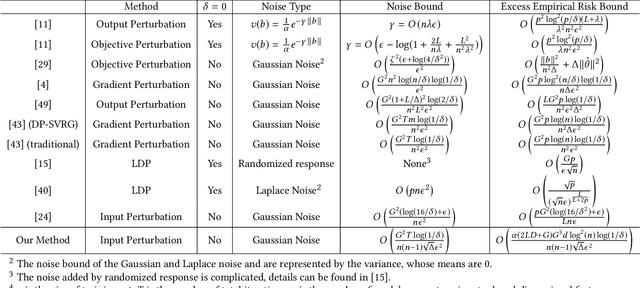
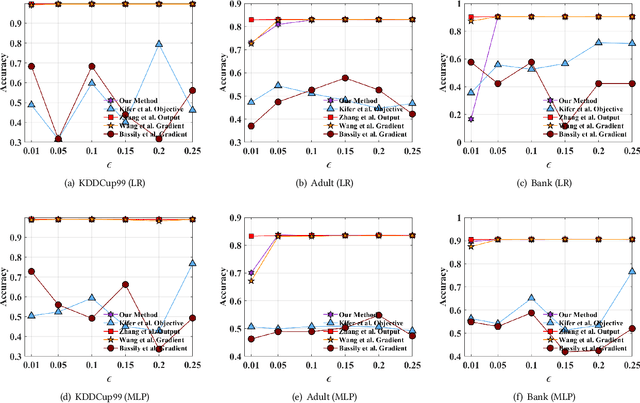
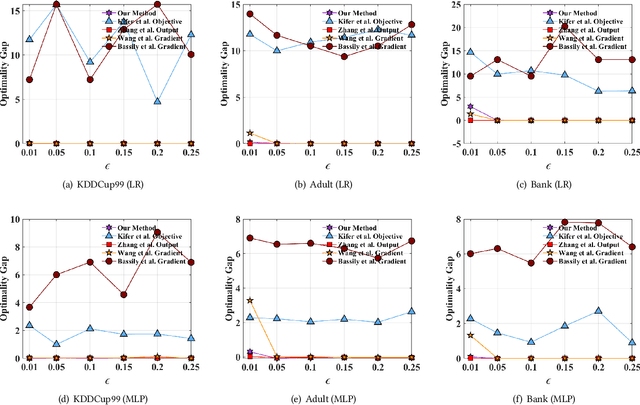
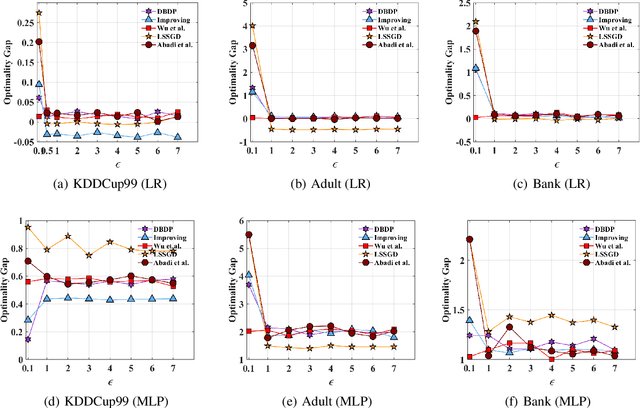
Traditionally, there are two models on differential privacy: the central model and the local model. The central model focuses on the machine learning model and the local model focuses on the training data. In this paper, we study the \textit{input perturbation} method in differentially private empirical risk minimization (DP-ERM), preserving privacy of the central model. By adding noise to the original training data and training with the `perturbed data', we achieve ($\epsilon$,$\delta$)-differential privacy on the final model, along with some kind of privacy on the original data. We observe that there is an interesting connection between the local model and the central model: the perturbation on the original data causes the perturbation on the gradient, and finally the model parameters. This observation means that our method builds a bridge between local and central model, protecting the data, the gradient and the model simultaneously, which is more superior than previous central methods. Detailed theoretical analysis and experiments show that our method achieves almost the same (or even better) performance as some of the best previous central methods with more protections on privacy, which is an attractive result. Moreover, we extend our method to a more general case: the loss function satisfies the Polyak-Lojasiewicz condition, which is more general than strong convexity, the constraint on the loss function in most previous work.