 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Structured Instance Graph for Distilling Object Detectors
Sep 27, 2021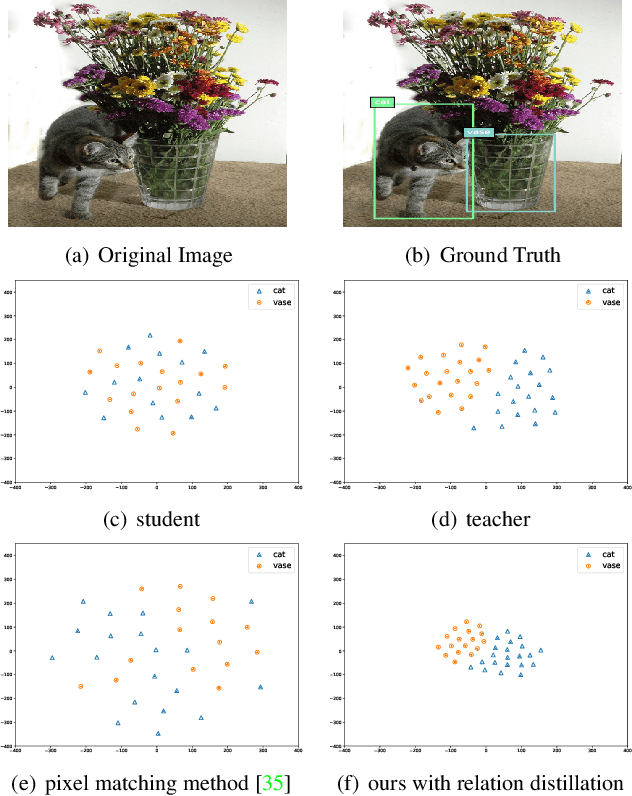
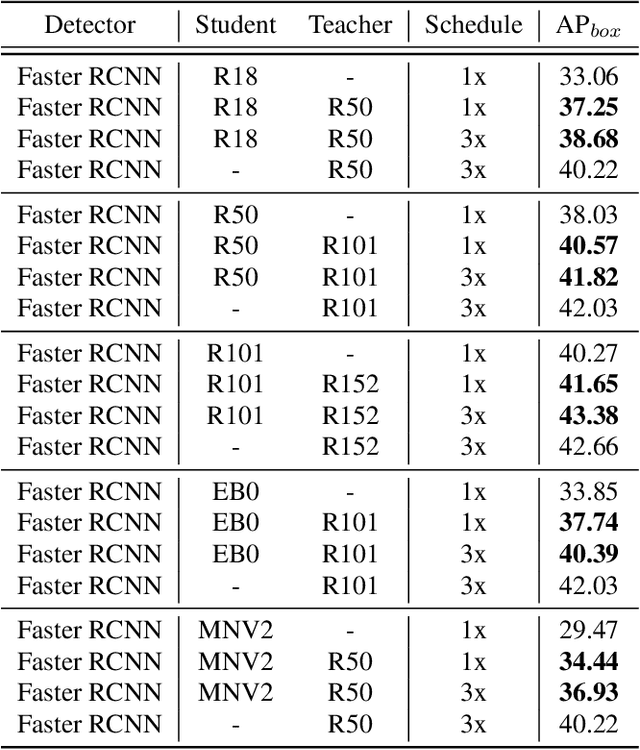

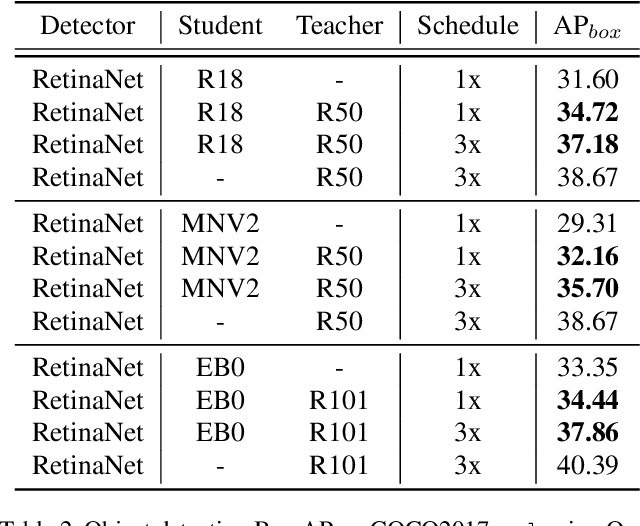
Effectively structuring deep knowledge plays a pivotal role in transfer from teacher to student, especially in semantic vision tasks. In this paper, we present a simple knowledge structure to exploit and encode information inside the detection system to facilitate detector knowledge distillation. Specifically, aiming at solving the feature imbalance problem while further excavating the missing relation inside semantic instances, we design a graph whose nodes correspond to instance proposal-level features and edges represent the relation between nodes. To further refine this graph, we design an adaptive background loss weight to reduce node noise and background samples mining to prune trivial edges. We transfer the entire graph as encoded knowledge representation from teacher to student, capturing local and global information simultaneously. We achieve new state-of-the-art results on the challenging COCO object detection task with diverse student-teacher pairs on both one- and two-stage detectors. We also experiment with instance segmentation to demonstrate robustness of our method. It is notable that distilled Faster R-CNN with ResNet18-FPN and ResNet50-FPN yields 38.68 and 41.82 Box AP respectively on the COCO benchmark, Faster R-CNN with ResNet101-FPN significantly achieves 43.38 AP, which outperforms ResNet152-FPN teacher about 0.7 AP. Code: https://github.com/dvlab-research/Dsig.
CancerBERT: a BERT model for Extracting Breast Cancer Phenotypes from Electronic Health Records
Aug 25, 2021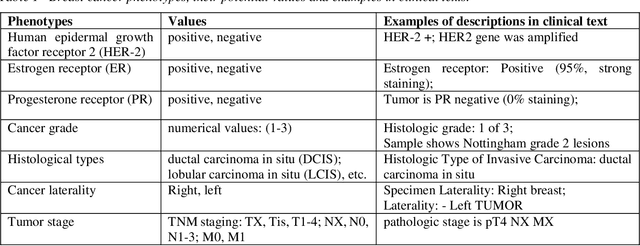

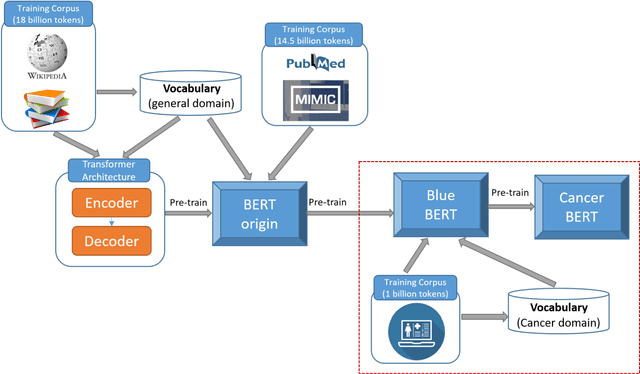
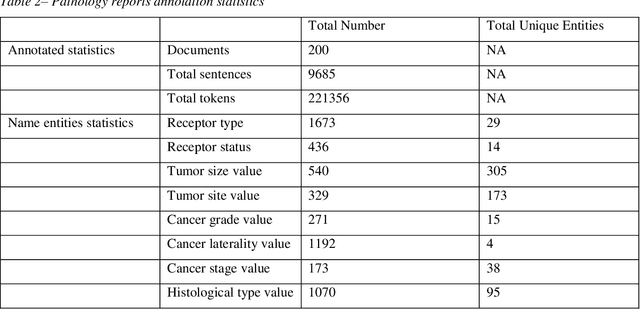
Accurate extraction of breast cancer patients' phenotypes is important for clinical decision support and clinical research. Current models do not take full advantage of cancer domain-specific corpus, whether pre-training Bidirectional Encoder Representations from Transformer model on cancer-specific corpus could improve the performances of extracting breast cancer phenotypes from texts data remains to be explored. The objective of this study is to develop and evaluate the CancerBERT model for extracting breast cancer phenotypes from clinical texts in electronic health records. This data used in the study included 21,291 breast cancer patients diagnosed from 2010 to 2020, patients' clinical notes and pathology reports were collected from the University of Minnesota Clinical Data Repository (UMN). Results: About 3 million clinical notes and pathology reports in electronic health records for 21,291 breast cancer patients were collected to train the CancerBERT model. 200 pathology reports and 50 clinical notes of breast cancer patients that contain 9,685 sentences and 221,356 tokens were manually annotated by two annotators. 20% of the annotated data was used as a test set. Our CancerBERT model achieved the best performance with macro F1 scores equal to 0.876 (95% CI, 0.896-0.902) for exact match and 0.904 (95% CI, 0.896-0.902) for the lenient match. The NER models we developed would facilitate the automated information extraction from clinical texts to further help clinical decision support. Conclusions and Relevance: In this study, we focused on the breast cancer-related concepts extraction from EHR data and obtained a comprehensive annotated dataset that contains 7 types of breast cancer-related concepts. The CancerBERT model with customized vocabulary could significantly improve the performance for extracting breast cancer phenotypes from clinical texts.
Fully Convolutional Networks for Panoptic Segmentation with Point-based Supervision
Aug 18, 2021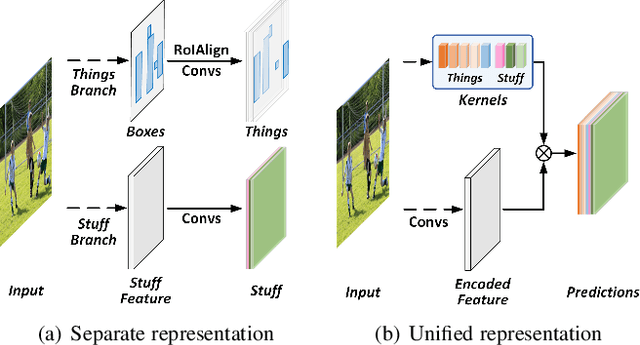
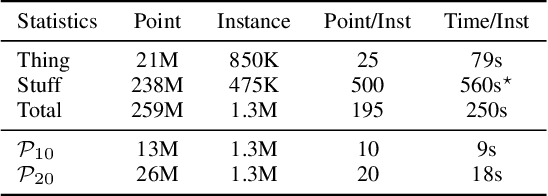
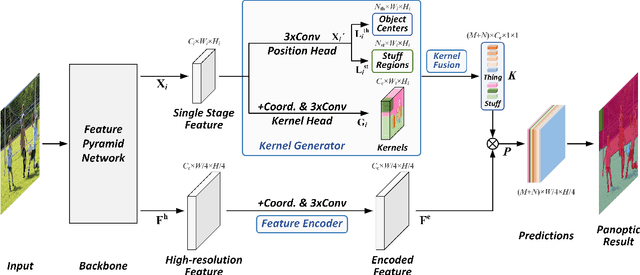
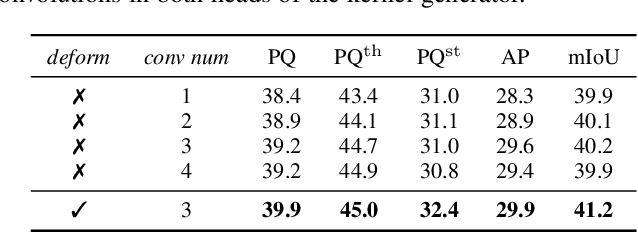
In this paper, we present a conceptually simple, strong, and efficient framework for fully- and weakly-supervised panoptic segmentation, called Panoptic FCN. Our approach aims to represent and predict foreground things and background stuff in a unified fully convolutional pipeline, which can be optimized with point-based fully or weak supervision. In particular, Panoptic FCN encodes each object instance or stuff category with the proposed kernel generator and produces the prediction by convolving the high-resolution feature directly. With this approach, instance-aware and semantically consistent properties for things and stuff can be respectively satisfied in a simple generate-kernel-then-segment workflow. Without extra boxes for localization or instance separation, the proposed approach outperforms the previous box-based and -free models with high efficiency. Furthermore, we propose a new form of point-based annotation for weakly-supervised panoptic segmentation. It only needs several random points for both things and stuff, which dramatically reduces the annotation cost of human. The proposed Panoptic FCN is also proved to have much superior performance in this weakly-supervised setting, which achieves 82% of the fully-supervised performance with only 20 randomly annotated points per instance. Extensive experiments demonstrate the effectiveness and efficiency of Panoptic FCN on COCO, VOC 2012, Cityscapes, and Mapillary Vistas datasets. And it sets up a new leading benchmark for both fully- and weakly-supervised panoptic segmentation. Our code and models are made publicly available at https://github.com/dvlab-research/PanopticFCN
A fast asynchronous MCMC sampler for sparse Bayesian inference
Aug 14, 2021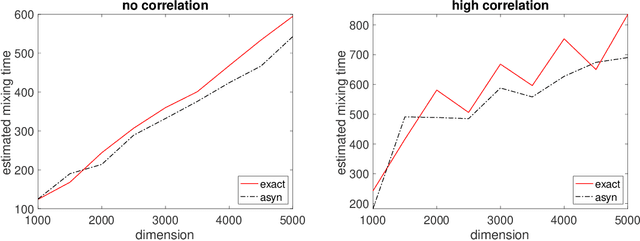

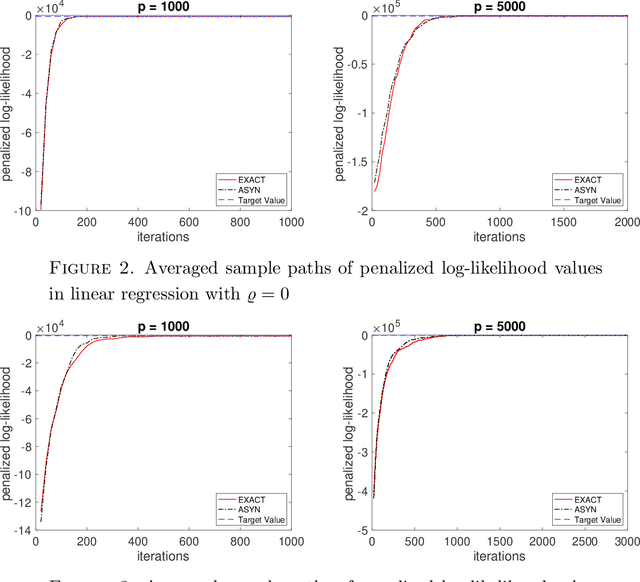
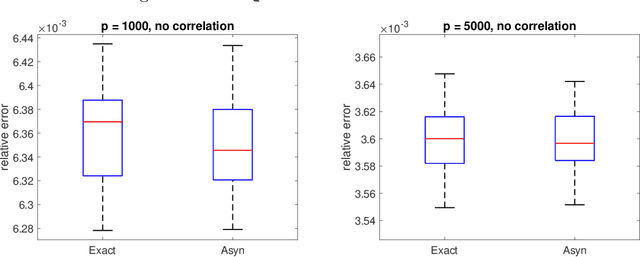
We propose a very fast approximate Markov Chain Monte Carlo (MCMC) sampling framework that is applicable to a large class of sparse Bayesian inference problems, where the computational cost per iteration in several models is of order $O(ns)$, where $n$ is the sample size, and $s$ the underlying sparsity of the model. This cost can be further reduced by data sub-sampling when stochastic gradient Langevin dynamics are employed. The algorithm is an extension of the asynchronous Gibbs sampler of Johnson et al. (2013), but can be viewed from a statistical perspective as a form of Bayesian iterated sure independent screening (Fan et al. (2009)). We show that in high-dimensional linear regression problems, the Markov chain generated by the proposed algorithm admits an invariant distribution that recovers correctly the main signal with high probability under some statistical assumptions. Furthermore we show that its mixing time is at most linear in the number of regressors. We illustrate the algorithm with several models.
Conditional Temporal Variational AutoEncoder for Action Video Prediction
Aug 12, 2021

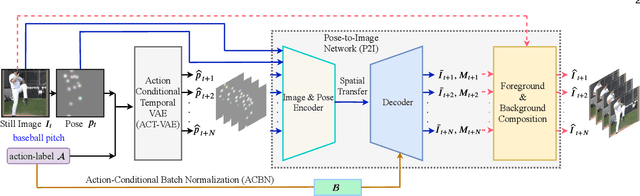

To synthesize a realistic action sequence based on a single human image, it is crucial to model both motion patterns and diversity in the action video. This paper proposes an Action Conditional Temporal Variational AutoEncoder (ACT-VAE) to improve motion prediction accuracy and capture movement diversity. ACT-VAE predicts pose sequences for an action clips from a single input image. It is implemented as a deep generative model that maintains temporal coherence according to the action category with a novel temporal modeling on latent space. Further, ACT-VAE is a general action sequence prediction framework. When connected with a plug-and-play Pose-to-Image (P2I) network, ACT-VAE can synthesize image sequences. Extensive experiments bear out our approach can predict accurate pose and synthesize realistic image sequences, surpassing state-of-the-art approaches. Compared to existing methods, ACT-VAE improves model accuracy and preserves diversity.
Collaborative Visual Navigation
Jul 20, 2021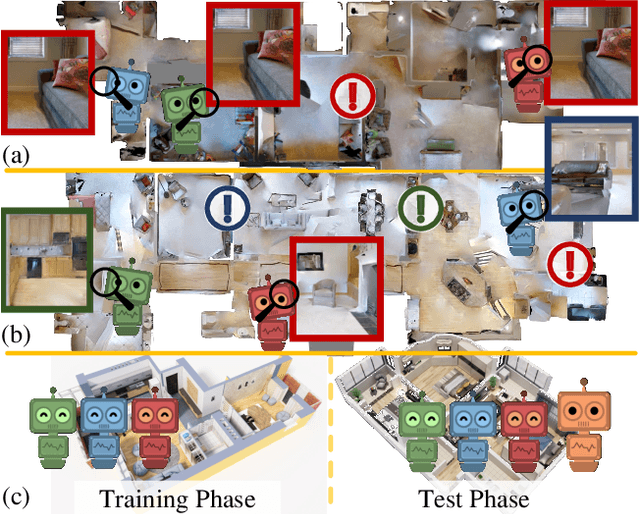
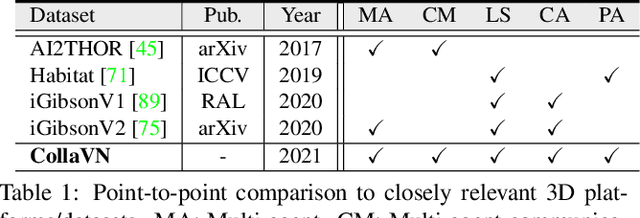
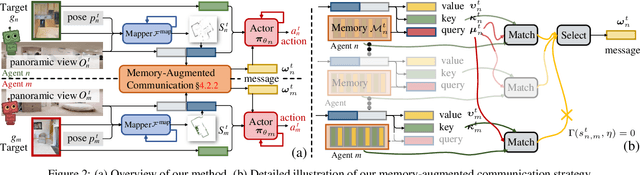
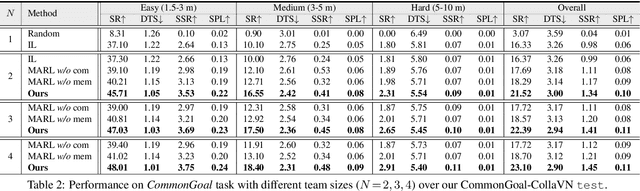
As a fundamental problem for Artificial Intelligence, multi-agent system (MAS) is making rapid progress, mainly driven by multi-agent reinforcement learning (MARL) techniques. However, previous MARL methods largely focused on grid-world like or game environments; MAS in visually rich environments has remained less explored. To narrow this gap and emphasize the crucial role of perception in MAS, we propose a large-scale 3D dataset, CollaVN, for multi-agent visual navigation (MAVN). In CollaVN, multiple agents are entailed to cooperatively navigate across photo-realistic environments to reach target locations. Diverse MAVN variants are explored to make our problem more general. Moreover, a memory-augmented communication framework is proposed. Each agent is equipped with a private, external memory to persistently store communication information. This allows agents to make better use of their past communication information, enabling more efficient collaboration and robust long-term planning. In our experiments, several baselines and evaluation metrics are designed. We also empirically verify the efficacy of our proposed MARL approach across different MAVN task settings.
Scalable Gaussian Processes for Data-Driven Design using Big Data with Categorical Factors
Jun 30, 2021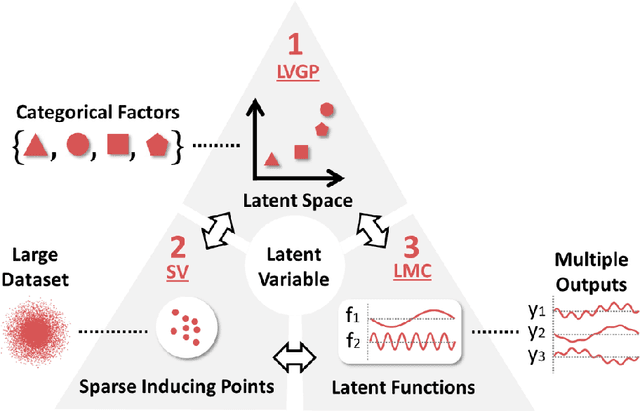

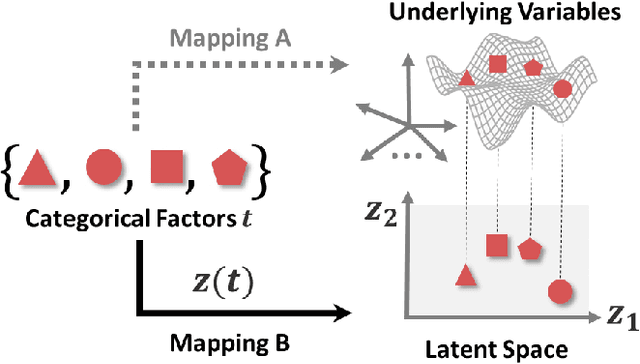
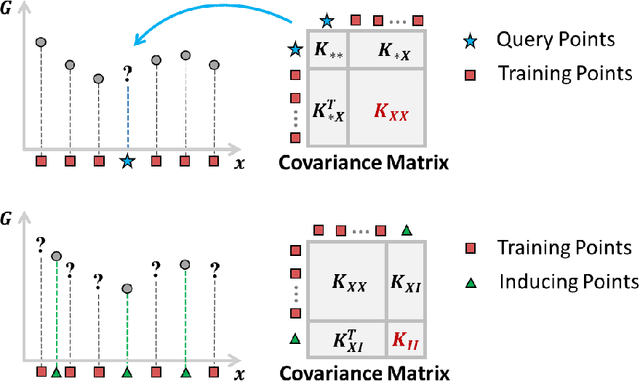
Scientific and engineering problems often require the use of artificial intelligence to aid understanding and the search for promising designs. While Gaussian processes (GP) stand out as easy-to-use and interpretable learners, they have difficulties in accommodating big datasets, categorical inputs, and multiple responses, which has become a common challenge for a growing number of data-driven design applications. In this paper, we propose a GP model that utilizes latent variables and functions obtained through variational inference to address the aforementioned challenges simultaneously. The method is built upon the latent variable Gaussian process (LVGP) model where categorical factors are mapped into a continuous latent space to enable GP modeling of mixed-variable datasets. By extending variational inference to LVGP models, the large training dataset is replaced by a small set of inducing points to address the scalability issue. Output response vectors are represented by a linear combination of independent latent functions, forming a flexible kernel structure to handle multiple responses that might have distinct behaviors. Comparative studies demonstrate that the proposed method scales well for large datasets with over 10^4 data points, while outperforming state-of-the-art machine learning methods without requiring much hyperparameter tuning. In addition, an interpretable latent space is obtained to draw insights into the effect of categorical factors, such as those associated with building blocks of architectures and element choices in metamaterial and materials design. Our approach is demonstrated for machine learning of ternary oxide materials and topology optimization of a multiscale compliant mechanism with aperiodic microstructures and multiple materials.
Semi-supervised Semantic Segmentation with Directional Context-aware Consistency
Jun 27, 2021
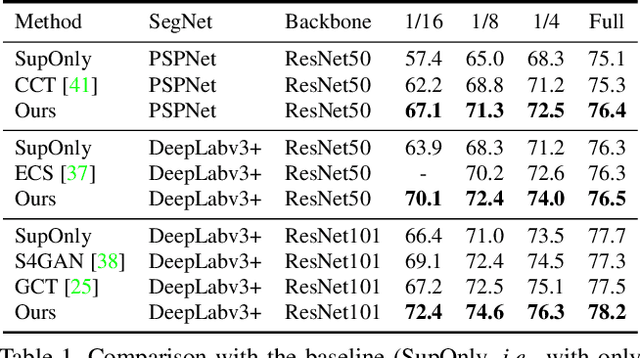
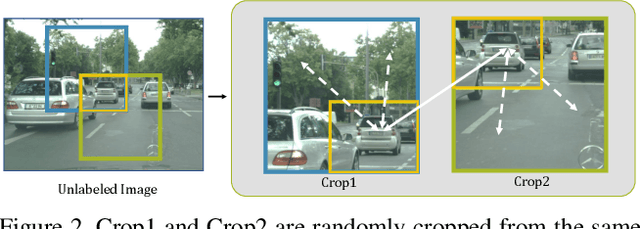
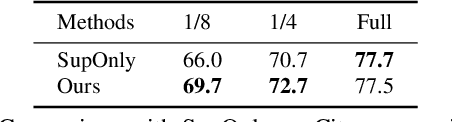
Semantic segmentation has made tremendous progress in recent years. However, satisfying performance highly depends on a large number of pixel-level annotations. Therefore, in this paper, we focus on the semi-supervised segmentation problem where only a small set of labeled data is provided with a much larger collection of totally unlabeled images. Nevertheless, due to the limited annotations, models may overly rely on the contexts available in the training data, which causes poor generalization to the scenes unseen before. A preferred high-level representation should capture the contextual information while not losing self-awareness. Therefore, we propose to maintain the context-aware consistency between features of the same identity but with different contexts, making the representations robust to the varying environments. Moreover, we present the Directional Contrastive Loss (DC Loss) to accomplish the consistency in a pixel-to-pixel manner, only requiring the feature with lower quality to be aligned towards its counterpart. In addition, to avoid the false-negative samples and filter the uncertain positive samples, we put forward two sampling strategies. Extensive experiments show that our simple yet effective method surpasses current state-of-the-art methods by a large margin and also generalizes well with extra image-level annotations.
Multi-stage Optimization based Adversarial Training
Jun 26, 2021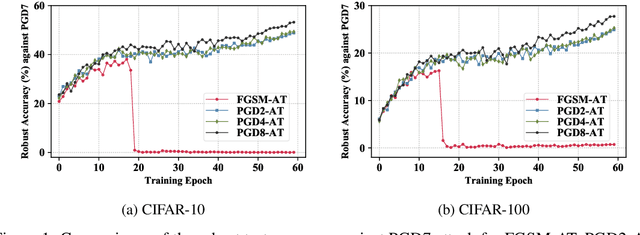
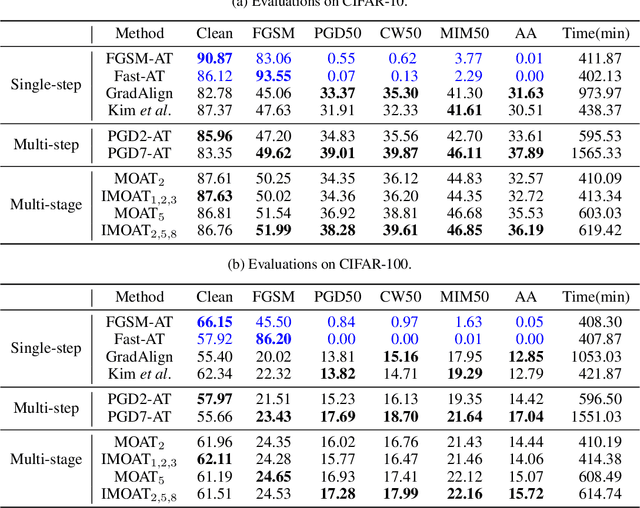
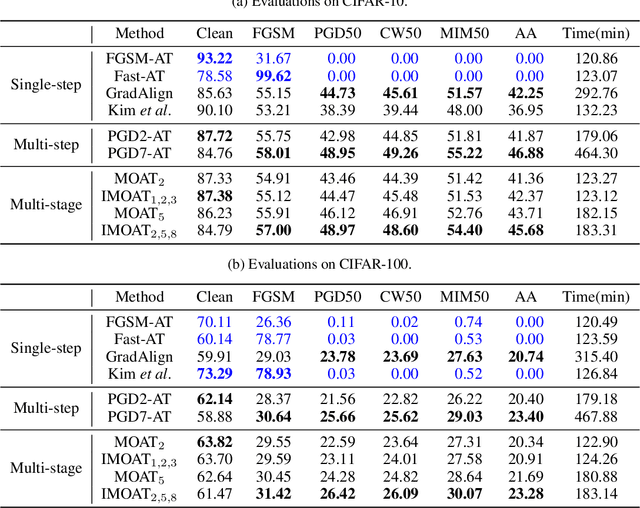
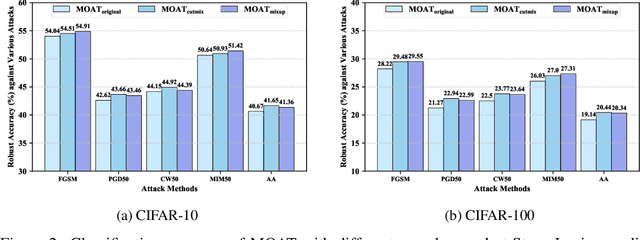
In the field of adversarial robustness, there is a common practice that adopts the single-step adversarial training for quickly developing adversarially robust models. However, the single-step adversarial training is most likely to cause catastrophic overfitting, as after a few training epochs it will be hard to generate strong adversarial examples to continuously boost the adversarial robustness. In this work, we aim to avoid the catastrophic overfitting by introducing multi-step adversarial examples during the single-step adversarial training. Then, to balance the large training overhead of generating multi-step adversarial examples, we propose a Multi-stage Optimization based Adversarial Training (MOAT) method that periodically trains the model on mixed benign examples, single-step adversarial examples, and multi-step adversarial examples stage by stage. In this way, the overall training overhead is reduced significantly, meanwhile, the model could avoid catastrophic overfitting. Extensive experiments on CIFAR-10 and CIFAR-100 datasets demonstrate that under similar amount of training overhead, the proposed MOAT exhibits better robustness than either single-step or multi-step adversarial training methods.
Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
Jun 23, 2021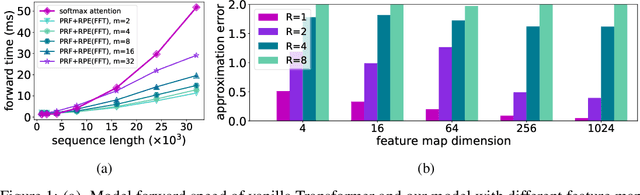
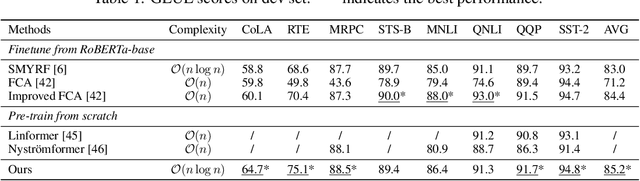


The attention module, which is a crucial component in Transformer, cannot scale efficiently to long sequences due to its quadratic complexity. Many works focus on approximating the dot-then-exponentiate softmax function in the original attention, leading to sub-quadratic or even linear-complexity Transformer architectures. However, we show that these methods cannot be applied to more powerful attention modules that go beyond the dot-then-exponentiate style, e.g., Transformers with relative positional encoding (RPE). Since in many state-of-the-art models, relative positional encoding is used as default, designing efficient Transformers that can incorporate RPE is appealing. In this paper, we propose a novel way to accelerate attention calculation for Transformers with RPE on top of the kernelized attention. Based upon the observation that relative positional encoding forms a Toeplitz matrix, we mathematically show that kernelized attention with RPE can be calculated efficiently using Fast Fourier Transform (FFT). With FFT, our method achieves $\mathcal{O}(n\log n)$ time complexity. Interestingly, we further demonstrate that properly using relative positional encoding can mitigate the training instability problem of vanilla kernelized attention. On a wide range of tasks, we empirically show that our models can be trained from scratch without any optimization issues. The learned model performs better than many efficient Transformer variants and is faster than standard Transformer in the long-sequence regime.