 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbracing Uncertainty: Adaptive Vague Preference Policy Learning for Multi-round Conversational Recommendation
Jun 07, 2023



Conversational recommendation systems (CRS) effectively address information asymmetry by dynamically eliciting user preferences through multi-turn interactions. Existing CRS widely assumes that users have clear preferences. Under this assumption, the agent will completely trust the user feedback and treat the accepted or rejected signals as strong indicators to filter items and reduce the candidate space, which may lead to the problem of over-filtering. However, in reality, users' preferences are often vague and volatile, with uncertainty about their desires and changing decisions during interactions. To address this issue, we introduce a novel scenario called Vague Preference Multi-round Conversational Recommendation (VPMCR), which considers users' vague and volatile preferences in CRS.VPMCR employs a soft estimation mechanism to assign a non-zero confidence score for all candidate items to be displayed, naturally avoiding the over-filtering problem. In the VPMCR setting, we introduce an solution called Adaptive Vague Preference Policy Learning (AVPPL), which consists of two main components: Uncertainty-aware Soft Estimation (USE) and Uncertainty-aware Policy Learning (UPL). USE estimates the uncertainty of users' vague feedback and captures their dynamic preferences using a choice-based preferences extraction module and a time-aware decaying strategy. UPL leverages the preference distribution estimated by USE to guide the conversation and adapt to changes in users' preferences to make recommendations or ask for attributes. Our extensive experiments demonstrate the effectiveness of our method in the VPMCR scenario, highlighting its potential for practical applications and improving the overall performance and applicability of CRS in real-world settings, particularly for users with vague or dynamic preferences.
Tram: A Token-level Retrieval-augmented Mechanism for Source Code Summarization
May 18, 2023



Automatically generating human-readable text describing the functionality of a program is the intent of source code summarization. Although Neural Language Models achieve significant performance in this field, an emerging trend is combining neural models with external knowledge. Most previous approaches rely on the sentence-level retrieval and combination paradigm (retrieval of similar code snippets and use of the corresponding code and summary pairs) on the encoder side. However, this paradigm is coarse-grained and cannot directly take advantage of the high-quality retrieved summary tokens on the decoder side. In this paper, we explore a fine-grained token-level retrieval-augmented mechanism on the decoder side to help the vanilla neural model generate a better code summary. Furthermore, to mitigate the limitation of token-level retrieval on capturing contextual code semantics, we propose to integrate code semantics into summary tokens. Extensive experiments and human evaluation reveal that our token-level retrieval-augmented approach significantly improves performance and is more interpretive.
SkillQG: Learning to Generate Question for Reading Comprehension Assessment
May 08, 2023We present $\textbf{$\texttt{SkillQG}$}$: a question generation framework with controllable comprehension types for assessing and improving machine reading comprehension models. Existing question generation systems widely differentiate questions by $\textit{literal}$ information such as question words and answer types to generate semantically relevant questions for a given context. However, they rarely consider the $\textit{comprehension}$ nature of questions, i.e. the different comprehension capabilities embodied by different questions. In comparison, our $\texttt{SkillQG}$ is able to tailor a fine-grained assessment and improvement to the capabilities of question answering models built on it. Specifically, we first frame the comprehension type of questions based on a hierarchical skill-based schema, then formulate $\texttt{SkillQG}$ as a skill-conditioned question generator. Furthermore, to improve the controllability of generation, we augment the input text with question focus and skill-specific knowledge, which are constructed by iteratively prompting the pre-trained language models. Empirical results demonstrate that $\texttt{SkillQG}$ outperforms baselines in terms of quality, relevance, and skill-controllability while showing a promising performance boost in downstream question answering task.
KGTrust: Evaluating Trustworthiness of SIoT via Knowledge Enhanced Graph Neural Networks
Feb 22, 2023



Social Internet of Things (SIoT), a promising and emerging paradigm that injects the notion of social networking into smart objects (i.e., things), paving the way for the next generation of Internet of Things. However, due to the risks and uncertainty, a crucial and urgent problem to be settled is establishing reliable relationships within SIoT, that is, trust evaluation. Graph neural networks for trust evaluation typically adopt a straightforward way such as one-hot or node2vec to comprehend node characteristics, which ignores the valuable semantic knowledge attached to nodes. Moreover, the underlying structure of SIoT is usually complex, including both the heterogeneous graph structure and pairwise trust relationships, which renders hard to preserve the properties of SIoT trust during information propagation. To address these aforementioned problems, we propose a novel knowledge-enhanced graph neural network (KGTrust) for better trust evaluation in SIoT. Specifically, we first extract useful knowledge from users' comment behaviors and external structured triples related to object descriptions, in order to gain a deeper insight into the semantics of users and objects. Furthermore, we introduce a discriminative convolutional layer that utilizes heterogeneous graph structure, node semantics, and augmented trust relationships to learn node embeddings from the perspective of a user as a trustor or a trustee, effectively capturing multi-aspect properties of SIoT trust during information propagation. Finally, a trust prediction layer is developed to estimate the trust relationships between pairwise nodes. Extensive experiments on three public datasets illustrate the superior performance of KGTrust over state-of-the-art methods.
Theoretical Characterization of How Neural Network Pruning Affects its Generalization
Jan 05, 2023



It has been observed in practice that applying pruning-at-initialization methods to neural networks and training the sparsified networks can not only retain the testing performance of the original dense models, but also sometimes even slightly boost the generalization performance. Theoretical understanding for such experimental observations are yet to be developed. This work makes the first attempt to study how different pruning fractions affect the model's gradient descent dynamics and generalization. Specifically, this work considers a classification task for overparameterized two-layer neural networks, where the network is randomly pruned according to different rates at the initialization. It is shown that as long as the pruning fraction is below a certain threshold, gradient descent can drive the training loss toward zero and the network exhibits good generalization performance. More surprisingly, the generalization bound gets better as the pruning fraction gets larger. To complement this positive result, this work further shows a negative result: there exists a large pruning fraction such that while gradient descent is still able to drive the training loss toward zero (by memorizing noise), the generalization performance is no better than random guessing. This further suggests that pruning can change the feature learning process, which leads to the performance drop of the pruned neural network.
T2-GNN: Graph Neural Networks for Graphs with Incomplete Features and Structure via Teacher-Student Distillation
Dec 24, 2022



Graph Neural Networks (GNNs) have been a prevailing technique for tackling various analysis tasks on graph data. A key premise for the remarkable performance of GNNs relies on complete and trustworthy initial graph descriptions (i.e., node features and graph structure), which is often not satisfied since real-world graphs are often incomplete due to various unavoidable factors. In particular, GNNs face greater challenges when both node features and graph structure are incomplete at the same time. The existing methods either focus on feature completion or structure completion. They usually rely on the matching relationship between features and structure, or employ joint learning of node representation and feature (or structure) completion in the hope of achieving mutual benefit. However, recent studies confirm that the mutual interference between features and structure leads to the degradation of GNN performance. When both features and structure are incomplete, the mismatch between features and structure caused by the missing randomness exacerbates the interference between the two, which may trigger incorrect completions that negatively affect node representation. To this end, in this paper we propose a general GNN framework based on teacher-student distillation to improve the performance of GNNs on incomplete graphs, namely T2-GNN. To avoid the interference between features and structure, we separately design feature-level and structure-level teacher models to provide targeted guidance for student model (base GNNs, such as GCN) through distillation. Then we design two personalized methods to obtain well-trained feature and structure teachers. To ensure that the knowledge of the teacher model is comprehensively and effectively distilled to the student model, we further propose a dual distillation mode to enable the student to acquire as much expert knowledge as possible.
Human-instructed Deep Hierarchical Generative Learning for Automated Urban Planning
Dec 01, 2022The essential task of urban planning is to generate the optimal land-use configuration of a target area. However, traditional urban planning is time-consuming and labor-intensive. Deep generative learning gives us hope that we can automate this planning process and come up with the ideal urban plans. While remarkable achievements have been obtained, they have exhibited limitations in lacking awareness of: 1) the hierarchical dependencies between functional zones and spatial grids; 2) the peer dependencies among functional zones; and 3) human regulations to ensure the usability of generated configurations. To address these limitations, we develop a novel human-instructed deep hierarchical generative model. We rethink the urban planning generative task from a unique functionality perspective, where we summarize planning requirements into different functionality projections for better urban plan generation. To this end, we develop a three-stage generation process from a target area to zones to grids. The first stage is to label the grids of a target area with latent functionalities to discover functional zones. The second stage is to perceive the planning requirements to form urban functionality projections. We propose a novel module: functionalizer to project the embedding of human instructions and geospatial contexts to the zone-level plan to obtain such projections. Each projection includes the information of land-use portfolios and the structural dependencies across spatial grids in terms of a specific urban function. The third stage is to leverage multi-attentions to model the zone-zone peer dependencies of the functionality projections to generate grid-level land-use configurations. Finally, we present extensive experiments to demonstrate the effectiveness of our framework.
HigeNet: A Highly Efficient Modeling for Long Sequence Time Series Prediction in AIOps
Nov 13, 2022



Modern IT system operation demands the integration of system software and hardware metrics. As a result, it generates a massive amount of data, which can be potentially used to make data-driven operational decisions. In the basic form, the decision model needs to monitor a large set of machine data, such as CPU utilization, allocated memory, disk and network latency, and predicts the system metrics to prevent performance degradation. Nevertheless, building an effective prediction model in this scenario is rather challenging as the model has to accurately capture the long-range coupling dependency in the Multivariate Time-Series (MTS). Moreover, this model needs to have low computational complexity and can scale efficiently to the dimension of data available. In this paper, we propose a highly efficient model named HigeNet to predict the long-time sequence time series. We have deployed the HigeNet on production in the D-matrix platform. We also provide offline evaluations on several publicly available datasets as well as one online dataset to demonstrate the model's efficacy. The extensive experiments show that training time, resource usage and accuracy of the model are found to be significantly better than five state-of-the-art competing models.
Automatic Scene-based Topic Channel Construction System for E-Commerce
Oct 06, 2022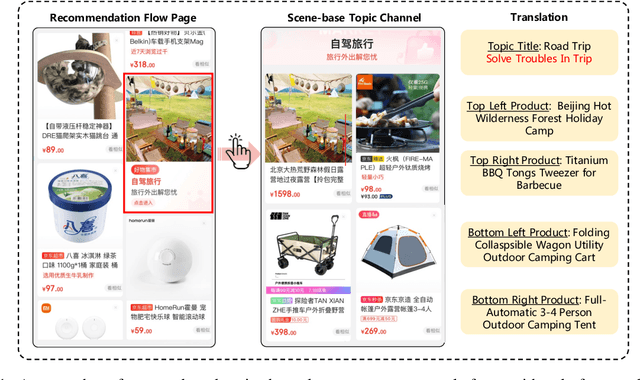

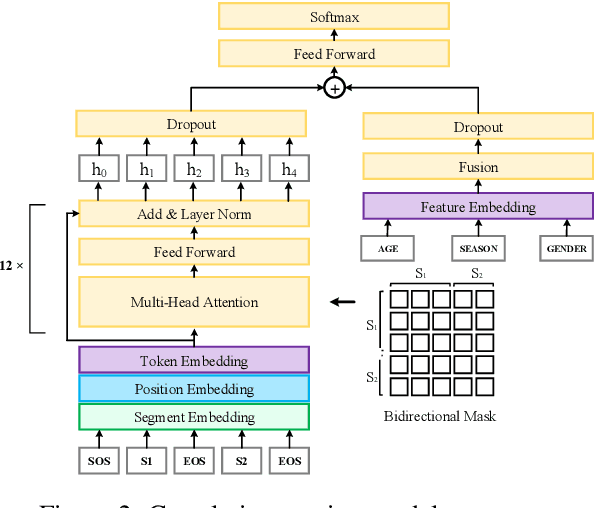
Scene marketing that well demonstrates user interests within a certain scenario has proved effective for offline shopping. To conduct scene marketing for e-commerce platforms, this work presents a novel product form, scene-based topic channel which typically consists of a list of diverse products belonging to the same usage scenario and a topic title that describes the scenario with marketing words. As manual construction of channels is time-consuming due to billions of products as well as dynamic and diverse customers' interests, it is necessary to leverage AI techniques to automatically construct channels for certain usage scenarios and even discover novel topics. To be specific, we first frame the channel construction task as a two-step problem, i.e., scene-based topic generation and product clustering, and propose an E-commerce Scene-based Topic Channel construction system (i.e., ESTC) to achieve automated production, consisting of scene-based topic generation model for the e-commerce domain, product clustering on the basis of topic similarity, as well as quality control based on automatic model filtering and human screening. Extensive offline experiments and online A/B test validates the effectiveness of such a novel product form as well as the proposed system. In addition, we also introduce the experience of deploying the proposed system on a real-world e-commerce recommendation platform.
Knowledge Distillation based Contextual Relevance Matching for E-commerce Product Search
Oct 04, 2022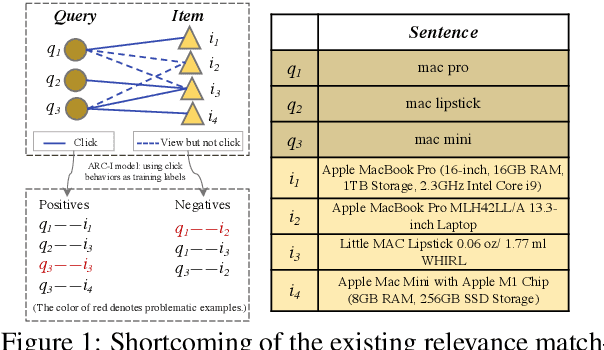
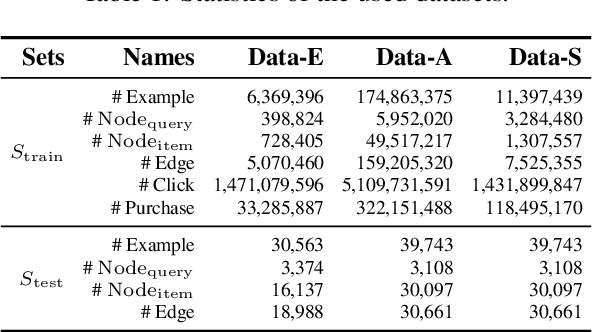
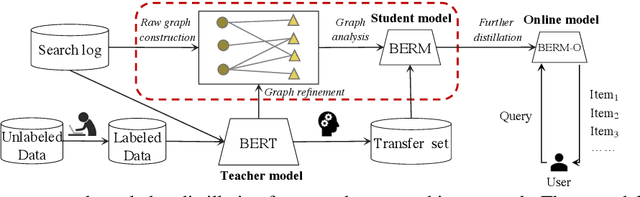
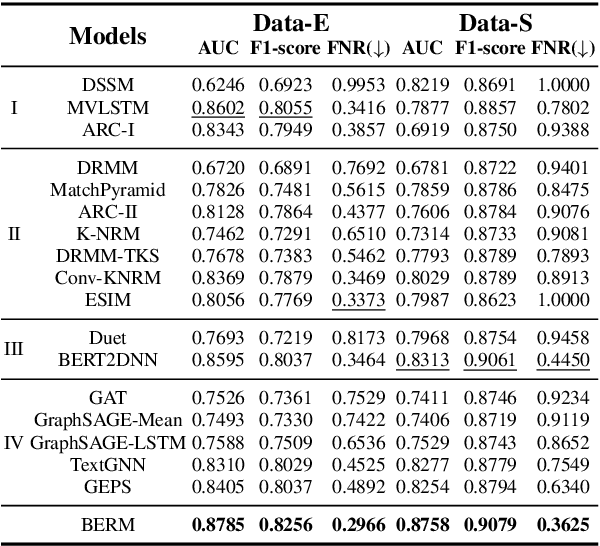
Online relevance matching is an essential task of e-commerce product search to boost the utility of search engines and ensure a smooth user experience. Previous work adopts either classical relevance matching models or Transformer-style models to address it. However, they ignore the inherent bipartite graph structures that are ubiquitous in e-commerce product search logs and are too inefficient to deploy online. In this paper, we design an efficient knowledge distillation framework for e-commerce relevance matching to integrate the respective advantages of Transformer-style models and classical relevance matching models. Especially for the core student model of the framework, we propose a novel method using $k$-order relevance modeling. The experimental results on large-scale real-world data (the size is 6$\sim$174 million) show that the proposed method significantly improves the prediction accuracy in terms of human relevance judgment. We deploy our method to the anonymous online search platform. The A/B testing results show that our method significantly improves 5.7% of UV-value under price sort mode.