 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor-Free Person Search
Mar 22, 2021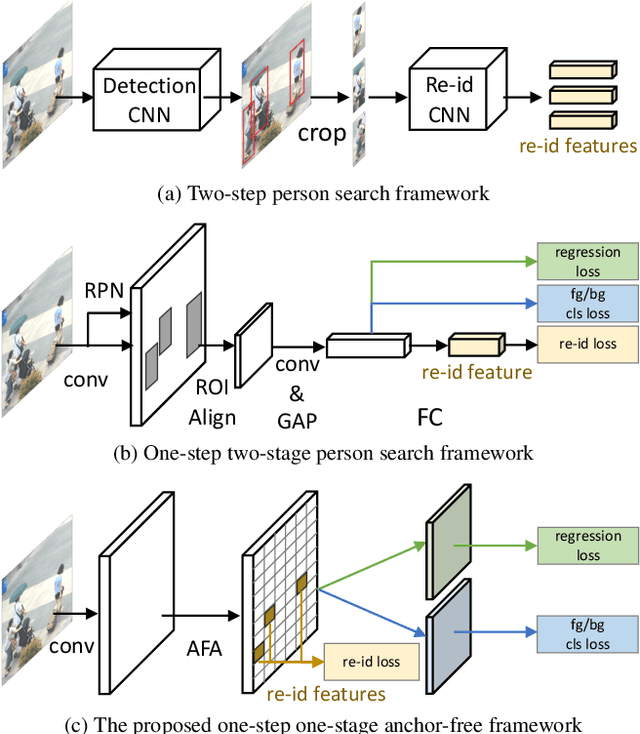
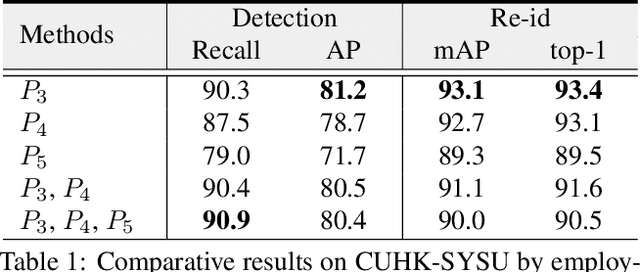
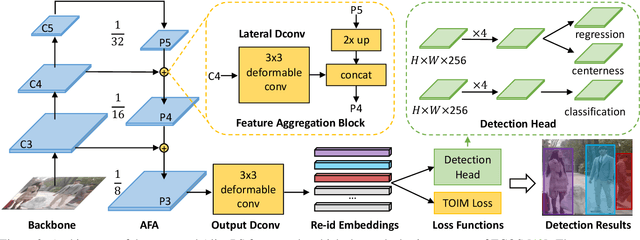
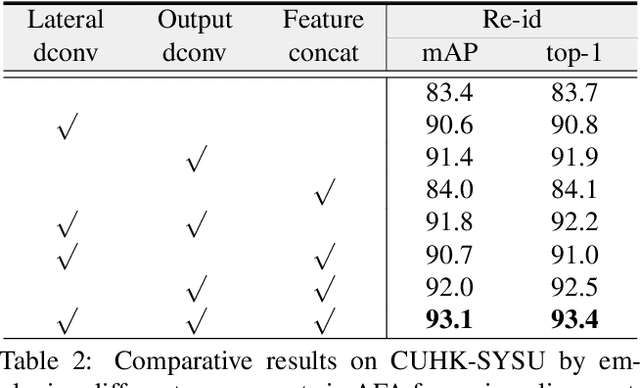
Person search aims to simultaneously localize and identify a query person from realistic, uncropped images, which can be regarded as the unified task of pedestrian detection and person re-identification (re-id). Most existing works employ two-stage detectors like Faster-RCNN, yielding encouraging accuracy but with high computational overhead. In this work, we present the Feature-Aligned Person Search Network (AlignPS), the first anchor-free framework to efficiently tackle this challenging task. AlignPS explicitly addresses the major challenges, which we summarize as the misalignment issues in different levels (i.e., scale, region, and task), when accommodating an anchor-free detector for this task. More specifically, we propose an aligned feature aggregation module to generate more discriminative and robust feature embeddings by following a "re-id first" principle. Such a simple design directly improves the baseline anchor-free model on CUHK-SYSU by more than 20% in mAP. Moreover, AlignPS outperforms state-of-the-art two-stage methods, with a higher speed. Code is available at https://github.com/daodaofr/AlignPS
Brain Image Synthesis with Unsupervised Multivariate Canonical CSC$\ell_4$Net
Mar 22, 2021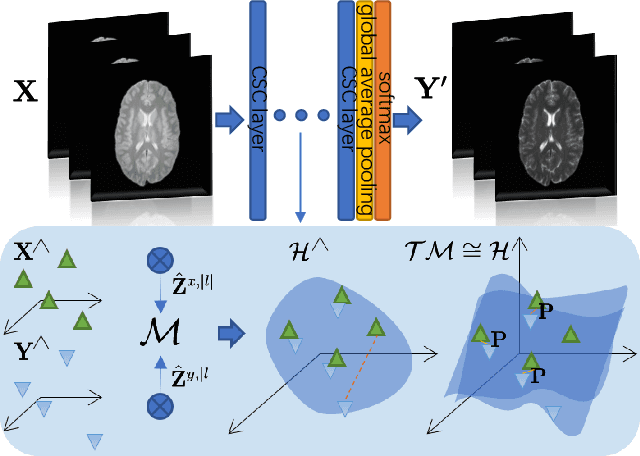
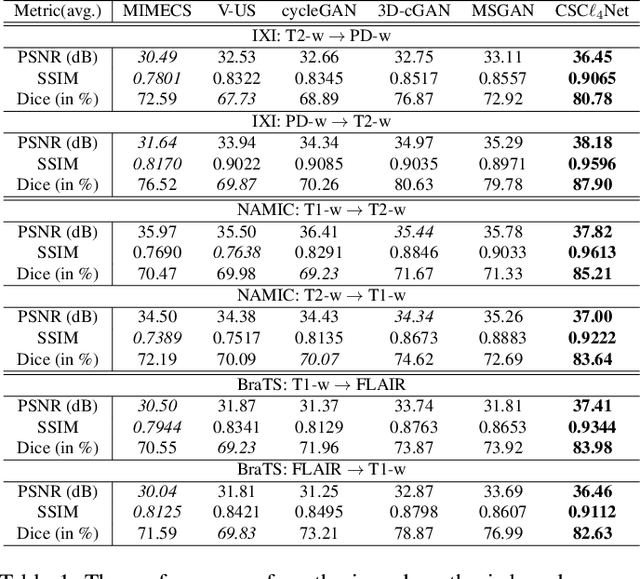
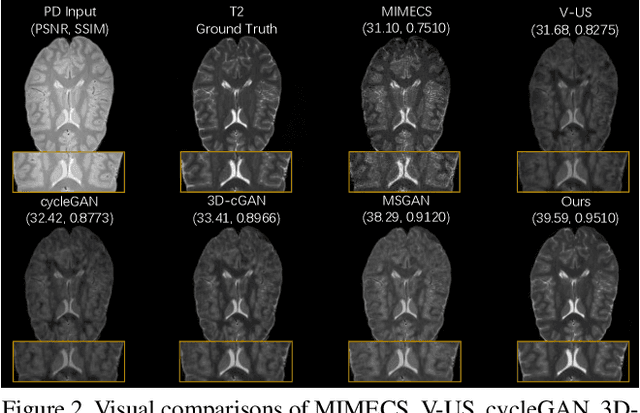
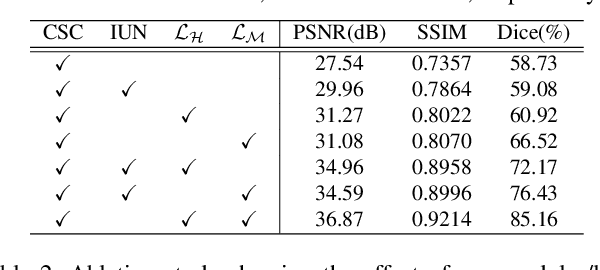
Recent advances in neuroscience have highlighted the effectiveness of multi-modal medical data for investigating certain pathologies and understanding human cognition. However, obtaining full sets of different modalities is limited by various factors, such as long acquisition times, high examination costs and artifact suppression. In addition, the complexity, high dimensionality and heterogeneity of neuroimaging data remains another key challenge in leveraging existing randomized scans effectively, as data of the same modality is often measured differently by different machines. There is a clear need to go beyond the traditional imaging-dependent process and synthesize anatomically specific target-modality data from a source input. In this paper, we propose to learn dedicated features that cross both intre- and intra-modal variations using a novel CSC$\ell_4$Net. Through an initial unification of intra-modal data in the feature maps and multivariate canonical adaptation, CSC$\ell_4$Net facilitates feature-level mutual transformation. The positive definite Riemannian manifold-penalized data fidelity term further enables CSC$\ell_4$Net to reconstruct missing measurements according to transformed features. Finally, the maximization $\ell_4$-norm boils down to a computationally efficient optimization problem. Extensive experiments validate the ability and robustness of our CSC$\ell_4$Net compared to the state-of-the-art methods on multiple datasets.
Variational Knowledge Distillation for Disease Classification in Chest X-Rays
Mar 19, 2021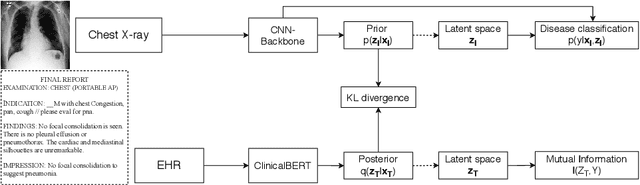
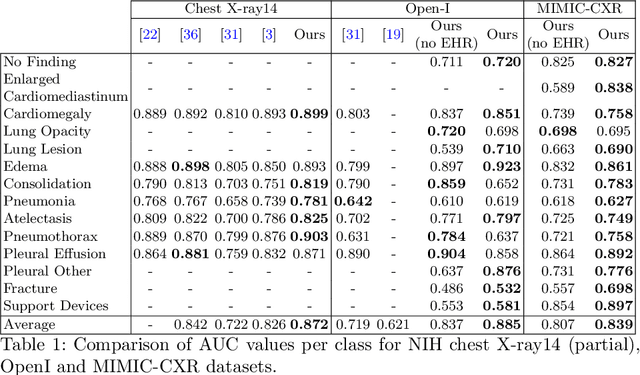
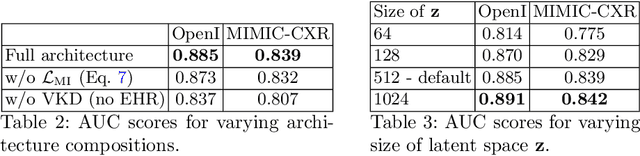
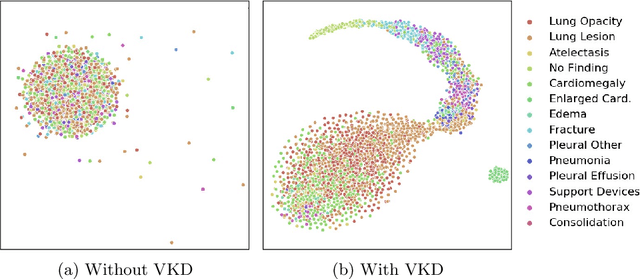
Disease classification relying solely on imaging data attracts great interest in medical image analysis. Current models could be further improved, however, by also employing Electronic Health Records (EHRs), which contain rich information on patients and findings from clinicians. It is challenging to incorporate this information into disease classification due to the high reliance on clinician input in EHRs, limiting the possibility for automated diagnosis. In this paper, we propose \textit{variational knowledge distillation} (VKD), which is a new probabilistic inference framework for disease classification based on X-rays that leverages knowledge from EHRs. Specifically, we introduce a conditional latent variable model, where we infer the latent representation of the X-ray image with the variational posterior conditioning on the associated EHR text. By doing so, the model acquires the ability to extract the visual features relevant to the disease during learning and can therefore perform more accurate classification for unseen patients at inference based solely on their X-ray scans. We demonstrate the effectiveness of our method on three public benchmark datasets with paired X-ray images and EHRs. The results show that the proposed variational knowledge distillation can consistently improve the performance of medical image classification and significantly surpasses current methods.
Group Collaborative Learning for Co-Salient Object Detection
Mar 15, 2021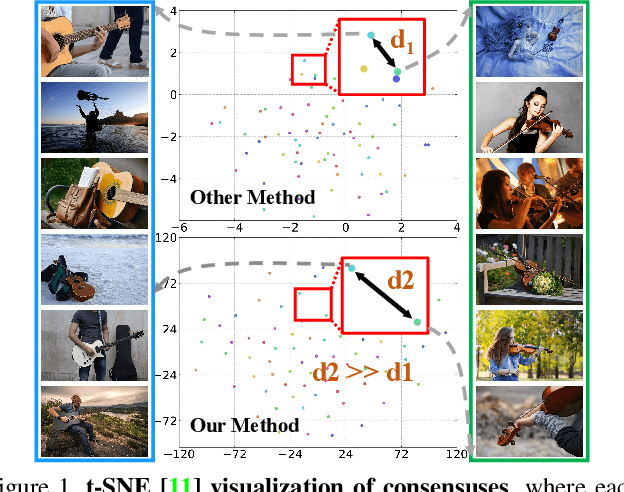

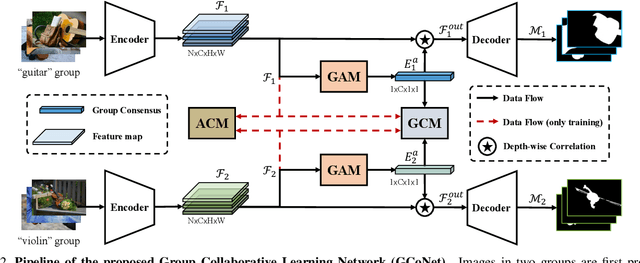
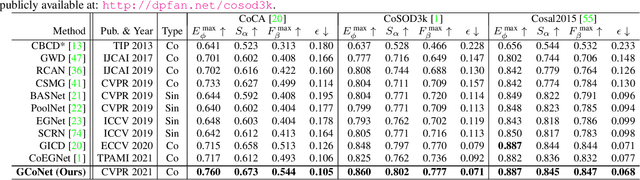
We present a novel group collaborative learning framework (GCoNet) capable of detecting co-salient objects in real time (16ms), by simultaneously mining consensus representations at group level based on the two necessary criteria: 1) intra-group compactness to better formulate the consistency among co-salient objects by capturing their inherent shared attributes using our novel group affinity module; 2) inter-group separability to effectively suppress the influence of noisy objects on the output by introducing our new group collaborating module conditioning the inconsistent consensus. To learn a better embedding space without extra computational overhead, we explicitly employ auxiliary classification supervision. Extensive experiments on three challenging benchmarks, i.e., CoCA, CoSOD3k, and Cosal2015, demonstrate that our simple GCoNet outperforms 10 cutting-edge models and achieves the new state-of-the-art. We demonstrate this paper's new technical contributions on a number of important downstream computer vision applications including content aware co-segmentation, co-localization based automatic thumbnails, etc.
Many-to-One Distribution Learning and K-Nearest Neighbor Smoothing for Thoracic Disease Identification
Feb 26, 2021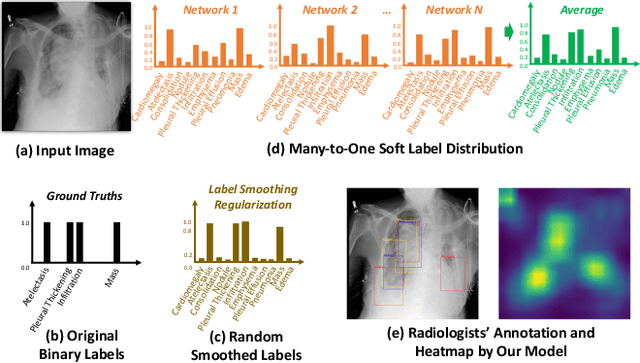

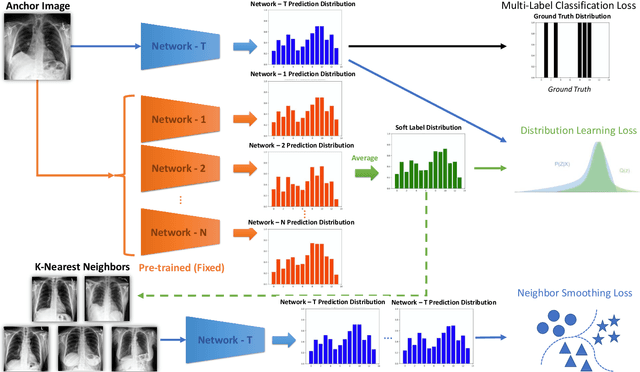
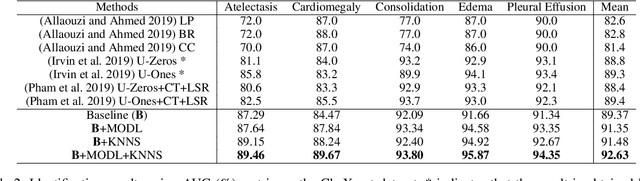
Chest X-rays are an important and accessible clinical imaging tool for the detection of many thoracic diseases. Over the past decade, deep learning, with a focus on the convolutional neural network (CNN), has become the most powerful computer-aided diagnosis technology for improving disease identification performance. However, training an effective and robust deep CNN usually requires a large amount of data with high annotation quality. For chest X-ray imaging, annotating large-scale data requires professional domain knowledge and is time-consuming. Thus, existing public chest X-ray datasets usually adopt language pattern based methods to automatically mine labels from reports. However, this results in label uncertainty and inconsistency. In this paper, we propose many-to-one distribution learning (MODL) and K-nearest neighbor smoothing (KNNS) methods from two perspectives to improve a single model's disease identification performance, rather than focusing on an ensemble of models. MODL integrates multiple models to obtain a soft label distribution for optimizing the single target model, which can reduce the effects of original label uncertainty. Moreover, KNNS aims to enhance the robustness of the target model to provide consistent predictions on images with similar medical findings. Extensive experiments on the public NIH Chest X-ray and CheXpert datasets show that our model achieves consistent improvements over the state-of-the-art methods.
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
Feb 24, 2021
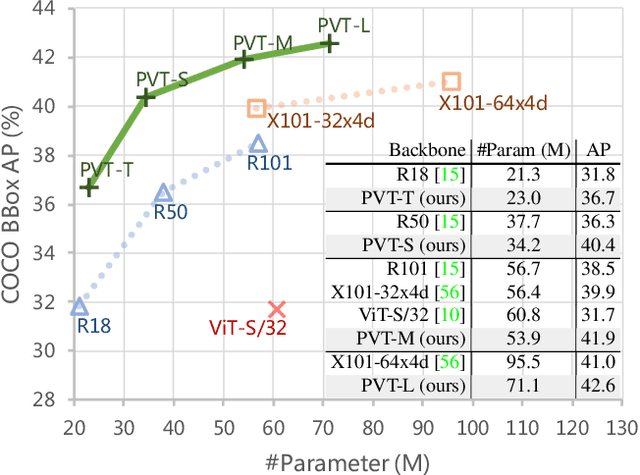
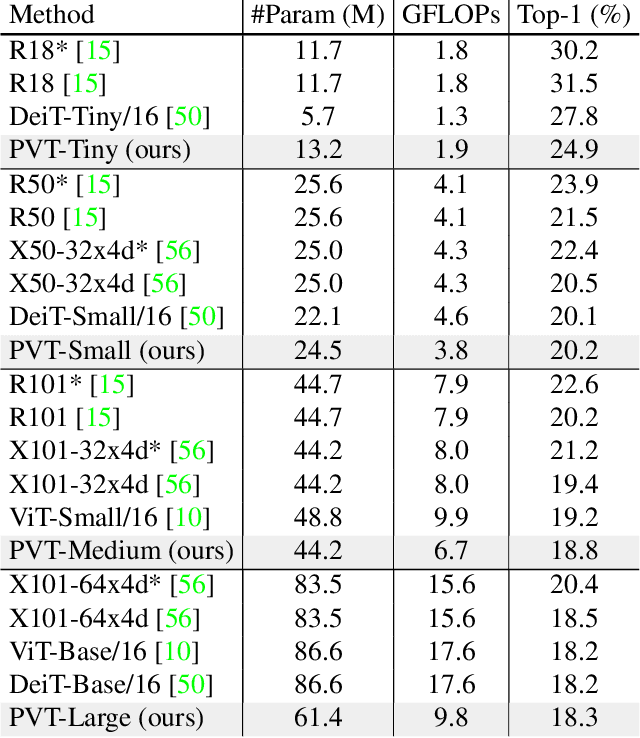
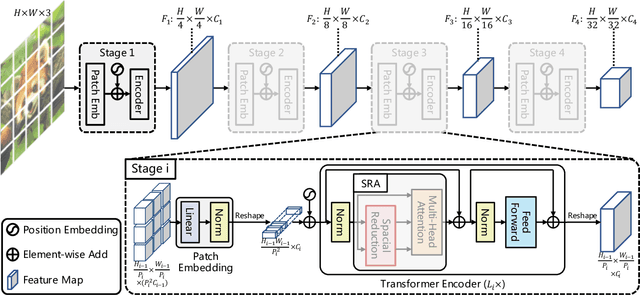
Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several merits compared to prior arts. (1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense predictions but also using a progressive shrinking pyramid to reduce computations of large feature maps. (2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones. (3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g., object detection, semantic, and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches. Code is available at https://github.com/whai362/PVT.
Salient Object Detection via Integrity Learning
Feb 21, 2021
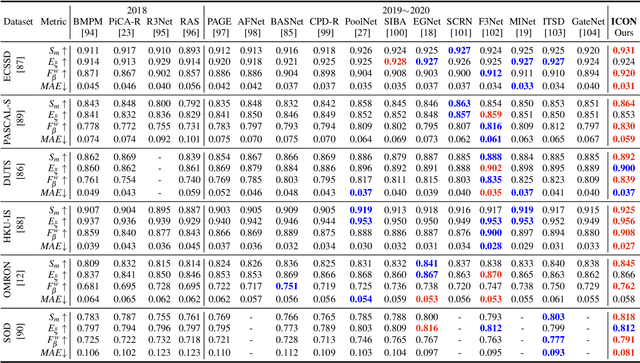
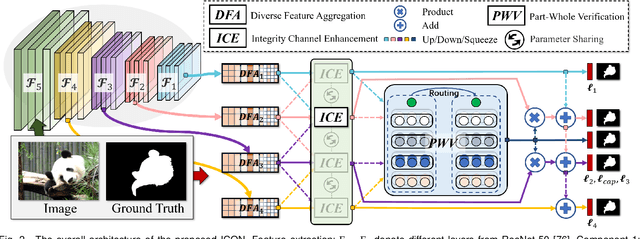
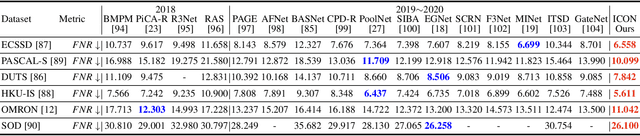
Albeit current salient object detection (SOD) works have achieved fantastic progress, they are cast into the shade when it comes to the integrity of the predicted salient regions. We define the concept of integrity at both the micro and macro level. Specifically, at the micro level, the model should highlight all parts that belong to a certain salient object, while at the macro level, the model needs to discover all salient objects from the given image scene. To facilitate integrity learning for salient object detection, we design a novel Integrity Cognition Network (ICON), which explores three important components to learn strong integrity features. 1) Unlike the existing models that focus more on feature discriminability, we introduce a diverse feature aggregation (DFA) component to aggregate features with various receptive fields (i.e.,, kernel shape and context) and increase the feature diversity. Such diversity is the foundation for mining the integral salient objects. 2) Based on the DFA features, we introduce the integrity channel enhancement (ICE) component with the goal of enhancing feature channels that highlight the integral salient objects at the macro level, while suppressing the other distracting ones. 3) After extracting the enhanced features, the part-whole verification (PWV) method is employed to determine whether the part and whole object features have strong agreement. Such part-whole agreements can further improve the micro-level integrity for each salient object. To demonstrate the effectiveness of ICON, comprehensive experiments are conducted on seven challenging benchmarks, where promising results are achieved.
Concealed Object Detection
Feb 20, 2021

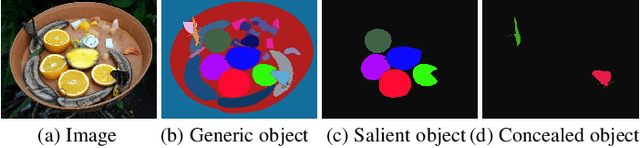

We present the first systematic study on concealed object detection (COD), which aims to identify objects that are "perfectly" embedded in their background. The high intrinsic similarities between the concealed objects and their background make COD far more challenging than traditional object detection/segmentation. To better understand this task, we collect a large-scale dataset, called COD10K, which consists of 10,000 images covering concealed objects in diverse real-world scenarios from 78 object categories. Further, we provide rich annotations including object categories, object boundaries, challenging attributes, object-level labels, and instance-level annotations. Our COD10K is the largest COD dataset to date, with the richest annotations, which enables comprehensive concealed object understanding and can even be used to help progress several other vision tasks, such as detection, segmentation, classification, etc. Motivated by how animals hunt in the wild, we also design a simple but strong baseline for COD, termed the Search Identification Network (SINet). Without any bells and whistles, SINet outperforms 12 cutting-edge baselines on all datasets tested, making them robust, general architectures that could serve as catalysts for future research in COD. Finally, we provide some interesting findings and highlight several potential applications and future directions. To spark research in this new field, our code, dataset, and online demo are available on our project page: http://mmcheng.net/cod.
GMLight: Lighting Estimation via Geometric Distribution Approximation
Feb 20, 2021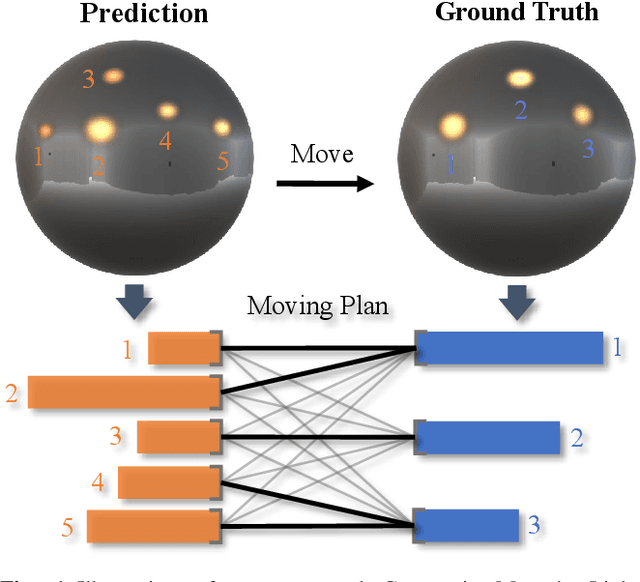
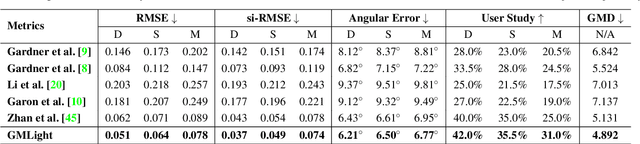
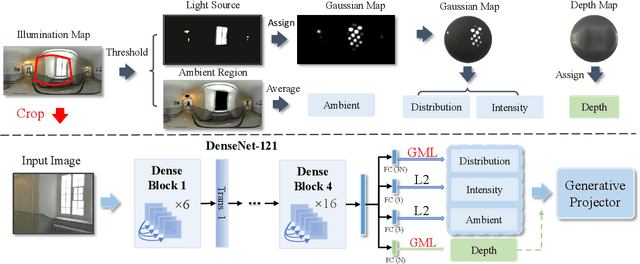
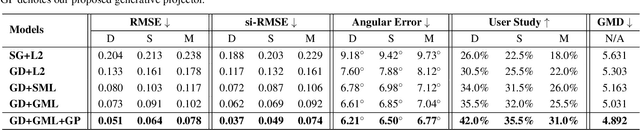
Lighting estimation from a single image is an essential yet challenging task in computer vision and computer graphics. Existing works estimate lighting by regressing representative illumination parameters or generating illumination maps directly. However, these methods often suffer from poor accuracy and generalization. This paper presents Geometric Mover's Light (GMLight), a lighting estimation framework that employs a regression network and a generative projector for effective illumination estimation. We parameterize illumination scenes in terms of the geometric light distribution, light intensity, ambient term, and auxiliary depth, and estimate them as a pure regression task. Inspired by the earth mover's distance, we design a novel geometric mover's loss to guide the accurate regression of light distribution parameters. With the estimated lighting parameters, the generative projector synthesizes panoramic illumination maps with realistic appearance and frequency. Extensive experiments show that GMLight achieves accurate illumination estimation and superior fidelity in relighting for 3D object insertion.
SiMaN: Sign-to-Magnitude Network Binarization
Feb 16, 2021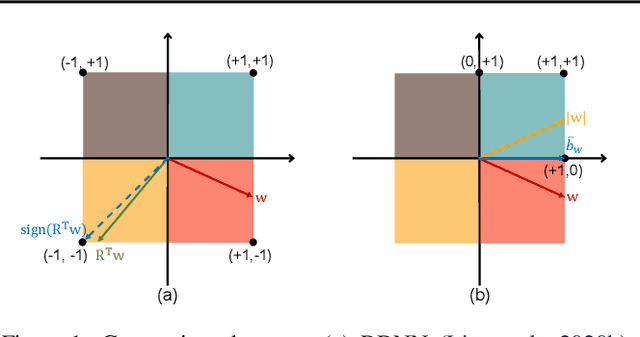

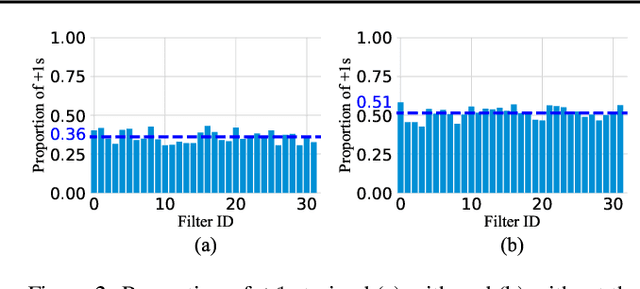
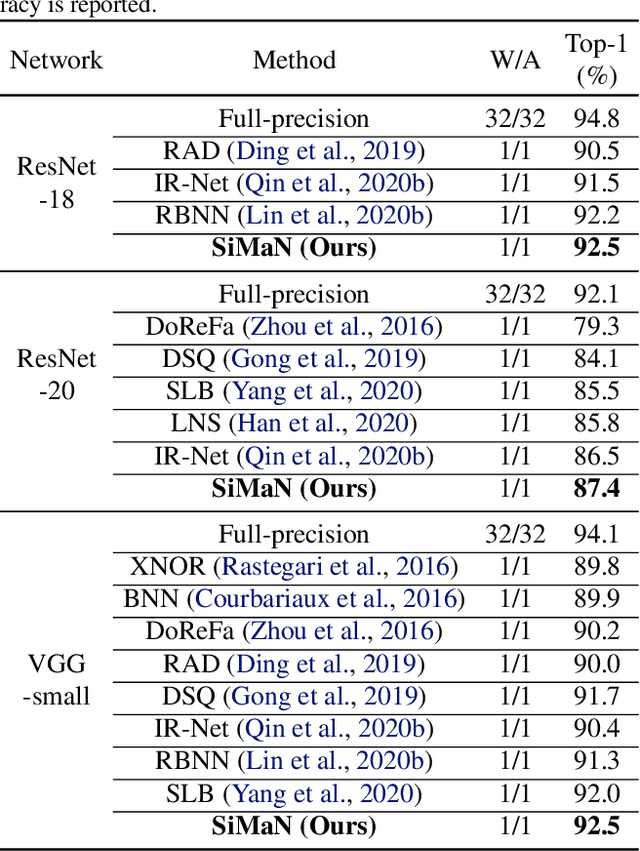
Binary neural networks (BNNs) have attracted broad research interest due to their efficient storage and computational ability. Nevertheless, a significant challenge of BNNs lies in handling discrete constraints while ensuring bit entropy maximization, which typically makes their weight optimization very difficult. Existing methods relax the learning using the sign function, which simply encodes positive weights into +1s, and -1s otherwise. Alternatively, we formulate an angle alignment objective to constrain the weight binarization to {0,+1} to solve the challenge. In this paper, we show that our weight binarization provides an analytical solution by encoding high-magnitude weights into +1s, and 0s otherwise. Therefore, a high-quality discrete solution is established in a computationally efficient manner without the sign function. We prove that the learned weights of binarized networks roughly follow a Laplacian distribution that does not allow entropy maximization, and further demonstrate that it can be effectively solved by simply removing the $\ell_2$ regularization during network training. Our method, dubbed sign-to-magnitude network binarization (SiMaN), is evaluated on CIFAR-10 and ImageNet, demonstrating its superiority over the sign-based state-of-the-arts. Code is at https://github.com/lmbxmu/SiMaN.