 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent 3D Hand Reconstruction in Video via self-supervised Learning
Jan 24, 2022
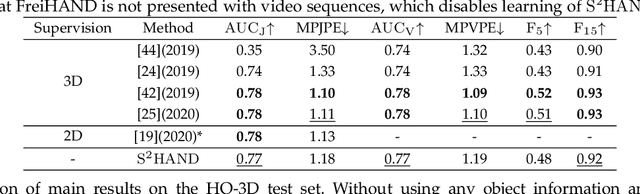
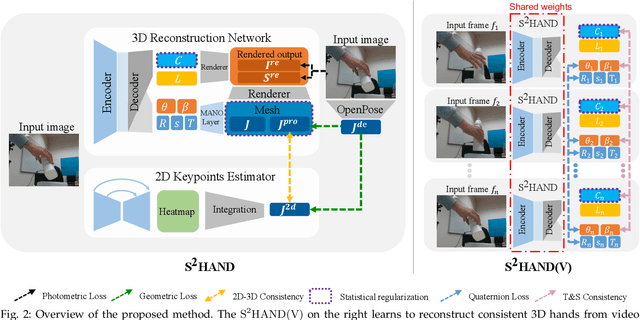
We present a method for reconstructing accurate and consistent 3D hands from a monocular video. We observe that detected 2D hand keypoints and the image texture provide important cues about the geometry and texture of the 3D hand, which can reduce or even eliminate the requirement on 3D hand annotation. Thus we propose ${\rm {S}^{2}HAND}$, a self-supervised 3D hand reconstruction model, that can jointly estimate pose, shape, texture, and the camera viewpoint from a single RGB input through the supervision of easily accessible 2D detected keypoints. We leverage the continuous hand motion information contained in the unlabeled video data and propose ${\rm {S}^{2}HAND(V)}$, which uses a set of weights shared ${\rm {S}^{2}HAND}$ to process each frame and exploits additional motion, texture, and shape consistency constrains to promote more accurate hand poses and more consistent shapes and textures. Experiments on benchmark datasets demonstrate that our self-supervised approach produces comparable hand reconstruction performance compared with the recent full-supervised methods in single-frame as input setup, and notably improves the reconstruction accuracy and consistency when using video training data.
NeRFReN: Neural Radiance Fields with Reflections
Nov 30, 2021
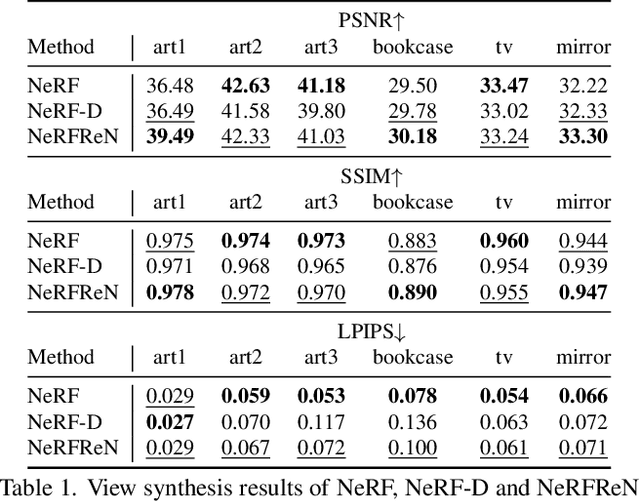
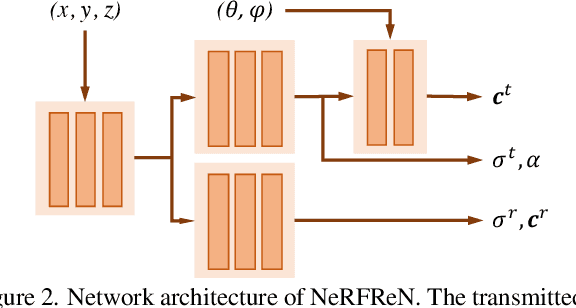
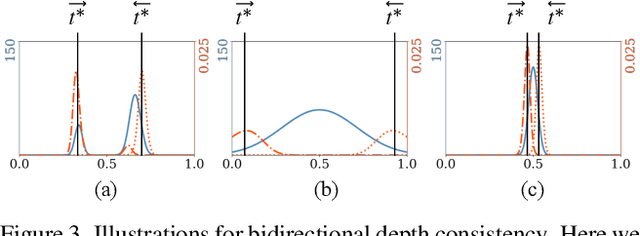
Neural Radiance Fields (NeRF) has achieved unprecedented view synthesis quality using coordinate-based neural scene representations. However, NeRF's view dependency can only handle simple reflections like highlights but cannot deal with complex reflections such as those from glass and mirrors. In these scenarios, NeRF models the virtual image as real geometries which leads to inaccurate depth estimation, and produces blurry renderings when the multi-view consistency is violated as the reflected objects may only be seen under some of the viewpoints. To overcome these issues, we introduce NeRFReN, which is built upon NeRF to model scenes with reflections. Specifically, we propose to split a scene into transmitted and reflected components, and model the two components with separate neural radiance fields. Considering that this decomposition is highly under-constrained, we exploit geometric priors and apply carefully-designed training strategies to achieve reasonable decomposition results. Experiments on various self-captured scenes show that our method achieves high-quality novel view synthesis and physically sound depth estimation results while enabling scene editing applications. Code and data will be released.
ISF-GAN: An Implicit Style Function for High-Resolution Image-to-Image Translation
Sep 26, 2021



Recently, there has been an increasing interest in image editing methods that employ pre-trained unconditional image generators (e.g., StyleGAN). However, applying these methods to translate images to multiple visual domains remains challenging. Existing works do not often preserve the domain-invariant part of the image (e.g., the identity in human face translations), they do not usually handle multiple domains, or do not allow for multi-modal translations. This work proposes an implicit style function (ISF) to straightforwardly achieve multi-modal and multi-domain image-to-image translation from pre-trained unconditional generators. The ISF manipulates the semantics of an input latent code to make the image generated from it lying in the desired visual domain. Our results in human face and animal manipulations show significantly improved results over the baselines. Our model enables cost-effective multi-modal unsupervised image-to-image translations at high resolution using pre-trained unconditional GANs. The code and data are available at: \url{https://github.com/yhlleo/stylegan-mmuit}.
Audio2Gestures: Generating Diverse Gestures from Speech Audio with Conditional Variational Autoencoders
Aug 15, 2021
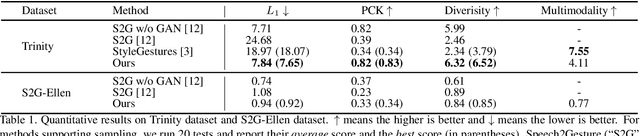
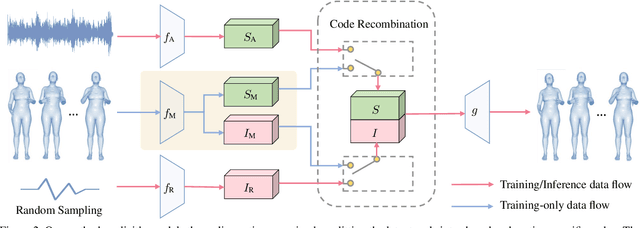

Generating conversational gestures from speech audio is challenging due to the inherent one-to-many mapping between audio and body motions. Conventional CNNs/RNNs assume one-to-one mapping, and thus tend to predict the average of all possible target motions, resulting in plain/boring motions during inference. In order to overcome this problem, we propose a novel conditional variational autoencoder (VAE) that explicitly models one-to-many audio-to-motion mapping by splitting the cross-modal latent code into shared code and motion-specific code. The shared code mainly models the strong correlation between audio and motion (such as the synchronized audio and motion beats), while the motion-specific code captures diverse motion information independent of the audio. However, splitting the latent code into two parts poses training difficulties for the VAE model. A mapping network facilitating random sampling along with other techniques including relaxed motion loss, bicycle constraint, and diversity loss are designed to better train the VAE. Experiments on both 3D and 2D motion datasets verify that our method generates more realistic and diverse motions than state-of-the-art methods, quantitatively and qualitatively. Finally, we demonstrate that our method can be readily used to generate motion sequences with user-specified motion clips on the timeline. Code and more results are at https://jingli513.github.io/audio2gestures.
UniFaceGAN: A Unified Framework for Temporally Consistent Facial Video Editing
Aug 12, 2021



Recent research has witnessed advances in facial image editing tasks including face swapping and face reenactment. However, these methods are confined to dealing with one specific task at a time. In addition, for video facial editing, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In this paper, we propose a unified temporally consistent facial video editing framework termed UniFaceGAN. Based on a 3D reconstruction model and a simple yet efficient dynamic training sample selection mechanism, our framework is designed to handle face swapping and face reenactment simultaneously. To enforce the temporal consistency, a novel 3D temporal loss constraint is introduced based on the barycentric coordinate interpolation. Besides, we propose a region-aware conditional normalization layer to replace the traditional AdaIN or SPADE to synthesize more context-harmonious results. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.
Animatable Neural Radiance Fields from Monocular RGB Video
Jun 25, 2021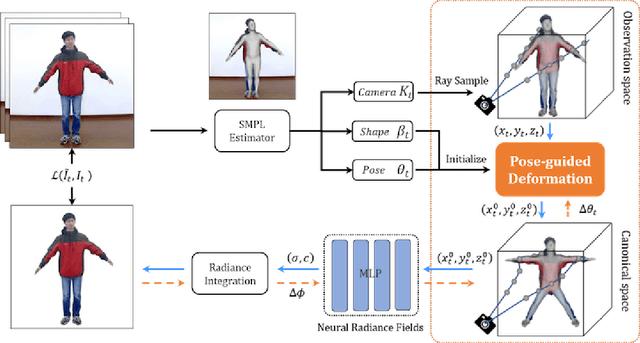
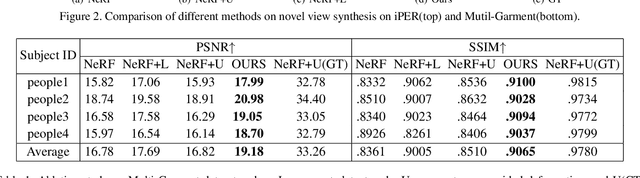


We present animatable neural radiance fields for detailed human avatar creation from monocular videos. Our approach extends neural radiance fields (NeRF) to the dynamic scenes with human movements via introducing explicit pose-guided deformation while learning the scene representation network. In particular, we estimate the human pose for each frame and learn a constant canonical space for the detailed human template, which enables natural shape deformation from the observation space to the canonical space under the explicit control of the pose parameters. To compensate for inaccurate pose estimation, we introduce the pose refinement strategy that updates the initial pose during the learning process, which not only helps to learn more accurate human reconstruction but also accelerates the convergence. In experiments we show that the proposed approach achieves 1) implicit human geometry and appearance reconstruction with high-quality details, 2) photo-realistic rendering of the human from arbitrary views, and 3) animation of the human with arbitrary poses.
Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
Jun 16, 2021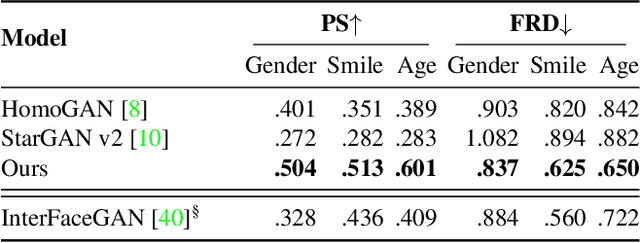
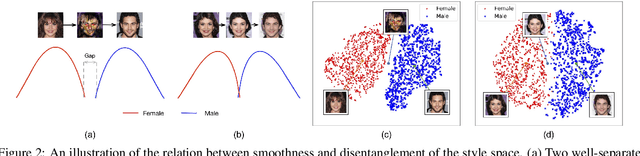
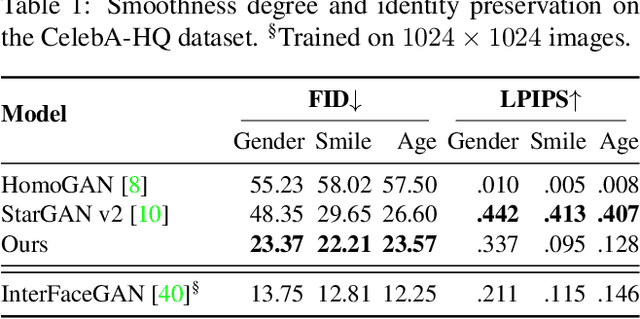

Image-to-Image (I2I) multi-domain translation models are usually evaluated also using the quality of their semantic interpolation results. However, state-of-the-art models frequently show abrupt changes in the image appearance during interpolation, and usually perform poorly in interpolations across domains. In this paper, we propose a new training protocol based on three specific losses which help a translation network to learn a smooth and disentangled latent style space in which: 1) Both intra- and inter-domain interpolations correspond to gradual changes in the generated images and 2) The content of the source image is better preserved during the translation. Moreover, we propose a novel evaluation metric to properly measure the smoothness of latent style space of I2I translation models. The proposed method can be plugged into existing translation approaches, and our extensive experiments on different datasets show that it can significantly boost the quality of the generated images and the graduality of the interpolations.
Model-based 3D Hand Reconstruction via Self-Supervised Learning
Mar 22, 2021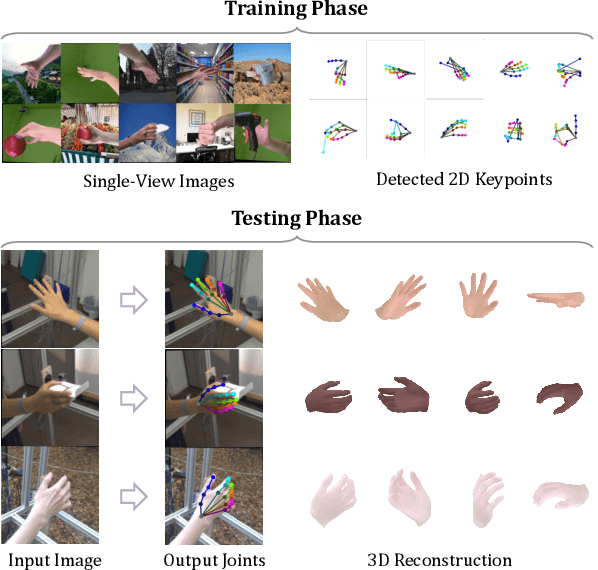
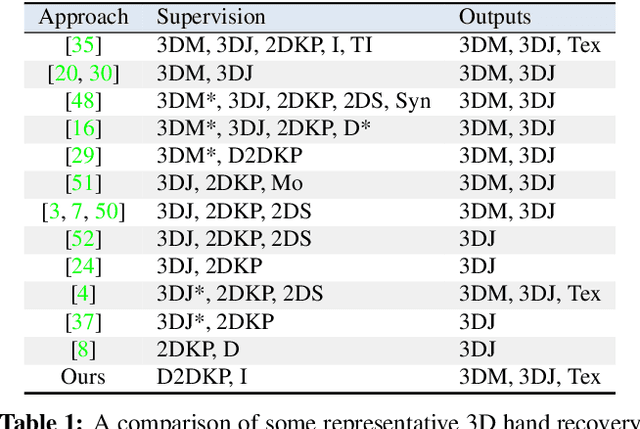
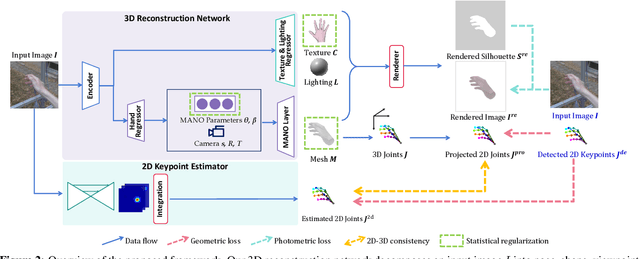
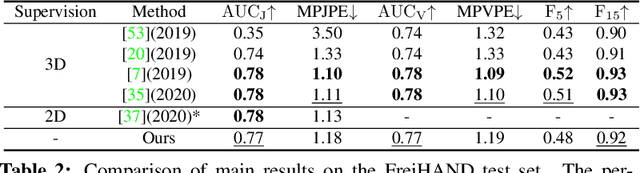
Reconstructing a 3D hand from a single-view RGB image is challenging due to various hand configurations and depth ambiguity. To reliably reconstruct a 3D hand from a monocular image, most state-of-the-art methods heavily rely on 3D annotations at the training stage, but obtaining 3D annotations is expensive. To alleviate reliance on labeled training data, we propose S2HAND, a self-supervised 3D hand reconstruction network that can jointly estimate pose, shape, texture, and the camera viewpoint. Specifically, we obtain geometric cues from the input image through easily accessible 2D detected keypoints. To learn an accurate hand reconstruction model from these noisy geometric cues, we utilize the consistency between 2D and 3D representations and propose a set of novel losses to rationalize outputs of the neural network. For the first time, we demonstrate the feasibility of training an accurate 3D hand reconstruction network without relying on manual annotations. Our experiments show that the proposed method achieves comparable performance with recent fully-supervised methods while using fewer supervision data.
High-Fidelity 3D Digital Human Creation from RGB-D Selfies
Oct 12, 2020
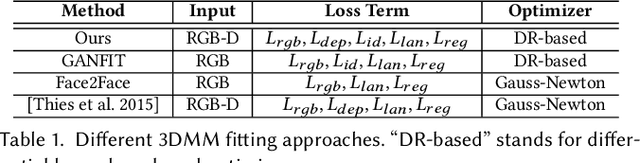
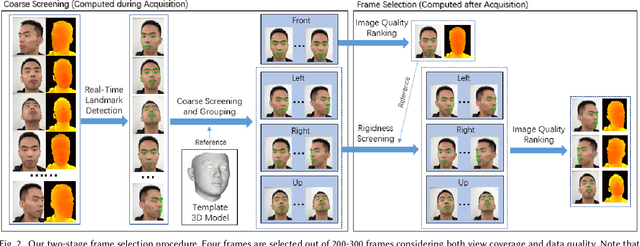

We present a fully automatic system that can produce high-fidelity, photo-realistic 3D digital human characters with a consumer RGB-D selfie camera. The system only needs the user to take a short selfie RGB-D video while rotating his/her head, and can produce a high quality reconstruction in less than 30 seconds. Our main contribution is a new facial geometry modeling and reflectance synthesis procedure that significantly improves the state-of-the-art. Specifically, given the input video a two-stage frame selection algorithm is first employed to select a few high-quality frames for reconstruction. A novel, differentiable renderer based 3D Morphable Model (3DMM) fitting method is then applied to recover facial geometries from multiview RGB-D data, which takes advantages of extensive data generation and perturbation. Our 3DMM has much larger expressive capacities than conventional 3DMM, allowing us to recover more accurate facial geometry using merely linear bases. For reflectance synthesis, we present a hybrid approach that combines parametric fitting and CNNs to synthesize high-resolution albedo/normal maps with realistic hair/pore/wrinkle details. Results show that our system can produce faithful 3D characters with extremely realistic details. Code and the constructed 3DMM is publicly available.
Self-supervised Video Representation Learning by Uncovering Spatio-temporal Statistics
Aug 31, 2020
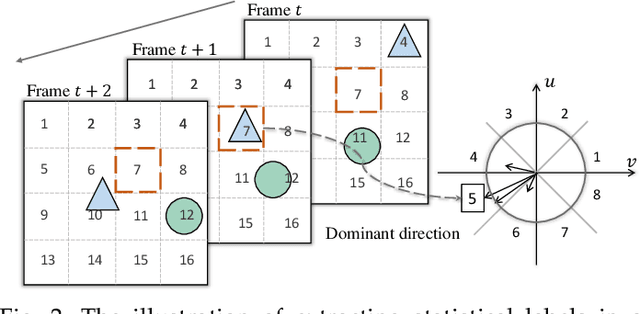
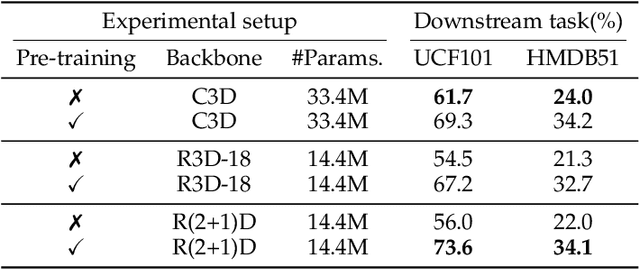

This paper proposes a novel pretext task to address the self-supervised video representation learning problem. Specifically, given an unlabeled video clip, we compute a series of spatio-temporal statistical summaries, such as the spatial location and dominant direction of the largest motion, the spatial location and dominant color of the largest color diversity along the temporal axis, etc. Then a neural network is built and trained to yield the statistical summaries given the video frames as inputs. In order to alleviate the learning difficulty, we employ several spatial partitioning patterns to encode rough spatial locations instead of exact spatial Cartesian coordinates. Our approach is inspired by the observation that human visual system is sensitive to rapidly changing contents in the visual field, and only needs impressions about rough spatial locations to understand the visual contents. To validate the effectiveness of the proposed approach, we conduct extensive experiments with several 3D backbone networks, i.e., C3D, 3D-ResNet and R(2+1)D. The results show that our approach outperforms the existing approaches across the three backbone networks on various downstream video analytic tasks including action recognition, video retrieval, dynamic scene recognition, and action similarity labeling. The source code is made publicly available at: https://github.com/laura-wang/video_repres_sts.