 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Generation-Enhanced Distributed LLM Agents for Generalizable Traffic Signal Control with Emergency Vehicles
Oct 30, 2025



With increasing urban traffic complexity, Traffic Signal Control (TSC) is essential for optimizing traffic flow and improving road safety. Large Language Models (LLMs) emerge as promising approaches for TSC. However, they are prone to hallucinations in emergencies, leading to unreliable decisions that may cause substantial delays for emergency vehicles. Moreover, diverse intersection types present substantial challenges for traffic state encoding and cross-intersection training, limiting generalization across heterogeneous intersections. Therefore, this paper proposes Retrieval Augmented Generation (RAG)-enhanced distributed LLM agents with Emergency response for Generalizable TSC (REG-TSC). Firstly, this paper presents an emergency-aware reasoning framework, which dynamically adjusts reasoning depth based on the emergency scenario and is equipped with a novel Reviewer-based Emergency RAG (RERAG) to distill specific knowledge and guidance from historical cases, enhancing the reliability and rationality of agents' emergency decisions. Secondly, this paper designs a type-agnostic traffic representation and proposes a Reward-guided Reinforced Refinement (R3) for heterogeneous intersections. R3 adaptively samples training experience from diverse intersections with environment feedback-based priority and fine-tunes LLM agents with a designed reward-weighted likelihood loss, guiding REG-TSC toward high-reward policies across heterogeneous intersections. On three real-world road networks with 17 to 177 heterogeneous intersections, extensive experiments show that REG-TSC reduces travel time by 42.00%, queue length by 62.31%, and emergency vehicle waiting time by 83.16%, outperforming other state-of-the-art methods.
The Role of ISAC in 6G Networks: Enabling Next-Generation Wireless Systems
Oct 06, 2025



The commencement of the sixth-generation (6G) wireless networks represents a fundamental shift in the integration of communication and sensing technologies to support next-generation applications. Integrated sensing and communication (ISAC) is a key concept in this evolution, enabling end-to-end support for both communication and sensing within a unified framework. It enhances spectrum efficiency, reduces latency, and supports diverse use cases, including smart cities, autonomous systems, and perceptive environments. This tutorial provides a comprehensive overview of ISAC's role in 6G networks, beginning with its evolution since 5G and the technical drivers behind its adoption. Core principles and system variations of ISAC are introduced, followed by an in-depth discussion of the enabling technologies that facilitate its practical deployment. The paper further analyzes current research directions to highlight key challenges, open issues, and emerging trends. Design insights and recommendations are also presented to support future development and implementation. This work ultimately try to address three central questions: Why is ISAC essential for 6G? What innovations does it bring? How will it shape the future of wireless communication?
Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents
Sep 11, 2025In long-horizon tasks, recent agents based on Large Language Models (LLMs) face a significant challenge that sparse, outcome-based rewards make it difficult to assign credit to intermediate steps. Previous methods mainly focus on creating dense reward signals to guide learning, either through traditional reinforcement learning techniques like inverse reinforcement learning or by using Process Reward Models for step-by-step feedback. In this paper, we identify a fundamental problem in the learning dynamics of LLMs: the magnitude of policy gradients is inherently coupled with the entropy, which leads to inefficient small updates for confident correct actions and potentially destabilizes large updates for uncertain ones. To resolve this, we propose Entropy-Modulated Policy Gradients (EMPG), a framework that re-calibrates the learning signal based on step-wise uncertainty and the final task outcome. EMPG amplifies updates for confident correct actions, penalizes confident errors, and attenuates updates from uncertain steps to stabilize exploration. We further introduce a bonus term for future clarity that encourages agents to find more predictable solution paths. Through comprehensive experiments on three challenging agent tasks, WebShop, ALFWorld, and Deep Search, we demonstrate that EMPG achieves substantial performance gains and significantly outperforms strong policy gradient baselines. Project page is at https://empgseed-seed.github.io/
D-LEAF: Localizing and Correcting Hallucinations in Multimodal LLMs via Layer-to-head Attention Diagnostics
Sep 09, 2025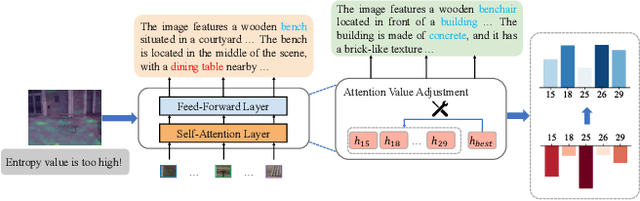

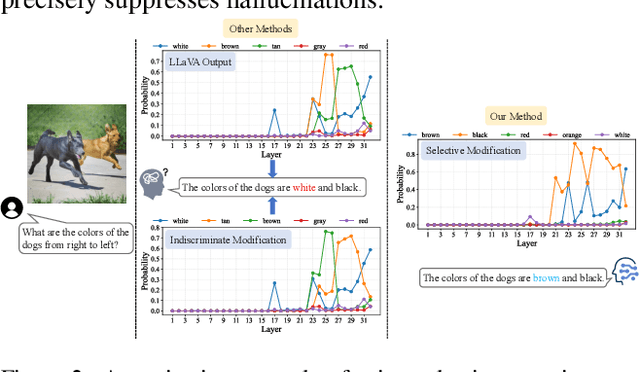
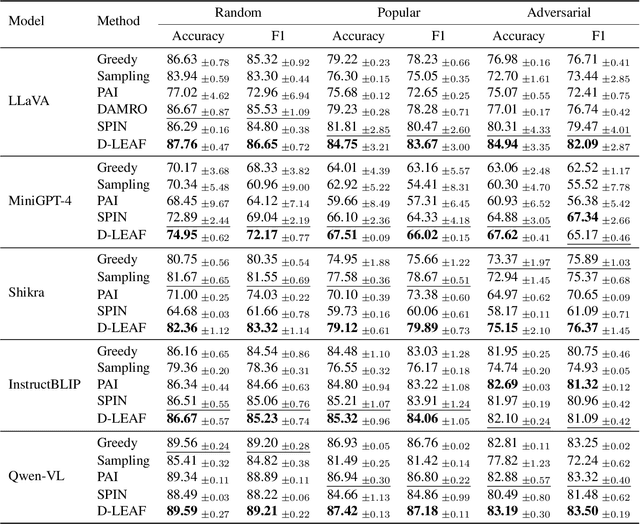
Multimodal Large Language Models (MLLMs) achieve strong performance on tasks like image captioning and visual question answering, but remain prone to hallucinations, where generated text conflicts with the visual input. Prior work links this partly to insufficient visual attention, but existing attention-based detectors and mitigation typically apply uniform adjustments across layers and heads, obscuring where errors originate. In this paper, we first show these methods fail to accurately localize problematic layers. Then, we introduce two diagnostics: Layer Image Attention Entropy (LIAE) which flags anomalous layers, and Image Attention Focus (IAF) which scores attention heads within those layers. Analysis shows that LIAE pinpoints faulty layers and IAF reliably ranks heads that warrant correction. Guided by these signals, we propose Dynamic Layer-wise Entropy and Attention Fusion (D-LEAF), a task-agnostic, attention-guided method that dynamically localizes and corrects errors during inference with negligible overhead. Results show our D-LEAF delivers a 53% relative improvement on standard captioning benchmarks, and on VQA both accuracy and F1-score improve by approximately 4%, substantially suppressing hallucinations while preserving efficiency.
M3HG: Multimodal, Multi-scale, and Multi-type Node Heterogeneous Graph for Emotion Cause Triplet Extraction in Conversations
Aug 26, 2025



Emotion Cause Triplet Extraction in Multimodal Conversations (MECTEC) has recently gained significant attention in social media analysis, aiming to extract emotion utterances, cause utterances, and emotion categories simultaneously. However, the scarcity of related datasets, with only one published dataset featuring highly uniform dialogue scenarios, hinders model development in this field. To address this, we introduce MECAD, the first multimodal, multi-scenario MECTEC dataset, comprising 989 conversations from 56 TV series spanning a wide range of dialogue contexts. In addition, existing MECTEC methods fail to explicitly model emotional and causal contexts and neglect the fusion of semantic information at different levels, leading to performance degradation. In this paper, we propose M3HG, a novel model that explicitly captures emotional and causal contexts and effectively fuses contextual information at both inter- and intra-utterance levels via a multimodal heterogeneous graph. Extensive experiments demonstrate the effectiveness of M3HG compared with existing state-of-the-art methods. The codes and dataset are available at https://github.com/redifinition/M3HG.
* 16 pages, 8 figures. Accepted to Findings of ACL 2025
SC-Captioner: Improving Image Captioning with Self-Correction by Reinforcement Learning
Aug 08, 2025We propose SC-Captioner, a reinforcement learning framework that enables the self-correcting capability of image caption models. Our crucial technique lies in the design of the reward function to incentivize accurate caption corrections. Specifically, the predicted and reference captions are decomposed into object, attribute, and relation sets using scene-graph parsing algorithms. We calculate the set difference between sets of initial and self-corrected captions to identify added and removed elements. These elements are matched against the reference sets to calculate correctness bonuses for accurate refinements and mistake punishments for wrong additions and removals, thereby forming the final reward. For image caption quality assessment, we propose a set of metrics refined from CAPTURE that alleviate its incomplete precision evaluation and inefficient relation matching problems. Furthermore, we collect a fine-grained annotated image caption dataset, RefinedCaps, consisting of 6.5K diverse images from COCO dataset. Experiments show that applying SC-Captioner on large visual-language models can generate better image captions across various scenarios, significantly outperforming the direct preference optimization training strategy.
Scaling Up Audio-Synchronized Visual Animation: An Efficient Training Paradigm
Aug 05, 2025Recent advances in audio-synchronized visual animation enable control of video content using audios from specific classes. However, existing methods rely heavily on expensive manual curation of high-quality, class-specific training videos, posing challenges to scaling up to diverse audio-video classes in the open world. In this work, we propose an efficient two-stage training paradigm to scale up audio-synchronized visual animation using abundant but noisy videos. In stage one, we automatically curate large-scale videos for pretraining, allowing the model to learn diverse but imperfect audio-video alignments. In stage two, we finetune the model on manually curated high-quality examples, but only at a small scale, significantly reducing the required human effort. We further enhance synchronization by allowing each frame to access rich audio context via multi-feature conditioning and window attention. To efficiently train the model, we leverage pretrained text-to-video generator and audio encoders, introducing only 1.9\% additional trainable parameters to learn audio-conditioning capability without compromising the generator's prior knowledge. For evaluation, we introduce AVSync48, a benchmark with videos from 48 classes, which is 3$\times$ more diverse than previous benchmarks. Extensive experiments show that our method significantly reduces reliance on manual curation by over 10$\times$, while generalizing to many open classes.
Towards Generalized Source Tracing for Codec-Based Deepfake Speech
Jun 08, 2025Recent attempts at source tracing for codec-based deepfake speech (CodecFake), generated by neural audio codec-based speech generation (CoSG) models, have exhibited suboptimal performance. However, how to train source tracing models using simulated CoSG data while maintaining strong performance on real CoSG-generated audio remains an open challenge. In this paper, we show that models trained solely on codec-resynthesized data tend to overfit to non-speech regions and struggle to generalize to unseen content. To mitigate these challenges, we introduce the Semantic-Acoustic Source Tracing Network (SASTNet), which jointly leverages Whisper for semantic feature encoding and Wav2vec2 with AudioMAE for acoustic feature encoding. Our proposed SASTNet achieves state-of-the-art performance on the CoSG test set of the CodecFake+ dataset, demonstrating its effectiveness for reliable source tracing.
Analysis of ABC Frontend Audio Systems for the NIST-SRE24
May 21, 2025We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy
May 19, 2025



Recent advances in neural audio codec-based speech generation (CoSG) models have produced remarkably realistic audio deepfakes. We refer to deepfake speech generated by CoSG systems as codec-based deepfake, or CodecFake. Although existing anti-spoofing research on CodecFake predominantly focuses on verifying the authenticity of audio samples, almost no attention was given to tracing the CoSG used in generating these deepfakes. In CodecFake generation, processes such as speech-to-unit encoding, discrete unit modeling, and unit-to-speech decoding are fundamentally based on neural audio codecs. Motivated by this, we introduce source tracing for CodecFake via neural audio codec taxonomy, which dissects neural audio codecs to trace CoSG. Our experimental results on the CodecFake+ dataset provide promising initial evidence for the feasibility of CodecFake source tracing while also highlighting several challenges that warrant further investigation.