 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptProver: Bridging Olympiad and Optimization through Continual Training in Formal Theorem Proving
Apr 28, 2026Recent advances in formal theorem proving have focused on Olympiad-level mathematics, leaving undergraduate domains largely unexplored. Optimization, fundamental to machine learning, operations research, and scientific computing, remains underserved by existing provers. Its reliance on domain-specific formalisms (convexity, optimality conditions, and algorithmic analysis) creates significant distribution shift, making naive domain transfer ineffective. We present OptProver, a trained model that achieves robust transfer from Olympiad to undergraduate optimization. Starting from a strong Olympiad-level prover, our pipeline mitigates distribution shift through two key innovations. First, we employ large-scale optimization-focused data curation via expert iteration. Second, we introduce a specialized preference learning objective that integrates perplexity-weighted optimization with a mechanism to penalize valid but non-progressing proof steps. This not only addresses distribution shifts but also guides the search toward efficient trajectories. To enable rigorous evaluation, we construct a novel benchmark in Lean 4 focused on optimization. On this benchmark, OptProver achieves state-of-the-art Pass@1 and Pass@32 among comparably sized models while maintaining competitive performance on general theorem-proving tasks, demonstrating effective domain transfer without catastrophic forgetting.
M2F: Automated Formalization of Mathematical Literature at Scale
Feb 19, 2026Automated formalization of mathematics enables mechanical verification but remains limited to isolated theorems and short snippets. Scaling to textbooks and research papers is largely unaddressed, as it requires managing cross-file dependencies, resolving imports, and ensuring that entire projects compile end-to-end. We present M2F (Math-to-Formal), the first agentic framework for end-to-end, project-scale autoformalization in Lean. The framework operates in two stages. The statement compilation stage splits the document into atomic blocks, orders them via inferred dependencies, and repairs declaration skeletons until the project compiles, allowing placeholders in proofs. The proof repair stage closes these holes under fixed signatures using goal-conditioned local edits. Throughout both stages, M2F keeps the verifier in the loop, committing edits only when toolchain feedback confirms improvement. In approximately three weeks, M2F converts long-form mathematical sources into a project-scale Lean library of 153,853 lines from 479 pages textbooks on real analysis and convex analysis, fully formalized as Lean declarations with accompanying proofs. This represents textbook-scale formalization at a pace that would typically require months or years of expert effort. On FATE-H, we achieve $96\%$ proof success (vs.\ $80\%$ for a strong baseline). Together, these results demonstrate that practical, large-scale automated formalization of mathematical literature is within reach. The full generated Lean code from our runs is available at https://github.com/optsuite/ReasBook.git.
Improving Monte Carlo Tree Search for Symbolic Regression
Sep 19, 2025Symbolic regression aims to discover concise, interpretable mathematical expressions that satisfy desired objectives, such as fitting data, posing a highly combinatorial optimization problem. While genetic programming has been the dominant approach, recent efforts have explored reinforcement learning methods for improving search efficiency. Monte Carlo Tree Search (MCTS), with its ability to balance exploration and exploitation through guided search, has emerged as a promising technique for symbolic expression discovery. However, its traditional bandit strategies and sequential symbol construction often limit performance. In this work, we propose an improved MCTS framework for symbolic regression that addresses these limitations through two key innovations: (1) an extreme bandit allocation strategy tailored for identifying globally optimal expressions, with finite-time performance guarantees under polynomial reward decay assumptions; and (2) evolution-inspired state-jumping actions such as mutation and crossover, which enable non-local transitions to promising regions of the search space. These state-jumping actions also reshape the reward landscape during the search process, improving both robustness and efficiency. We conduct a thorough numerical study to the impact of these improvements and benchmark our approach against existing symbolic regression methods on a variety of datasets, including both ground-truth and black-box datasets. Our approach achieves competitive performance with state-of-the-art libraries in terms of recovery rate, attains favorable positions on the Pareto frontier of accuracy versus model complexity. Code is available at https://github.com/PKU-CMEGroup/MCTS-4-SR.
BigMac: A Communication-Efficient Mixture-of-Experts Model Structure for Fast Training and Inference
Feb 24, 2025The Mixture-of-Experts (MoE) structure scales the Transformer-based large language models (LLMs) and improves their performance with only the sub-linear increase in computation resources. Recently, a fine-grained DeepSeekMoE structure is proposed, which can further improve the computing efficiency of MoE without performance degradation. However, the All-to-All communication introduced by MoE has become a bottleneck, especially for the fine-grained structure, which typically involves and activates more experts, hence contributing to heavier communication overhead. In this paper, we propose a novel MoE structure named BigMac, which is also fine-grained but with high communication efficiency. The innovation of BigMac is mainly due to that we abandon the \textbf{c}ommunicate-\textbf{d}escend-\textbf{a}scend-\textbf{c}ommunicate (CDAC) manner used by fine-grained MoE, which leads to the All-to-All communication always taking place at the highest dimension. Instead, BigMac designs an efficient \textbf{d}escend-\textbf{c}ommunicate-\textbf{c}ommunicate-\textbf{a}scend (DCCA) manner. Specifically, we add a descending and ascending projection at the entrance and exit of the expert, respectively, which enables the communication to perform at a very low dimension. Furthermore, to adapt to DCCA, we re-design the structure of small experts, ensuring that the expert in BigMac has enough complexity to address tokens. Experimental results show that BigMac achieves comparable or even better model quality than fine-grained MoEs with the same number of experts and a similar number of total parameters. Equally importantly, BigMac reduces the end-to-end latency by up to 3.09$\times$ for training and increases the throughput by up to 3.11$\times$ for inference on state-of-the-art AI computing frameworks including Megatron, Tutel, and DeepSpeed-Inference.
Harmonic Retrieval with $L_1$-Tucker Tensor Decomposition
Nov 30, 2021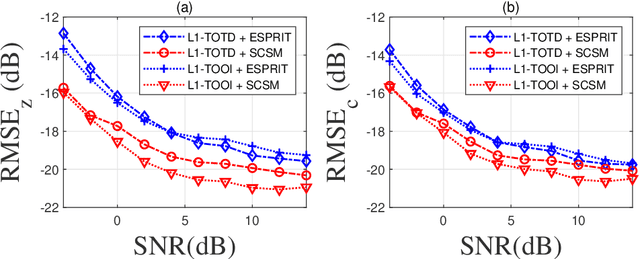
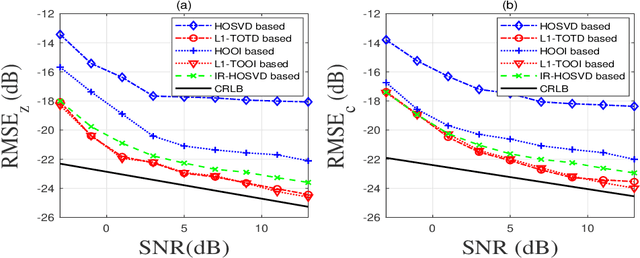
Harmonic retrieval (HR) has a wide range of applications in the scenes where signals are modelled as a summation of sinusoids. Past works have developed a number of approaches to recover the original signals. Most of them rely on classical singular value decomposition, which are vulnerable to unexpected outliers. In this paper, we present new decomposition algorithms of third-order complex-valued tensors with $L_1$-principle component analysis ($L_1$-PCA) of complex data and apply them to a novel random access HR model in presence of outliers. We also develop a novel subcarrier recovery method for the proposed model. Simulations are designed to compare our proposed method with some existing tensor-based algorithms for HR. The results demonstrate the outlier-insensitivity of the proposed method.