 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-Bench: Clue-grounded Question Answering Benchmark for Long Video Understanding
Dec 16, 2024



Most existing video understanding benchmarks for multimodal large language models (MLLMs) focus only on short videos. The limited number of benchmarks for long video understanding often rely solely on multiple-choice questions (MCQs). However, because of the inherent limitation of MCQ-based evaluation and the increasing reasoning ability of MLLMs, models can give the current answer purely by combining short video understanding with elimination, without genuinely understanding the video content. To address this gap, we introduce CG-Bench, a novel benchmark designed for clue-grounded question answering in long videos. CG-Bench emphasizes the model's ability to retrieve relevant clues for questions, enhancing evaluation credibility. It features 1,219 manually curated videos categorized by a granular system with 14 primary categories, 171 secondary categories, and 638 tertiary categories, making it the largest benchmark for long video analysis. The benchmark includes 12,129 QA pairs in three major question types: perception, reasoning, and hallucination. Compensating the drawbacks of pure MCQ-based evaluation, we design two novel clue-based evaluation methods: clue-grounded white box and black box evaluations, to assess whether the model generates answers based on the correct understanding of the video. We evaluate multiple closed-source and open-source MLLMs on CG-Bench. Results indicate that current models significantly underperform in understanding long videos compared to short ones, and a significant gap exists between open-source and commercial models. We hope CG-Bench can advance the development of more trustworthy and capable MLLMs for long video understanding. All annotations and video data are released at https://cg-bench.github.io/leaderboard/.
Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel
Dec 11, 2024
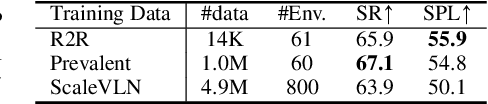

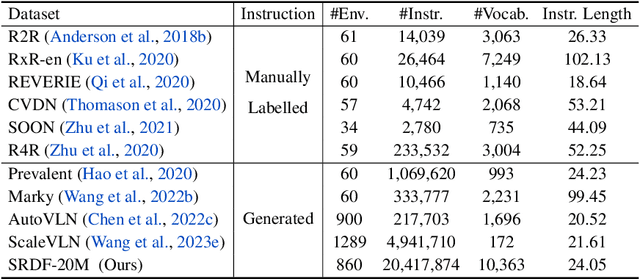
Creating high-quality data for training robust language-instructed agents is a long-lasting challenge in embodied AI. In this paper, we introduce a Self-Refining Data Flywheel (SRDF) that generates high-quality and large-scale navigational instruction-trajectory pairs by iteratively refining the data pool through the collaboration between two models, the instruction generator and the navigator, without any human-in-the-loop annotation. Specifically, SRDF starts with using a base generator to create an initial data pool for training a base navigator, followed by applying the trained navigator to filter the data pool. This leads to higher-fidelity data to train a better generator, which can, in turn, produce higher-quality data for training the next-round navigator. Such a flywheel establishes a data self-refining process, yielding a continuously improved and highly effective dataset for large-scale language-guided navigation learning. Our experiments demonstrate that after several flywheel rounds, the navigator elevates the performance boundary from 70% to 78% SPL on the classic R2R test set, surpassing human performance (76%) for the first time. Meanwhile, this process results in a superior generator, evidenced by a SPICE increase from 23.5 to 26.2, better than all previous VLN instruction generation methods. Finally, we demonstrate the scalability of our method through increasing environment and instruction diversity, and the generalization ability of our pre-trained navigator across various downstream navigation tasks, surpassing state-of-the-art methods by a large margin in all cases.
p-MoD: Building Mixture-of-Depths MLLMs via Progressive Ratio Decay
Dec 05, 2024



Despite the remarkable performance of multimodal large language models (MLLMs) across diverse tasks, the substantial training and inference costs impede their advancement. The majority of computation stems from the overwhelming volume of vision tokens processed by the transformer decoder. In this paper, we propose to build efficient MLLMs by leveraging the Mixture-of-Depths (MoD) mechanism, where each transformer decoder layer selects essential vision tokens to process while skipping redundant ones. However, integrating MoD into MLLMs is non-trivial. To address the challenges of training and inference stability as well as limited training data, we adapt the MoD module with two novel designs: tanh-gated weight normalization (TanhNorm) and symmetric token reweighting (STRing). Moreover, we observe that vision tokens exhibit higher redundancy in deeper layer and thus design a progressive ratio decay (PRD) strategy, which gradually reduces the token retention ratio layer by layer, employing a shifted cosine schedule. This crucial design fully unleashes the potential of MoD, significantly boosting the efficiency and performance of our models. To validate the effectiveness of our approach, we conduct extensive experiments with two baseline models across 14 benchmarks. Our model, p-MoD, matches or even surpasses the performance of the baseline models, with only 55.6% TFLOPs and 53.8% KV cache storage during inference, and 77.7% GPU hours during training.
SA-GNAS: Seed Architecture Expansion for Efficient Large-scale Graph Neural Architecture Search
Dec 03, 2024



GNAS (Graph Neural Architecture Search) has demonstrated great effectiveness in automatically designing the optimal graph neural architectures for multiple downstream tasks, such as node classification and link prediction. However, most existing GNAS methods cannot efficiently handle large-scale graphs containing more than million-scale nodes and edges due to the expensive computational and memory overhead. To scale GNAS on large graphs while achieving better performance, we propose SA-GNAS, a novel framework based on seed architecture expansion for efficient large-scale GNAS. Similar to the cell expansion in biotechnology, we first construct a seed architecture and then expand the seed architecture iteratively. Specifically, we first propose a performance ranking consistency-based seed architecture selection method, which selects the architecture searched on the subgraph that best matches the original large-scale graph. Then, we propose an entropy minimization-based seed architecture expansion method to further improve the performance of the seed architecture. Extensive experimental results on five large-scale graphs demonstrate that the proposed SA-GNAS outperforms human-designed state-of-the-art GNN architectures and existing graph NAS methods. Moreover, SA-GNAS can significantly reduce the search time, showing better search efficiency. For the largest graph with billion edges, SA-GNAS can achieve 2.8 times speedup compared to the SOTA large-scale GNAS method GAUSS. Additionally, since SA-GNAS is inherently parallelized, the search efficiency can be further improved with more GPUs. SA-GNAS is available at https://github.com/PasaLab/SAGNAS.
Taming Scalable Visual Tokenizer for Autoregressive Image Generation
Dec 03, 2024



Existing vector quantization (VQ) methods struggle with scalability, largely attributed to the instability of the codebook that undergoes partial updates during training. The codebook is prone to collapse as utilization decreases, due to the progressively widening distribution gap between non-activated codes and visual features. To solve the problem, we propose Index Backpropagation Quantization (IBQ), a new VQ method for the joint optimization of all codebook embeddings and the visual encoder. Applying a straight-through estimator on the one-hot categorical distribution between the encoded feature and codebook, all codes are differentiable and maintain a consistent latent space with the visual encoder. IBQ enables scalable training of visual tokenizers and, for the first time, achieves a large-scale codebook ($2^{18}$) with high dimension ($256$) and high utilization. Experiments on the standard ImageNet benchmark demonstrate the scalability and superiority of IBQ, achieving competitive results on both reconstruction ($1.00$ rFID) and autoregressive visual generation ($2.05$ gFID). The code and models are available at https://github.com/TencentARC/SEED-Voken.
Graph-Enhanced EEG Foundation Model
Nov 29, 2024



Electroencephalography (EEG) signals provide critical insights for applications in disease diagnosis and healthcare. However, the scarcity of labeled EEG data poses a significant challenge. Foundation models offer a promising solution by leveraging large-scale unlabeled data through pre-training, enabling strong performance across diverse tasks. While both temporal dynamics and inter-channel relationships are vital for understanding EEG signals, existing EEG foundation models primarily focus on the former, overlooking the latter. To address this limitation, we propose a novel foundation model for EEG that integrates both temporal and inter-channel information. Our architecture combines Graph Neural Networks (GNNs), which effectively capture relational structures, with a masked autoencoder to enable efficient pre-training. We evaluated our approach using three downstream tasks and experimented with various GNN architectures. The results demonstrate that our proposed model, particularly when employing the GCN architecture with optimized configurations, consistently outperformed baseline methods across all tasks. These findings suggest that our model serves as a robust foundation model for EEG analysis.
Tra-MoE: Learning Trajectory Prediction Model from Multiple Domains for Adaptive Policy Conditioning
Nov 21, 2024



Learning from multiple domains is a primary factor that influences the generalization of a single unified robot system. In this paper, we aim to learn the trajectory prediction model by using broad out-of-domain data to improve its performance and generalization ability. Trajectory model is designed to predict any-point trajectories in the current frame given an instruction and can provide detailed control guidance for robotic policy learning. To handle the diverse out-of-domain data distribution, we propose a sparsely-gated MoE (\textbf{Top-1} gating strategy) architecture for trajectory model, coined as \textbf{Tra-MoE}. The sparse activation design enables good balance between parameter cooperation and specialization, effectively benefiting from large-scale out-of-domain data while maintaining constant FLOPs per token. In addition, we further introduce an adaptive policy conditioning technique by learning 2D mask representations for predicted trajectories, which is explicitly aligned with image observations to guide action prediction more flexibly. We perform extensive experiments on both simulation and real-world scenarios to verify the effectiveness of Tra-MoE and adaptive policy conditioning technique. We also conduct a comprehensive empirical study to train Tra-MoE, demonstrating that our Tra-MoE consistently exhibits superior performance compared to the dense baseline model, even when the latter is scaled to match Tra-MoE's parameter count.
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models
Nov 20, 2024



Video generation has witnessed significant advancements, yet evaluating these models remains a challenge. A comprehensive evaluation benchmark for video generation is indispensable for two reasons: 1) Existing metrics do not fully align with human perceptions; 2) An ideal evaluation system should provide insights to inform future developments of video generation. To this end, we present VBench, a comprehensive benchmark suite that dissects "video generation quality" into specific, hierarchical, and disentangled dimensions, each with tailored prompts and evaluation methods. VBench has several appealing properties: 1) Comprehensive Dimensions: VBench comprises 16 dimensions in video generation (e.g., subject identity inconsistency, motion smoothness, temporal flickering, and spatial relationship, etc). The evaluation metrics with fine-grained levels reveal individual models' strengths and weaknesses. 2) Human Alignment: We also provide a dataset of human preference annotations to validate our benchmarks' alignment with human perception, for each evaluation dimension respectively. 3) Valuable Insights: We look into current models' ability across various evaluation dimensions, and various content types. We also investigate the gaps between video and image generation models. 4) Versatile Benchmarking: VBench++ supports evaluating text-to-video and image-to-video. We introduce a high-quality Image Suite with an adaptive aspect ratio to enable fair evaluations across different image-to-video generation settings. Beyond assessing technical quality, VBench++ evaluates the trustworthiness of video generative models, providing a more holistic view of model performance. 5) Full Open-Sourcing: We fully open-source VBench++ and continually add new video generation models to our leaderboard to drive forward the field of video generation.
FlowDCN: Exploring DCN-like Architectures for Fast Image Generation with Arbitrary Resolution
Oct 30, 2024



Arbitrary-resolution image generation still remains a challenging task in AIGC, as it requires handling varying resolutions and aspect ratios while maintaining high visual quality. Existing transformer-based diffusion methods suffer from quadratic computation cost and limited resolution extrapolation capabilities, making them less effective for this task. In this paper, we propose FlowDCN, a purely convolution-based generative model with linear time and memory complexity, that can efficiently generate high-quality images at arbitrary resolutions. Equipped with a new design of learnable group-wise deformable convolution block, our FlowDCN yields higher flexibility and capability to handle different resolutions with a single model. FlowDCN achieves the state-of-the-art 4.30 sFID on $256\times256$ ImageNet Benchmark and comparable resolution extrapolation results, surpassing transformer-based counterparts in terms of convergence speed (only $\frac{1}{5}$ images), visual quality, parameters ($8\%$ reduction) and FLOPs ($20\%$ reduction). We believe FlowDCN offers a promising solution to scalable and flexible image synthesis.
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Oct 25, 2024



Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.