 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Chemistry Reasoning with Large Language Models
Nov 16, 2023This paper studies the problem of solving complex chemistry problems with large language models (LLMs). Despite the extensive general knowledge in LLMs (such as GPT-4), they struggle with chemistry reasoning that requires faithful grounded reasoning with diverse chemical knowledge and an integrative understanding of chemical interactions. We propose InstructChem, a new structured reasoning approach that substantially boosts the LLMs' chemical reasoning capabilities. InstructChem explicitly decomposes the reasoning into three critical phrases, including chemical formulae generation by LLMs that offers the basis for subsequent grounded reasoning, step-by-step reasoning that makes multi-step derivations with the identified formulae for a preliminary answer, and iterative review-and-refinement that steers LLMs to progressively revise the previous phases for increasing confidence, leading to the final high-confidence answer. We conduct extensive experiments on four different chemistry challenges, including quantum chemistry, quantum mechanics, physical chemistry, and chemistry kinetics. Our approach significantly enhances GPT-4 on chemistry reasoning, yielding an 8% average absolute improvement and a 30% peak improvement. We further use the generated reasoning by GPT-4 to fine-tune smaller LMs (e.g., Vicuna) and observe strong improvement of the smaller LMs. This validates our approach and enables LLMs to generate high-quality reasoning.
MacGyver: Are Large Language Models Creative Problem Solvers?
Nov 16, 2023



We explore the creative problem-solving capabilities of modern large language models (LLMs) in a constrained setting. The setting requires circumventing a cognitive bias known in psychology as ''functional fixedness'' to use familiar objects in innovative or unconventional ways. To this end, we create MacGyver, an automatically generated dataset consisting of 1,600 real-world problems that deliberately trigger functional fixedness and require thinking 'out-of-the-box'. We then present our collection of problems to both LLMs and humans to compare and contrast their problem-solving abilities. We show that MacGyver is challenging for both groups, but in unique and complementary ways. For example, humans typically excel in solving problems that they are familiar with but may struggle with tasks requiring domain-specific knowledge, leading to a higher variance. On the other hand, LLMs, being exposed to a variety of highly specialized knowledge, attempt broader problems but are prone to overconfidence and propose actions that are physically infeasible or inefficient. We also provide a detailed error analysis of LLMs, and demonstrate the potential of enhancing their problem-solving ability with novel prompting techniques such as iterative step-wise reflection and divergent-convergent thinking. This work provides insight into the creative problem-solving capabilities of humans and AI and illustrates how psychological paradigms can be extended into large-scale tasks for comparing humans and machines.
Inference-Time Policy Adapters (IPA): Tailoring Extreme-Scale LMs without Fine-tuning
May 24, 2023Large language models excel at a variety of language tasks when prompted with examples or instructions. Yet controlling these models through prompting alone is limited. Tailoring language models through fine-tuning (e.g., via reinforcement learning) can be effective, but it is expensive and requires model access. We propose Inference-time Policy Adapters (IPA), which efficiently tailors a language model such as GPT-3 without fine-tuning it. IPA guides a large base model during decoding time through a lightweight policy adaptor trained to optimize an arbitrary user objective with reinforcement learning. On five challenging text generation tasks, such as toxicity reduction and open-domain generation, IPA consistently brings significant improvements over off-the-shelf language models. It outperforms competitive baseline methods, sometimes even including expensive fine-tuning. In particular, tailoring GPT-2 with IPA can outperform GPT-3, while tailoring GPT- 3 with IPA brings a major performance boost over GPT-3 (and sometimes even over GPT-4). Our promising results highlight the potential of IPA as a lightweight alternative to tailoring extreme-scale language models.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Quark: Controllable Text Generation with Reinforced Unlearning
May 26, 2022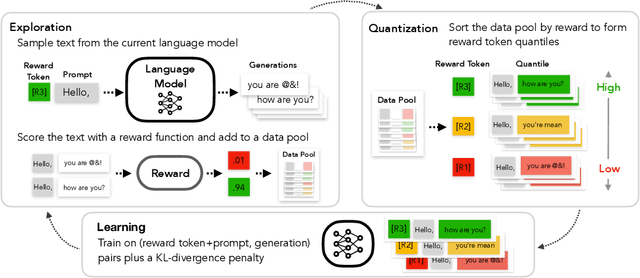
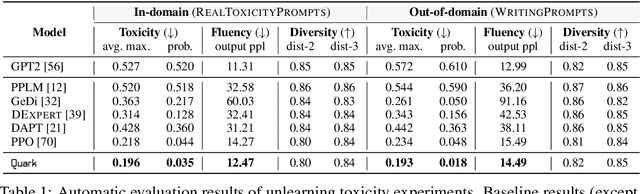
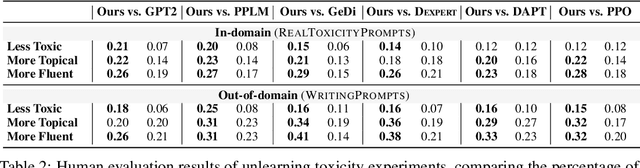

Large-scale language models often learn behaviors that are misaligned with user expectations. Generated text may contain offensive or toxic language, contain significant repetition, or be of a different sentiment than desired by the user. We consider the task of unlearning these misalignments by fine-tuning the language model on signals of what not to do. We introduce Quantized Reward Konditioning (Quark), an algorithm for optimizing a reward function that quantifies an (un)wanted property, while not straying too far from the original model. Quark alternates between (i) collecting samples with the current language model, (ii) sorting them into quantiles based on reward, with each quantile identified by a reward token prepended to the language model's input, and (iii) using a standard language modeling loss on samples from each quantile conditioned on its reward token, while remaining nearby the original language model via a KL-divergence penalty. By conditioning on a high-reward token at generation time, the model generates text that exhibits less of the unwanted property. For unlearning toxicity, negative sentiment, and repetition, our experiments show that Quark outperforms both strong baselines and state-of-the-art reinforcement learning methods like PPO (Schulman et al. 2017), while relying only on standard language modeling primitives.
Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations
May 24, 2022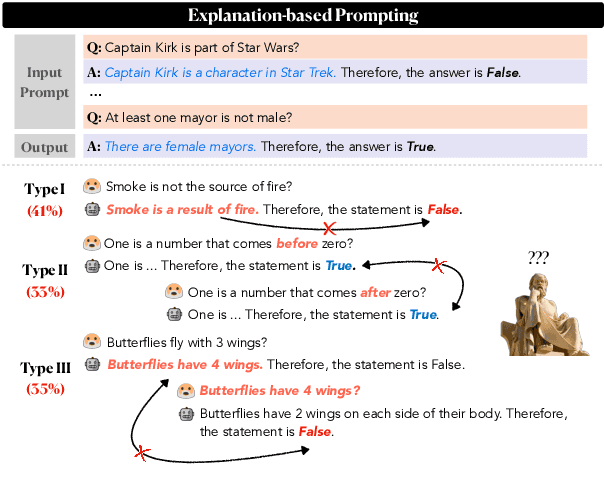
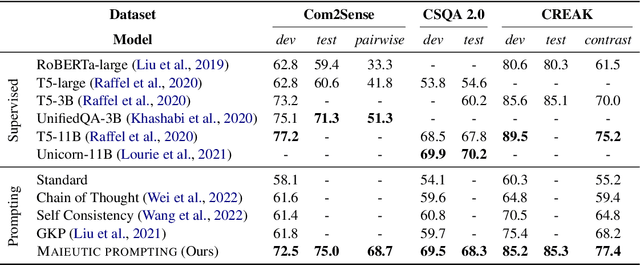
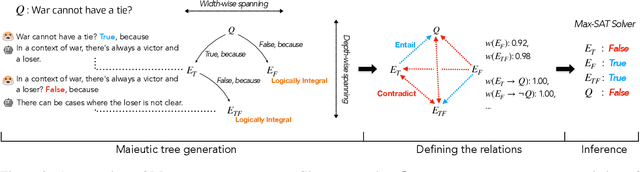

Despite their impressive capabilities, large pre-trained language models (LMs) struggle with consistent reasoning; recently, prompting LMs to generate explanations that self-guide the inference has emerged as a promising direction to amend this. However, these approaches are fundamentally bounded by the correctness of explanations, which themselves are often noisy and inconsistent. In this work, we develop Maieutic Prompting, which infers a correct answer to a question even from the noisy and inconsistent generations of LM. Maieutic Prompting induces a tree of explanations abductively (e.g. X is true, because ...) and recursively, then frames the inference as a satisfiability problem over these explanations and their logical relations. We test Maieutic Prompting for true/false QA on three challenging benchmarks that require complex commonsense reasoning. Maieutic Prompting achieves up to 20% better accuracy than state-of-the-art prompting methods, and as a fully unsupervised approach, performs competitively with supervised models. We also show that Maieutic Prompting improves robustness in inference while providing interpretable rationales.
COLD Decoding: Energy-based Constrained Text Generation with Langevin Dynamics
Mar 27, 2022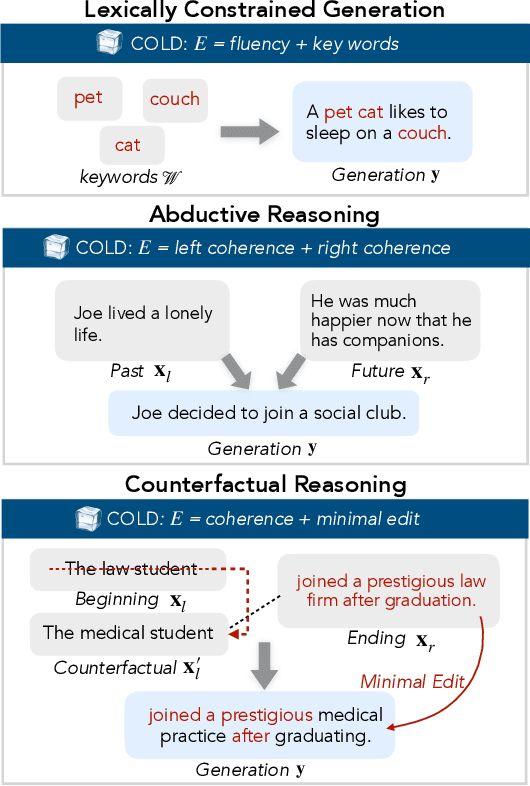

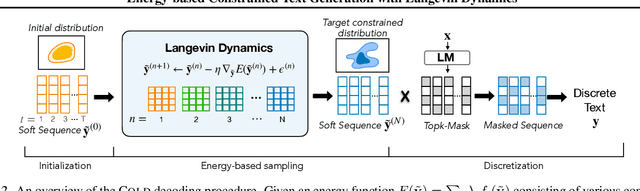

Many applications of text generation require incorporating different constraints to control the semantics or style of generated text. These constraints can be hard (e.g., ensuring certain keywords are included in the output) and soft (e.g., contextualizing the output with the left- or right-hand context). In this paper, we present Energy-based Constrained Decoding with Langevin Dynamics (COLD), a decoding framework which unifies constrained generation as specifying constraints through an energy function, then performing efficient differentiable reasoning over the constraints through gradient-based sampling. COLD decoding is a flexible framework that can be applied directly to off-the-shelf left-to-right language models without the need for any task-specific fine-tuning, as demonstrated through three challenging text generation applications: lexically-constrained generation, abductive reasoning, and counterfactual reasoning. Our experiments on these constrained generation tasks point to the effectiveness of our approach, both in terms of automatic and human evaluation.
Diversifying Content Generation for Commonsense Reasoning with Mixture of Knowledge Graph Experts
Mar 14, 2022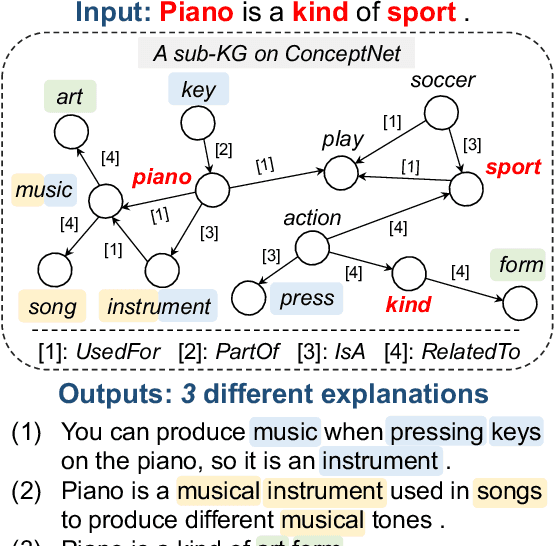
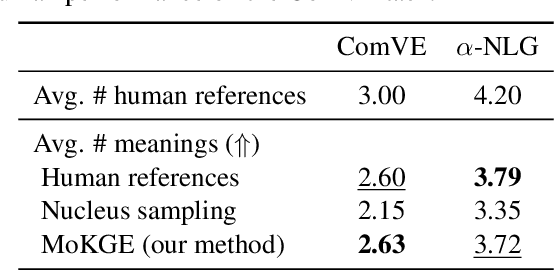
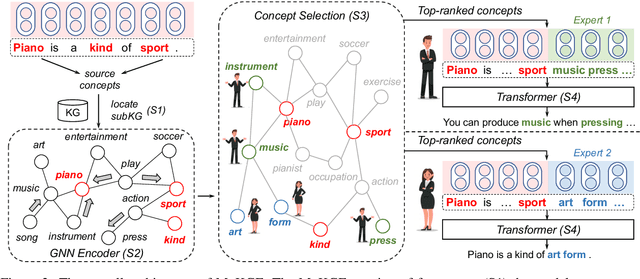
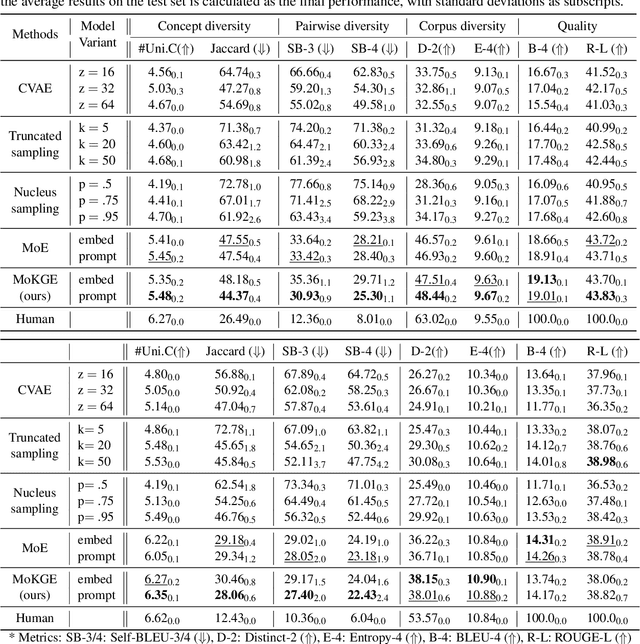
Generative commonsense reasoning (GCR) in natural language is to reason about the commonsense while generating coherent text. Recent years have seen a surge of interest in improving the generation quality of commonsense reasoning tasks. Nevertheless, these approaches have seldom investigated diversity in the GCR tasks, which aims to generate alternative explanations for a real-world situation or predict all possible outcomes. Diversifying GCR is challenging as it expects to generate multiple outputs that are not only semantically different but also grounded in commonsense knowledge. In this paper, we propose MoKGE, a novel method that diversifies the generative reasoning by a mixture of expert (MoE) strategy on commonsense knowledge graphs (KG). A set of knowledge experts seek diverse reasoning on KG to encourage various generation outputs. Empirical experiments demonstrated that MoKGE can significantly improve the diversity while achieving on par performance on accuracy on two GCR benchmarks, based on both automatic and human evaluations.
NeuroLogic A*esque Decoding: Constrained Text Generation with Lookahead Heuristics
Dec 16, 2021

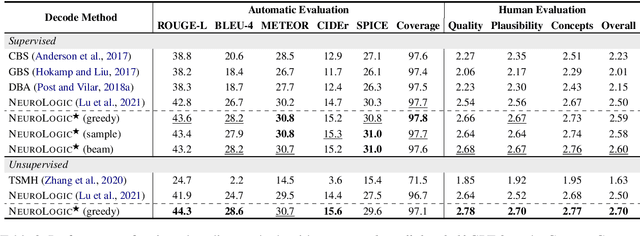
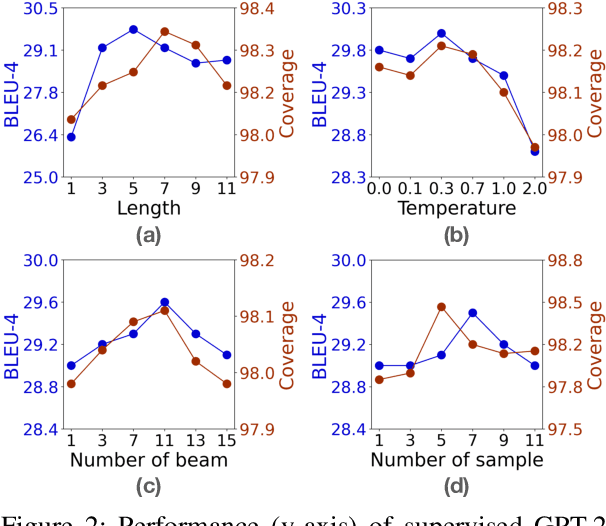
The dominant paradigm for neural text generation is left-to-right decoding from autoregressive language models. Constrained or controllable generation under complex lexical constraints, however, requires foresight to plan ahead feasible future paths. Drawing inspiration from the A* search algorithm, we propose NeuroLogic A*esque, a decoding algorithm that incorporates heuristic estimates of future cost. We develop efficient lookahead heuristics that are efficient for large-scale language models, making our method a drop-in replacement for common techniques such as beam search and top-k sampling. To enable constrained generation, we build on NeuroLogic decoding (Lu et al., 2021), combining its flexibility in incorporating logical constraints with A*esque estimates of future constraint satisfaction. Our approach outperforms competitive baselines on five generation tasks, and achieves new state-of-the-art performance on table-to-text generation, constrained machine translation, and keyword-constrained generation. The improvements are particularly notable on tasks that require complex constraint satisfaction or in few-shot or zero-shot settings. NeuroLogic A*esque illustrates the power of decoding for improving and enabling new capabilities of large-scale language models.
PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
Dec 15, 2021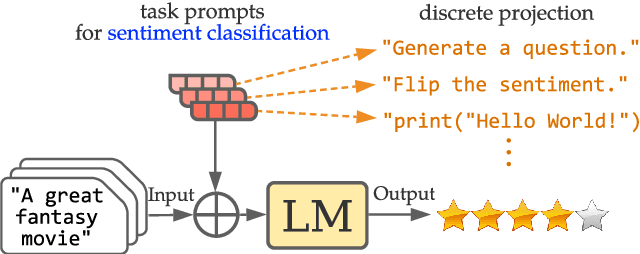
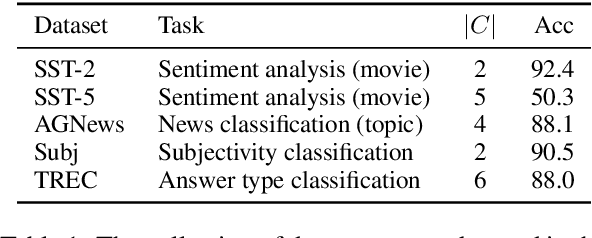
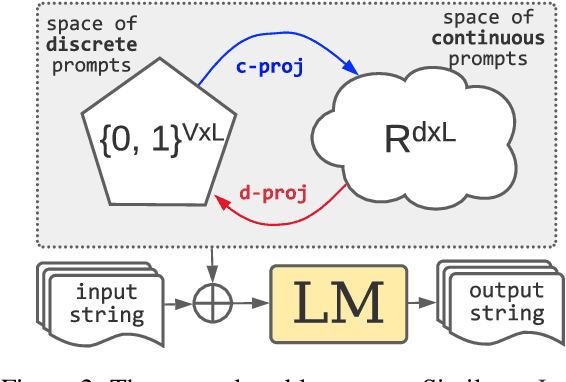
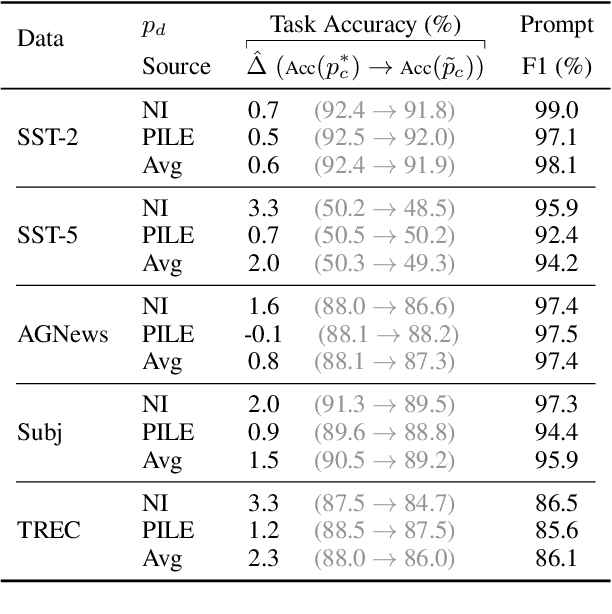
Fine-tuning continuous prompts for target tasks has recently emerged as a compact alternative to full model fine-tuning. Motivated by these promising results, we investigate the feasibility of extracting a discrete (textual) interpretation of continuous prompts that is faithful to the problem they solve. In practice, we observe a "wayward" behavior between the task solved by continuous prompts and their nearest neighbor discrete projections: We can find continuous prompts that solve a task while being projected to an arbitrary text (e.g., definition of a different or even a contradictory task), while being within a very small (2%) margin of the best continuous prompt of the same size for the task. We provide intuitions behind this odd and surprising behavior, as well as extensive empirical analyses quantifying the effect of various parameters. For instance, for larger model sizes we observe higher waywardness, i.e, we can find prompts that more closely map to any arbitrary text with a smaller drop in accuracy. These findings have important implications relating to the difficulty of faithfully interpreting continuous prompts and their generalization across models and tasks, providing guidance for future progress in prompting language models.