 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Noise to Latent: Generating Gaussian Latents for INR-Based Image Compression
Nov 11, 2025Recent implicit neural representation (INR)-based image compression methods have shown competitive performance by overfitting image-specific latent codes. However, they remain inferior to end-to-end (E2E) compression approaches due to the absence of expressive latent representations. On the other hand, E2E methods rely on transmitting latent codes and requiring complex entropy models, leading to increased decoding complexity. Inspired by the normalization strategy in E2E codecs where latents are transformed into Gaussian noise to demonstrate the removal of spatial redundancy, we explore the inverse direction: generating latents directly from Gaussian noise. In this paper, we propose a novel image compression paradigm that reconstructs image-specific latents from a multi-scale Gaussian noise tensor, deterministically generated using a shared random seed. A Gaussian Parameter Prediction (GPP) module estimates the distribution parameters, enabling one-shot latent generation via reparameterization trick. The predicted latent is then passed through a synthesis network to reconstruct the image. Our method eliminates the need to transmit latent codes while preserving latent-based benefits, achieving competitive rate-distortion performance on Kodak and CLIC dataset. To the best of our knowledge, this is the first work to explore Gaussian latent generation for learned image compression.
Exploring Category-level Articulated Object Pose Tracking on SE(3) Manifolds
Nov 08, 2025Articulated objects are prevalent in daily life and robotic manipulation tasks. However, compared to rigid objects, pose tracking for articulated objects remains an underexplored problem due to their inherent kinematic constraints. To address these challenges, this work proposes a novel point-pair-based pose tracking framework, termed \textbf{PPF-Tracker}. The proposed framework first performs quasi-canonicalization of point clouds in the SE(3) Lie group space, and then models articulated objects using Point Pair Features (PPF) to predict pose voting parameters by leveraging the invariance properties of SE(3). Finally, semantic information of joint axes is incorporated to impose unified kinematic constraints across all parts of the articulated object. PPF-Tracker is systematically evaluated on both synthetic datasets and real-world scenarios, demonstrating strong generalization across diverse and challenging environments. Experimental results highlight the effectiveness and robustness of PPF-Tracker in multi-frame pose tracking of articulated objects. We believe this work can foster advances in robotics, embodied intelligence, and augmented reality. Codes are available at https://github.com/mengxh20/PPFTracker.
SecureReviewer: Enhancing Large Language Models for Secure Code Review through Secure-aware Fine-tuning
Oct 30, 2025Identifying and addressing security issues during the early phase of the development lifecycle is critical for mitigating the long-term negative impacts on software systems. Code review serves as an effective practice that enables developers to check their teammates' code before integration into the codebase. To streamline the generation of review comments, various automated code review approaches have been proposed, where LLM-based methods have significantly advanced the capabilities of automated review generation. However, existing models primarily focus on general-purpose code review, their effectiveness in identifying and addressing security-related issues remains underexplored. Moreover, adapting existing code review approaches to target security issues faces substantial challenges, including data scarcity and inadequate evaluation metrics. To address these limitations, we propose SecureReviewer, a new approach designed for enhancing LLMs' ability to identify and resolve security-related issues during code review. Specifically, we first construct a dataset tailored for training and evaluating secure code review capabilities. Leveraging this dataset, we fine-tune LLMs to generate code review comments that can effectively identify security issues and provide fix suggestions with our proposed secure-aware fine-tuning strategy. To mitigate hallucination in LLMs and enhance the reliability of their outputs, we integrate the RAG technique, which grounds the generated comments in domain-specific security knowledge. Additionally, we introduce SecureBLEU, a new evaluation metric designed to assess the effectiveness of review comments in addressing security issues. Experimental results demonstrate that SecureReviewer outperforms state-of-the-art baselines in both security issue detection accuracy and the overall quality and practical utility of generated review comments.
Projection Embedded Diffusion Bridge for CT Reconstruction from Incomplete Data
Oct 26, 2025Reconstructing CT images from incomplete projection data remains challenging due to the ill-posed nature of the problem. Diffusion bridge models have recently shown promise in restoring clean images from their corresponding Filtered Back Projection (FBP) reconstructions, but incorporating data consistency into these models remains largely underexplored. Incorporating data consistency can improve reconstruction fidelity by aligning the reconstructed image with the observed projection data, and can enhance detail recovery by integrating structural information contained in the projections. In this work, we propose the Projection Embedded Diffusion Bridge (PEDB). PEDB introduces a novel reverse stochastic differential equation (SDE) to sample from the distribution of clean images conditioned on both the FBP reconstruction and the incomplete projection data. By explicitly conditioning on the projection data in sampling the clean images, PEDB naturally incorporates data consistency. We embed the projection data into the score function of the reverse SDE. Under certain assumptions, we derive a tractable expression for the posterior score. In addition, we introduce a free parameter to control the level of stochasticity in the reverse process. We also design a discretization scheme for the reverse SDE to mitigate discretization error. Extensive experiments demonstrate that PEDB achieves strong performance in CT reconstruction from three types of incomplete data, including sparse-view, limited-angle, and truncated projections. For each of these types, PEDB outperforms evaluated state-of-the-art diffusion bridge models across standard, noisy, and domain-shift evaluations.
A method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
An Empirical Study on Failures in Automated Issue Solving
Sep 17, 2025Automated issue solving seeks to autonomously identify and repair defective code snippets across an entire codebase. SWE-Bench has emerged as the most widely adopted benchmark for evaluating progress in this area. While LLM-based agentic tools show great promise, they still fail on a substantial portion of tasks. Moreover, current evaluations primarily report aggregate issue-solving rates, which obscure the underlying causes of success and failure, making it challenging to diagnose model weaknesses or guide targeted improvements. To bridge this gap, we first analyze the performance and efficiency of three SOTA tools, spanning both pipeline-based and agentic architectures, in automated issue solving tasks of SWE-Bench-Verified under varying task characteristics. Furthermore, to move from high-level performance metrics to underlying cause analysis, we conducted a systematic manual analysis of 150 failed instances. From this analysis, we developed a comprehensive taxonomy of failure modes comprising 3 primary phases, 9 main categories, and 25 fine-grained subcategories. Then we systematically analyze the distribution of the identified failure modes, the results reveal distinct failure fingerprints between the two architectural paradigms, with the majority of agentic failures stemming from flawed reasoning and cognitive deadlocks. Motivated by these insights, we propose a collaborative Expert-Executor framework. It introduces a supervisory Expert agent tasked with providing strategic oversight and course-correction for a primary Executor agent. This architecture is designed to correct flawed reasoning and break the cognitive deadlocks that frequently lead to failure. Experiments show that our framework solves 22.2% of previously intractable issues for a leading single agent. These findings pave the way for building more robust agents through diagnostic evaluation and collaborative design.
Multimodal Foundation Model-Driven User Interest Modeling and Behavior Analysis on Short Video Platforms
Sep 05, 2025With the rapid expansion of user bases on short video platforms, personalized recommendation systems are playing an increasingly critical role in enhancing user experience and optimizing content distribution. Traditional interest modeling methods often rely on unimodal data, such as click logs or text labels, which limits their ability to fully capture user preferences in a complex multimodal content environment. To address this challenge, this paper proposes a multimodal foundation model-based framework for user interest modeling and behavior analysis. By integrating video frames, textual descriptions, and background music into a unified semantic space using cross-modal alignment strategies, the framework constructs fine-grained user interest vectors. Additionally, we introduce a behavior-driven feature embedding mechanism that incorporates viewing, liking, and commenting sequences to model dynamic interest evolution, thereby improving both the timeliness and accuracy of recommendations. In the experimental phase, we conduct extensive evaluations using both public and proprietary short video datasets, comparing our approach against multiple mainstream recommendation algorithms and modeling techniques. Results demonstrate significant improvements in behavior prediction accuracy, interest modeling for cold-start users, and recommendation click-through rates. Moreover, we incorporate interpretability mechanisms using attention weights and feature visualization to reveal the model's decision basis under multimodal inputs and trace interest shifts, thereby enhancing the transparency and controllability of the recommendation system.
Neural Video Compression with In-Loop Contextual Filtering and Out-of-Loop Reconstruction Enhancement
Sep 04, 2025This paper explores the application of enhancement filtering techniques in neural video compression. Specifically, we categorize these techniques into in-loop contextual filtering and out-of-loop reconstruction enhancement based on whether the enhanced representation affects the subsequent coding loop. In-loop contextual filtering refines the temporal context by mitigating error propagation during frame-by-frame encoding. However, its influence on both the current and subsequent frames poses challenges in adaptively applying filtering throughout the sequence. To address this, we introduce an adaptive coding decision strategy that dynamically determines filtering application during encoding. Additionally, out-of-loop reconstruction enhancement is employed to refine the quality of reconstructed frames, providing a simple yet effective improvement in coding efficiency. To the best of our knowledge, this work presents the first systematic study of enhancement filtering in the context of conditional-based neural video compression. Extensive experiments demonstrate a 7.71% reduction in bit rate compared to state-of-the-art neural video codecs, validating the effectiveness of the proposed approach.
LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving
Aug 17, 2025
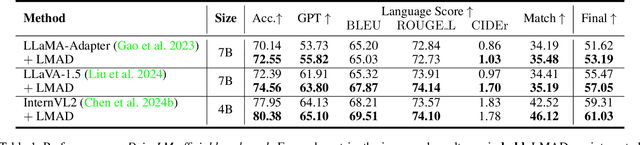

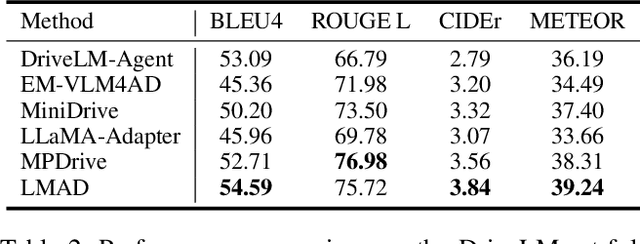
Large vision-language models (VLMs) have shown promising capabilities in scene understanding, enhancing the explainability of driving behaviors and interactivity with users. Existing methods primarily fine-tune VLMs on on-board multi-view images and scene reasoning text, but this approach often lacks the holistic and nuanced scene recognition and powerful spatial awareness required for autonomous driving, especially in complex situations. To address this gap, we propose a novel vision-language framework tailored for autonomous driving, called LMAD. Our framework emulates modern end-to-end driving paradigms by incorporating comprehensive scene understanding and a task-specialized structure with VLMs. In particular, we introduce preliminary scene interaction and specialized expert adapters within the same driving task structure, which better align VLMs with autonomous driving scenarios. Furthermore, our approach is designed to be fully compatible with existing VLMs while seamlessly integrating with planning-oriented driving systems. Extensive experiments on the DriveLM and nuScenes-QA datasets demonstrate that LMAD significantly boosts the performance of existing VLMs on driving reasoning tasks,setting a new standard in explainable autonomous driving.
Adaptive High-Frequency Preprocessing for Video Coding
Aug 12, 2025
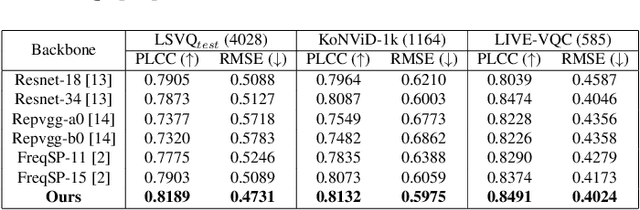
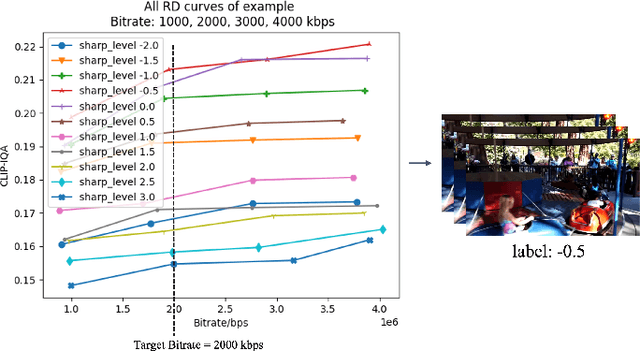
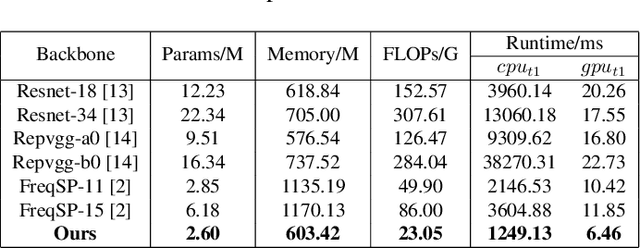
High-frequency components are crucial for maintaining video clarity and realism, but they also significantly impact coding bitrate, resulting in increased bandwidth and storage costs. This paper presents an end-to-end learning-based framework for adaptive high-frequency preprocessing to enhance subjective quality and save bitrate in video coding. The framework employs the Frequency-attentive Feature pyramid Prediction Network (FFPN) to predict the optimal high-frequency preprocessing strategy, guiding subsequent filtering operators to achieve the optimal tradeoff between bitrate and quality after compression. For training FFPN, we pseudo-label each training video with the optimal strategy, determined by comparing the rate-distortion (RD) performance across different preprocessing types and strengths. Distortion is measured using the latest quality assessment metric. Comprehensive evaluations on multiple datasets demonstrate the visually appealing enhancement capabilities and bitrate savings achieved by our framework.