 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation of Large Language Models
Jun 14, 2023Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge from white-box generative LLMs is still under-explored, which becomes more and more important with the prosperity of LLMs. In this work, we propose MiniLLM that distills smaller language models from generative larger language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. Extensive experiments in the instruction-following setting show that the MiniLLM models generate more precise responses with the higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance. Our method is also scalable for different model families with 120M to 13B parameters. We will release our code and model checkpoints at https://aka.ms/MiniLLM.
Augmenting Language Models with Long-Term Memory
Jun 12, 2023Existing large language models (LLMs) can only afford fix-sized inputs due to the input length limit, preventing them from utilizing rich long-context information from past inputs. To address this, we propose a framework, Language Models Augmented with Long-Term Memory (LongMem), which enables LLMs to memorize long history. We design a novel decoupled network architecture with the original backbone LLM frozen as a memory encoder and an adaptive residual side-network as a memory retriever and reader. Such a decoupled memory design can easily cache and update long-term past contexts for memory retrieval without suffering from memory staleness. Enhanced with memory-augmented adaptation training, LongMem can thus memorize long past context and use long-term memory for language modeling. The proposed memory retrieval module can handle unlimited-length context in its memory bank to benefit various downstream tasks. Typically, LongMem can enlarge the long-form memory to 65k tokens and thus cache many-shot extra demonstration examples as long-form memory for in-context learning. Experiments show that our method outperforms strong long-context models on ChapterBreak, a challenging long-context modeling benchmark, and achieves remarkable improvements on memory-augmented in-context learning over LLMs. The results demonstrate that the proposed method is effective in helping language models to memorize and utilize long-form contents. Our code is open-sourced at https://aka.ms/LongMem.
Pre-Training to Learn in Context
May 16, 2023In-context learning, where pre-trained language models learn to perform tasks from task examples and instructions in their contexts, has attracted much attention in the NLP community. However, the ability of in-context learning is not fully exploited because language models are not explicitly trained to learn in context. To this end, we propose PICL (Pre-training for In-Context Learning), a framework to enhance the language models' in-context learning ability by pre-training the model on a large collection of "intrinsic tasks" in the general plain-text corpus using the simple language modeling objective. PICL encourages the model to infer and perform tasks by conditioning on the contexts while maintaining task generalization of pre-trained models. We evaluate the in-context learning performance of the model trained with PICL on seven widely-used text classification datasets and the Super-NaturalInstrctions benchmark, which contains 100+ NLP tasks formulated to text generation. Our experiments show that PICL is more effective and task-generalizable than a range of baselines, outperforming larger language models with nearly 4x parameters. The code is publicly available at https://github.com/thu-coai/PICL.
Language Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023



A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
Generic-to-Specific Distillation of Masked Autoencoders
Feb 28, 2023



Large vision Transformers (ViTs) driven by self-supervised pre-training mechanisms achieved unprecedented progress. Lightweight ViT models limited by the model capacity, however, benefit little from those pre-training mechanisms. Knowledge distillation defines a paradigm to transfer representations from large (teacher) models to small (student) ones. However, the conventional single-stage distillation easily gets stuck on task-specific transfer, failing to retain the task-agnostic knowledge crucial for model generalization. In this study, we propose generic-to-specific distillation (G2SD), to tap the potential of small ViT models under the supervision of large models pre-trained by masked autoencoders. In generic distillation, decoder of the small model is encouraged to align feature predictions with hidden representations of the large model, so that task-agnostic knowledge can be transferred. In specific distillation, predictions of the small model are constrained to be consistent with those of the large model, to transfer task-specific features which guarantee task performance. With G2SD, the vanilla ViT-Small model respectively achieves 98.7%, 98.1% and 99.3% the performance of its teacher (ViT-Base) for image classification, object detection, and semantic segmentation, setting a solid baseline for two-stage vision distillation. Code will be available at https://github.com/pengzhiliang/G2SD.
Semi-Supervised Learning with Pseudo-Negative Labels for Image Classification
Jan 10, 2023
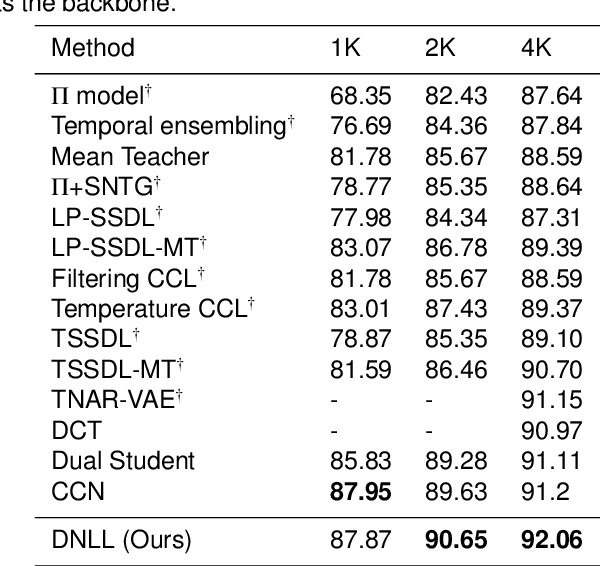

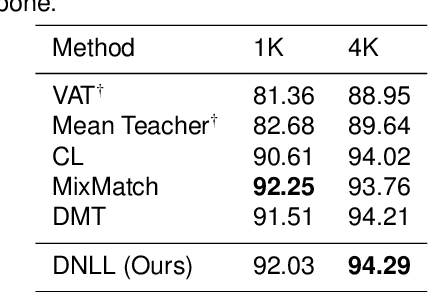
Semi-supervised learning frameworks usually adopt mutual learning approaches with multiple submodels to learn from different perspectives. To avoid transferring erroneous pseudo labels between these submodels, a high threshold is usually used to filter out a large number of low-confidence predictions for unlabeled data. However, such filtering can not fully exploit unlabeled data with low prediction confidence. To overcome this problem, in this work, we propose a mutual learning framework based on pseudo-negative labels. Negative labels are those that a corresponding data item does not belong. In each iteration, one submodel generates pseudo-negative labels for each data item, and the other submodel learns from these labels. The role of the two submodels exchanges after each iteration until convergence. By reducing the prediction probability on pseudo-negative labels, the dual model can improve its prediction ability. We also propose a mechanism to select a few pseudo-negative labels to feed into submodels. In the experiments, our framework achieves state-of-the-art results on several main benchmarks. Specifically, with our framework, the error rates of the 13-layer CNN model are 9.35% and 7.94% for CIFAR-10 with 1000 and 4000 labels, respectively. In addition, for the non-augmented MNIST with only 20 labels, the error rate is 0.81% by our framework, which is much smaller than that of other approaches. Our approach also demonstrates a significant performance improvement in domain adaptation.
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
Dec 21, 2022



Large pretrained language models have shown surprising In-Context Learning (ICL) ability. With a few demonstration input-label pairs, they can predict the label for an unseen input without additional parameter updates. Despite the great success in performance, the working mechanism of ICL still remains an open problem. In order to better understand how ICL works, this paper explains language models as meta-optimizers and understands ICL as a kind of implicit finetuning. Theoretically, we figure out that the Transformer attention has a dual form of gradient descent based optimization. On top of it, we understand ICL as follows: GPT first produces meta-gradients according to the demonstration examples, and then these meta-gradients are applied to the original GPT to build an ICL model. Experimentally, we comprehensively compare the behavior of ICL and explicit finetuning based on real tasks to provide empirical evidence that supports our understanding. The results prove that ICL behaves similarly to explicit finetuning at the prediction level, the representation level, and the attention behavior level. Further, inspired by our understanding of meta-optimization, we design a momentum-based attention by analogy with the momentum-based gradient descent algorithm. Its consistently better performance over vanilla attention supports our understanding again from another aspect, and more importantly, it shows the potential to utilize our understanding for future model designing.
Language Models as Inductive Reasoners
Dec 21, 2022Inductive reasoning is a core component of human intelligence. In the past research of inductive reasoning within computer science, logic language is used as representations of knowledge (facts and rules, more specifically). However, logic language can cause systematic problems for inductive reasoning such as disability of handling raw input such as natural language, sensitiveness to mislabeled data, and incapacity to handle ambiguous input. To this end, we propose a new task, which is to induce natural language rules from natural language facts, and create a dataset termed DEER containing 1.2k rule-fact pairs for the task, where rules and facts are written in natural language. New automatic metrics are also proposed and analysed for the evaluation of this task. With DEER, we investigate a modern approach for inductive reasoning where we use natural language as representation for knowledge instead of logic language and use pretrained language models as ''reasoners''. Moreover, we provide the first and comprehensive analysis of how well pretrained language models can induce natural language rules from natural language facts. We also propose a new framework drawing insights from philosophy literature for this task, which we show in the experiment section that surpasses baselines in both automatic and human evaluations.
A Length-Extrapolatable Transformer
Dec 20, 2022Position modeling plays a critical role in Transformers. In this paper, we focus on length extrapolation, i.e., training on short texts while evaluating longer sequences. We define attention resolution as an indicator of extrapolation. Then we propose two designs to improve the above metric of Transformers. Specifically, we introduce a relative position embedding to explicitly maximize attention resolution. Moreover, we use blockwise causal attention during inference for better resolution. We evaluate different Transformer variants with language modeling. Experimental results show that our model achieves strong performance in both interpolation and extrapolation settings. The code will be available at https://aka.ms/LeX-Transformer.
GanLM: Encoder-Decoder Pre-training with an Auxiliary Discriminator
Dec 20, 2022



Pre-trained models have achieved remarkable success in natural language processing (NLP). However, existing pre-training methods underutilize the benefits of language understanding for generation. Inspired by the idea of Generative Adversarial Networks (GANs), we propose a GAN-style model for encoder-decoder pre-training by introducing an auxiliary discriminator, unifying the ability of language understanding and generation in a single model. Our model, named as GanLM, is trained with two pre-training objectives: replaced token detection and replaced token denoising. Specifically, given masked source sentences, the generator outputs the target distribution and the discriminator predicts whether the target sampled tokens from distribution are incorrect. The target sentence is replaced with misclassified tokens to construct noisy previous context, which is used to generate the gold sentence. In general, both tasks improve the ability of language understanding and generation by selectively using the denoising data. Extensive experiments in language generation benchmarks show that GanLM with the powerful language understanding capability outperforms various strong pre-trained language models (PLMs) and achieves state-of-the-art performance.