 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2Surf: Learning Parametric 3D Surface Models of Objects from Images
Aug 18, 2020
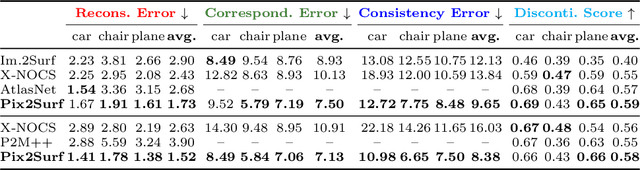
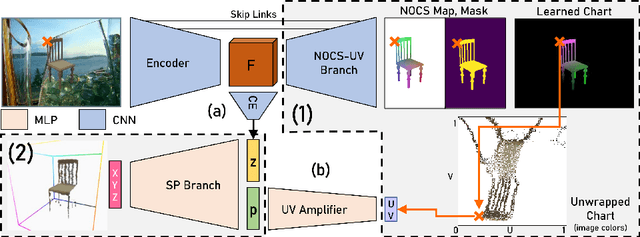
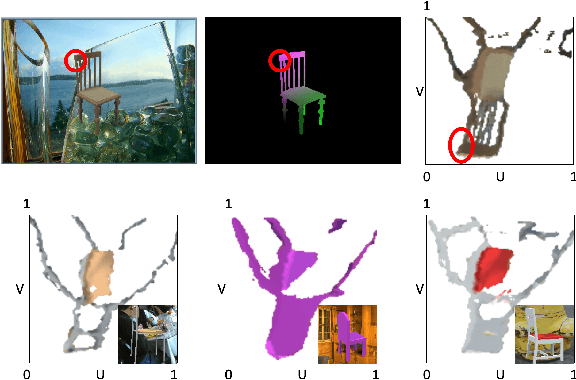
We investigate the problem of learning to generate 3D parametric surface representations for novel object instances, as seen from one or more views. Previous work on learning shape reconstruction from multiple views uses discrete representations such as point clouds or voxels, while continuous surface generation approaches lack multi-view consistency. We address these issues by designing neural networks capable of generating high-quality parametric 3D surfaces which are also consistent between views. Furthermore, the generated 3D surfaces preserve accurate image pixel to 3D surface point correspondences, allowing us to lift texture information to reconstruct shapes with rich geometry and appearance. Our method is supervised and trained on a public dataset of shapes from common object categories. Quantitative results indicate that our method significantly outperforms previous work, while qualitative results demonstrate the high quality of our reconstructions.
DSM-Net: Disentangled Structured Mesh Net for Controllable Generation of Fine Geometry
Aug 14, 2020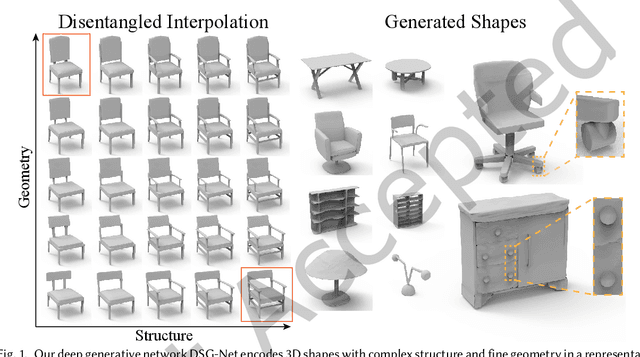
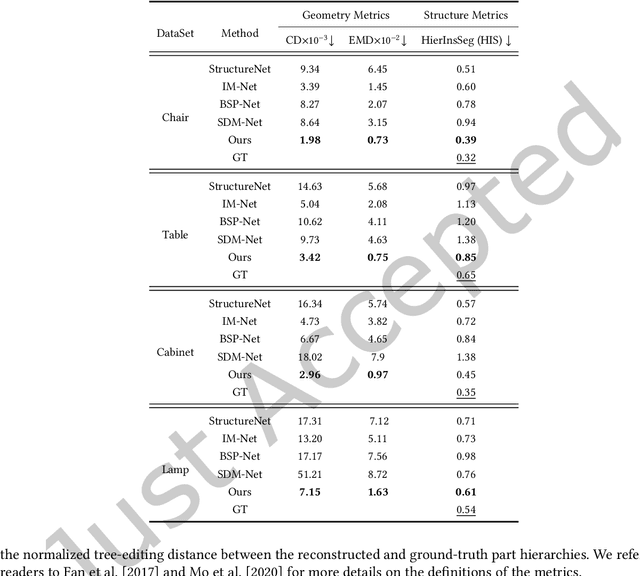
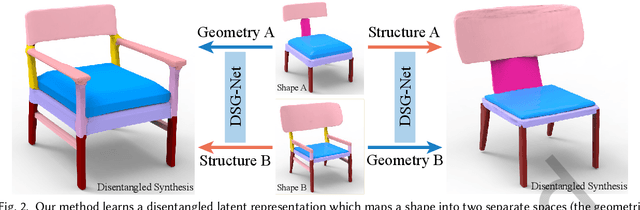
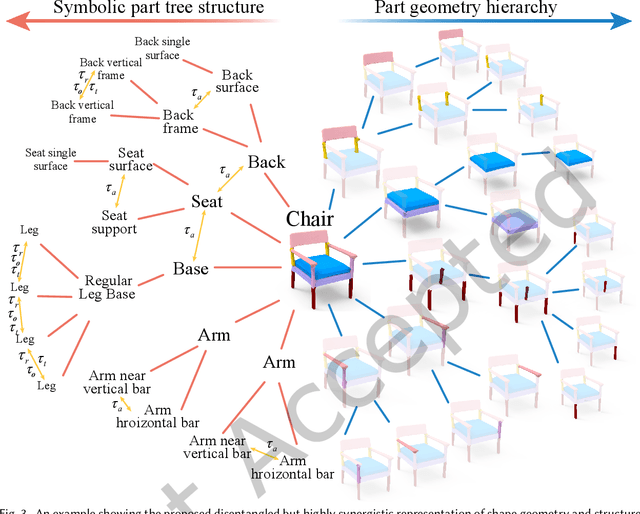
3D shape generation is a fundamental operation in computer graphics. While significant progress has been made, especially with recent deep generative models, it remains a challenge to synthesize high-quality geometric shapes with rich detail and complex structure, in a controllable manner. To tackle this, we introduce DSM-Net, a deep neural network that learns a disentangled structured mesh representation for 3D shapes, where two key aspects of shapes, geometry and structure, are encoded in a synergistic manner to ensure plausibility of the generated shapes, while also being disentangled as much as possible. This supports a range of novel shape generation applications with intuitive control, such as interpolation of structure (geometry) while keeping geometry (structure) unchanged. To achieve this, we simultaneously learn structure and geometry through variational autoencoders (VAEs) in a hierarchical manner for both, with bijective mappings at each level. In this manner we effectively encode geometry and structure in separate latent spaces, while ensuring their compatibility: the structure is used to guide the geometry and vice versa. At the leaf level, the part geometry is represented using a conditional part VAE, to encode high-quality geometric details, guided by the structure context as the condition. Our method not only supports controllable generation applications, but also produces high-quality synthesized shapes, outperforming state-of-the-art methods.
CaSPR: Learning Canonical Spatiotemporal Point Cloud Representations
Aug 06, 2020
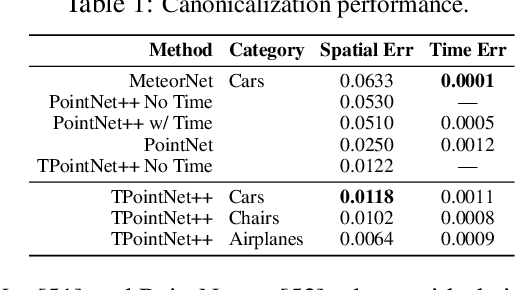
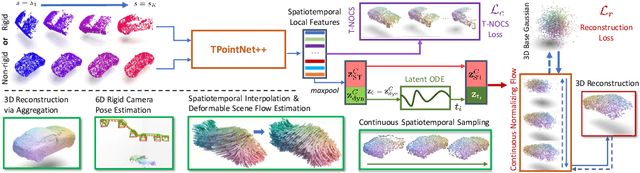

We propose CaSPR, a method to learn object-centric canonical spatiotemporal point cloud representations of dynamically moving or evolving objects. Our goal is to enable information aggregation over time and the interrogation of object state at any spatiotemporal neighborhood in the past, observed or not. Different from previous work, CaSPR learns representations that support spacetime continuity, are robust to variable and irregularly spacetime-sampled point clouds, and generalize to unseen object instances. Our approach divides the problem into two subtasks. First, we explicitly encode time by mapping an input point cloud sequence to a spatiotemporally-canonicalized object space. We then leverage this canonicalization to learn a spatiotemporal latent representation using neural ordinary differential equations and a generative model of dynamically evolving shapes using continuous normalizing flows. We demonstrate the effectiveness of our method on several applications including shape reconstruction, camera pose estimation, continuous spatiotemporal sequence reconstruction, and correspondence estimation from irregularly or intermittently sampled observations.
Contact and Human Dynamics from Monocular Video
Jul 24, 2020
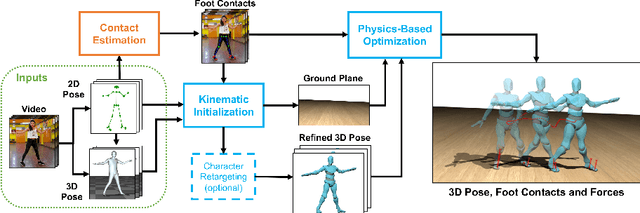

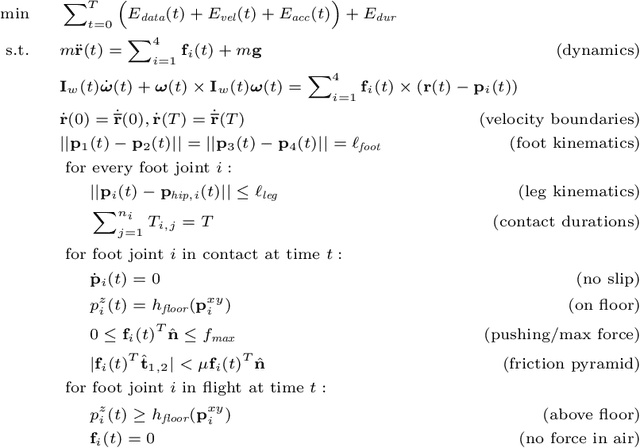
Existing deep models predict 2D and 3D kinematic poses from video that are approximately accurate, but contain visible errors that violate physical constraints, such as feet penetrating the ground and bodies leaning at extreme angles. In this paper, we present a physics-based method for inferring 3D human motion from video sequences that takes initial 2D and 3D pose estimates as input. We first estimate ground contact timings with a novel prediction network which is trained without hand-labeled data. A physics-based trajectory optimization then solves for a physically-plausible motion, based on the inputs. We show this process produces motions that are significantly more realistic than those from purely kinematic methods, substantially improving quantitative measures of both kinematic and dynamic plausibility. We demonstrate our method on character animation and pose estimation tasks on dynamic motions of dancing and sports with complex contact patterns.
PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding
Jul 22, 2020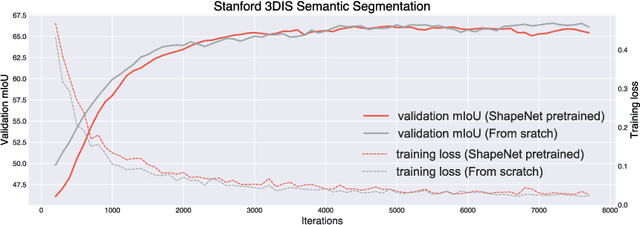
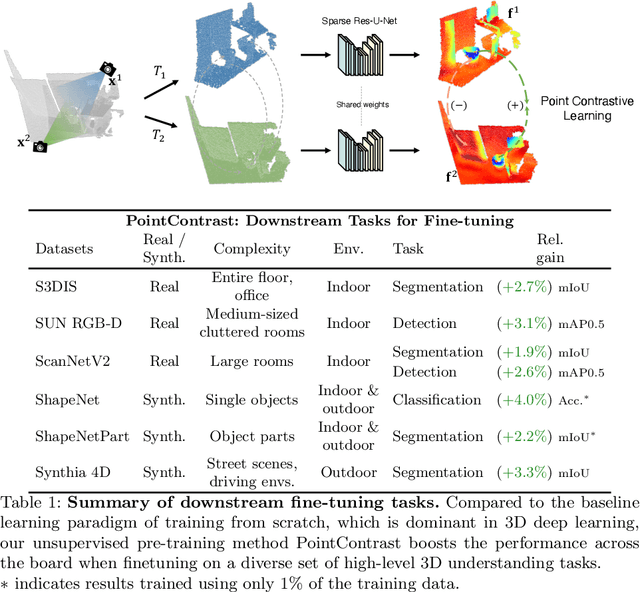
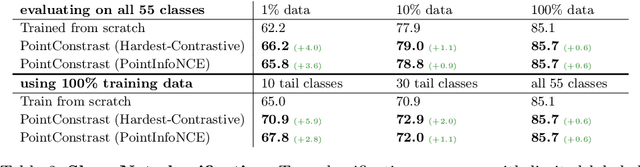
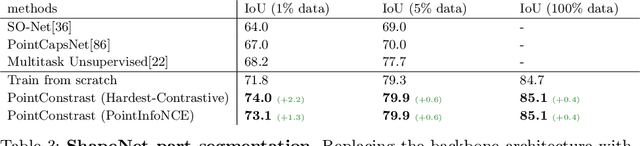
Arguably one of the top success stories of deep learning is transfer learning. The finding that pre-training a network on a rich source set (eg., ImageNet) can help boost performance once fine-tuned on a usually much smaller target set, has been instrumental to many applications in language and vision. Yet, very little is known about its usefulness in 3D point cloud understanding. We see this as an opportunity considering the effort required for annotating data in 3D. In this work, we aim at facilitating research on 3D representation learning. Different from previous works, we focus on high-level scene understanding tasks. To this end, we select a suite of diverse datasets and tasks to measure the effect of unsupervised pre-training on a large source set of 3D scenes. Our findings are extremely encouraging: using a unified triplet of architecture, source dataset, and contrastive loss for pre-training, we achieve improvement over recent best results in segmentation and detection across 6 different benchmarks for indoor and outdoor, real and synthetic datasets -- demonstrating that the learned representation can generalize across domains. Furthermore, the improvement was similar to supervised pre-training, suggesting that future efforts should favor scaling data collection over more detailed annotation. We hope these findings will encourage more research on unsupervised pretext task design for 3D deep learning.
Object-Centric Multi-View Aggregation
Jul 21, 2020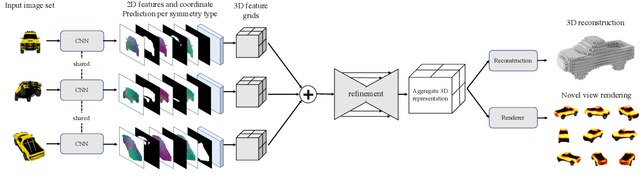



We present an approach for aggregating a sparse set of views of an object in order to compute a semi-implicit 3D representation in the form of a volumetric feature grid. Key to our approach is an object-centric canonical 3D coordinate system into which views can be lifted, without explicit camera pose estimation, and then combined -- in a manner that can accommodate a variable number of views and is view order independent. We show that computing a symmetry-aware mapping from pixels to the canonical coordinate system allows us to better propagate information to unseen regions, as well as to robustly overcome pose ambiguities during inference. Our aggregate representation enables us to perform 3D inference tasks like volumetric reconstruction and novel view synthesis, and we use these tasks to demonstrate the benefits of our aggregation approach as compared to implicit or camera-centric alternatives.
Rethinking Sampling in 3D Point Cloud Generative Adversarial Networks
Jun 12, 2020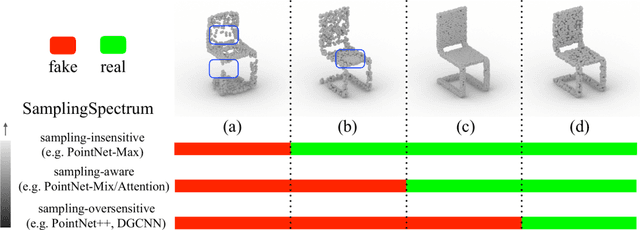


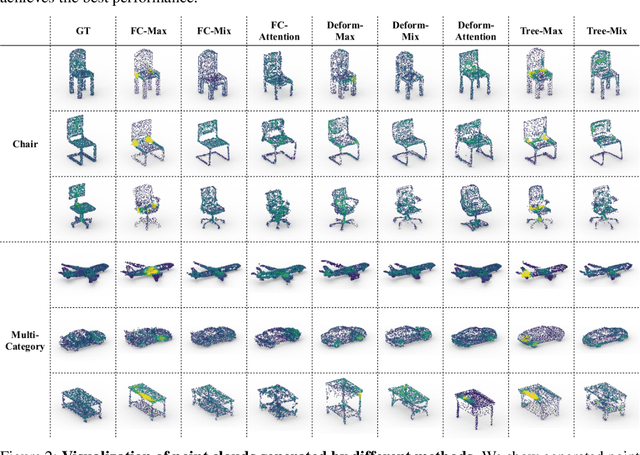
In this paper, we examine the long-neglected yet important effects of point sampling patterns in point cloud GANs. Through extensive experiments, we show that sampling-insensitive discriminators (e.g.PointNet-Max) produce shape point clouds with point clustering artifacts while sampling-oversensitive discriminators (e.g.PointNet++, DGCNN) fail to guide valid shape generation. We propose the concept of sampling spectrum to depict the different sampling sensitivities of discriminators. We further study how different evaluation metrics weigh the sampling pattern against the geometry and propose several perceptual metrics forming a sampling spectrum of metrics. Guided by the proposed sampling spectrum, we discover a middle-point sampling-aware baseline discriminator, PointNet-Mix, which improves all existing point cloud generators by a large margin on sampling-related metrics. We point out that, though recent research has been focused on the generator design, the main bottleneck of point cloud GAN actually lies in the discriminator design. Our work provides both suggestions and tools for building future discriminators. We will release the code to facilitate future research.
PT2PC: Learning to Generate 3D Point Cloud Shapes from Part Tree Conditions
Mar 19, 2020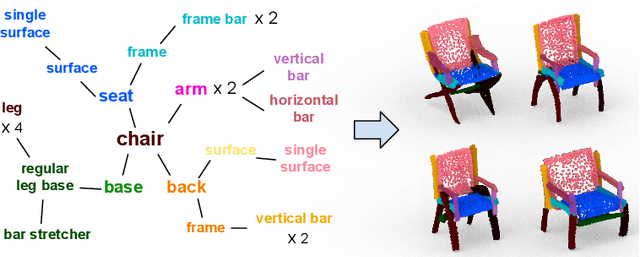
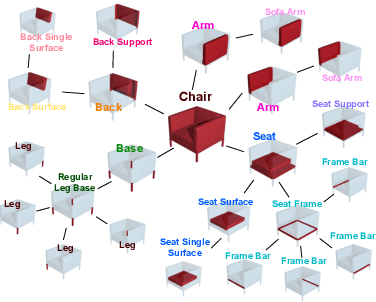
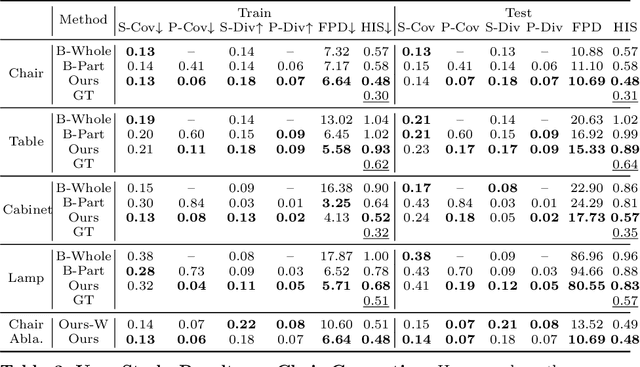
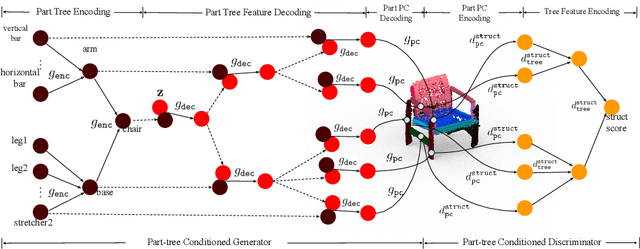
3D generative shape modeling is a fundamental research area in computer vision and interactive computer graphics, with many real-world applications. This paper investigates the novel problem of generating 3D shape point cloud geometry from a symbolic part tree representation. In order to learn such a conditional shape generation procedure in an end-to-end fashion, we propose a conditional GAN "part tree"-to-"point cloud" model (PT2PC) that disentangles the structural and geometric factors. The proposed model incorporates the part tree condition into the architecture design by passing messages top-down and bottom-up along the part tree hierarchy. Experimental results and user study demonstrate the strengths of our method in generating perceptually plausible and diverse 3D point clouds, given the part tree condition. We also propose a novel structural measure for evaluating if the generated shape point clouds satisfy the part tree conditions.
Curriculum DeepSDF
Mar 19, 2020
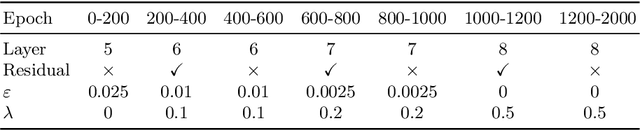
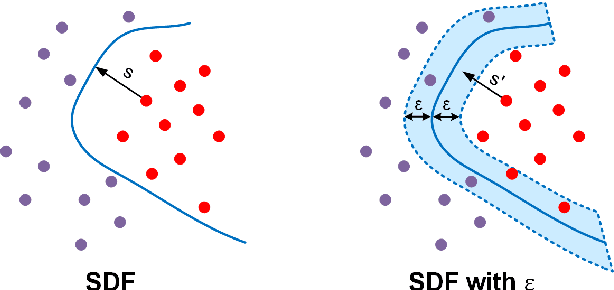
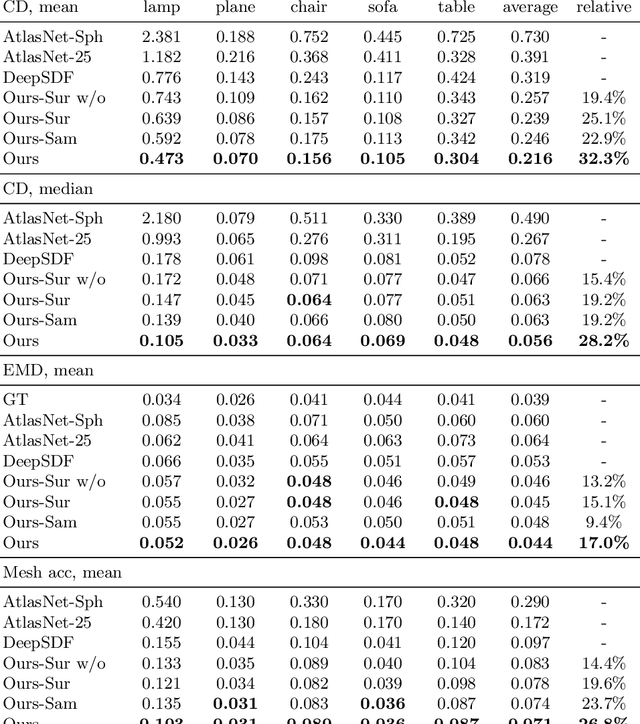
When learning to sketch, beginners start with simple and flexible shapes, and then gradually strive for more complex and accurate ones in the subsequent training sessions. In this paper, we design a "shape curriculum" for learning continuous Signed Distance Function (SDF) on shapes, namely Curriculum DeepSDF. Inspired by how humans learn, Curriculum DeepSDF organizes the learning task in ascending order of difficulty according to the following two criteria: surface accuracy and sample difficulty. The former considers stringency in supervising with ground truth, while the latter regards the weights of hard training samples near complex geometry and fine structure. More specifically, Curriculum DeepSDF learns to reconstruct coarse shapes at first, and then gradually increases the accuracy and focuses more on complex local details. Experimental results show that a carefully-designed curriculum leads to significantly better shape reconstructions with the same training data, training epochs and network architecture as DeepSDF. We believe that the application of shape curricula can benefit the training process of a wide variety of 3D shape representation learning methods.
SAPIEN: A SimulAted Part-based Interactive ENvironment
Mar 19, 2020


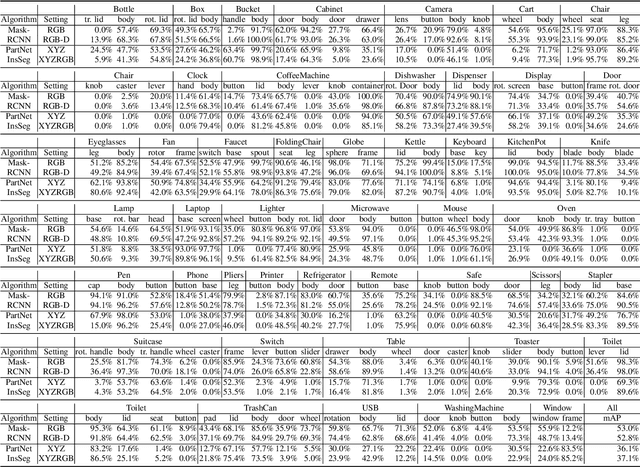
Building home assistant robots has long been a pursuit for vision and robotics researchers. To achieve this task, a simulated environment with physically realistic simulation, sufficient articulated objects, and transferability to the real robot is indispensable. Existing environments achieve these requirements for robotics simulation with different levels of simplification and focus. We take one step further in constructing an environment that supports household tasks for training robot learning algorithm. Our work, SAPIEN, is a realistic and physics-rich simulated environment that hosts a large-scale set for articulated objects. Our SAPIEN enables various robotic vision and interaction tasks that require detailed part-level understanding.We evaluate state-of-the-art vision algorithms for part detection and motion attribute recognition as well as demonstrate robotic interaction tasks using heuristic approaches and reinforcement learning algorithms. We hope that our SAPIEN can open a lot of research directions yet to be explored, including learning cognition through interaction, part motion discovery, and construction of robotics-ready simulated game environment.