 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymPoint Revolutionized: Boosting Panoptic Symbol Spotting with Layer Feature Enhancement
Jul 02, 2024SymPoint is an initial attempt that utilizes point set representation to solve the panoptic symbol spotting task on CAD drawing. Despite its considerable success, it overlooks graphical layer information and suffers from prohibitively slow training convergence. To tackle this issue, we introduce SymPoint-V2, a robust and efficient solution featuring novel, streamlined designs that overcome these limitations. In particular, we first propose a Layer Feature-Enhanced module (LFE) to encode the graphical layer information into the primitive feature, which significantly boosts the performance. We also design a Position-Guided Training (PGT) method to make it easier to learn, which accelerates the convergence of the model in the early stages and further promotes performance. Extensive experiments show that our model achieves better performance and faster convergence than its predecessor SymPoint on the public benchmark. Our code and trained models are available at https://github.com/nicehuster/SymPointV2.
YuLan: An Open-source Large Language Model
Jun 28, 2024



Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs
Jun 27, 2024
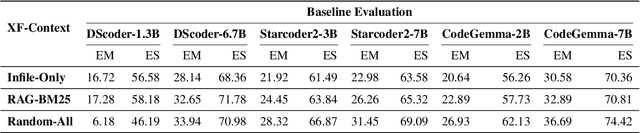
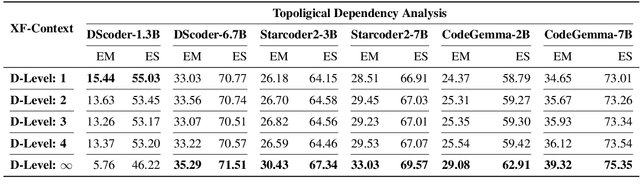
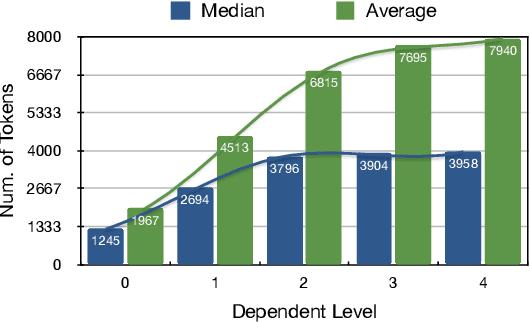
Some recently developed code large language models (Code LLMs) have been pre-trained on repository-level code data (Repo-Code LLMs), enabling these models to recognize repository structures and utilize cross-file information for code completion. However, in real-world development scenarios, simply concatenating the entire code repository often exceeds the context window limits of these Repo-Code LLMs, leading to significant performance degradation. In this study, we conducted extensive preliminary experiments and analyses on six Repo-Code LLMs. The results indicate that maintaining the topological dependencies of files and increasing the code file content in the completion prompts can improve completion accuracy; pruning the specific implementations of functions in all dependent files does not significantly reduce the accuracy of completions. Based on these findings, we proposed a strategy named Hierarchical Context Pruning (HCP) to construct completion prompts with high informational code content. The HCP models the code repository at the function level, maintaining the topological dependencies between code files while removing a large amount of irrelevant code content, significantly reduces the input length for repository-level code completion. We applied the HCP strategy in experiments with six Repo-Code LLMs, and the results demonstrate that our proposed method can significantly enhance completion accuracy while substantially reducing the length of input. Our code and data are available at https://github.com/Hambaobao/HCP-Coder.
Leave No Document Behind: Benchmarking Long-Context LLMs with Extended Multi-Doc QA
Jun 25, 2024



Long-context modeling capabilities have garnered widespread attention, leading to the emergence of Large Language Models (LLMs) with ultra-context windows. Meanwhile, benchmarks for evaluating long-context LLMs are gradually catching up. However, existing benchmarks employ irrelevant noise texts to artificially extend the length of test cases, diverging from the real-world scenarios of long-context applications. To bridge this gap, we propose a novel long-context benchmark, Loong, aligning with realistic scenarios through extended multi-document question answering (QA). Unlike typical document QA, in Loong's test cases, each document is relevant to the final answer, ignoring any document will lead to the failure of the answer. Furthermore, Loong introduces four types of tasks with a range of context lengths: Spotlight Locating, Comparison, Clustering, and Chain of Reasoning, to facilitate a more realistic and comprehensive evaluation of long-context understanding. Extensive experiments indicate that existing long-context language models still exhibit considerable potential for enhancement. Retrieval augmented generation (RAG) achieves poor performance, demonstrating that Loong can reliably assess the model's long-context modeling capabilities.
SyncNoise: Geometrically Consistent Noise Prediction for Text-based 3D Scene Editing
Jun 25, 2024Text-based 2D diffusion models have demonstrated impressive capabilities in image generation and editing. Meanwhile, the 2D diffusion models also exhibit substantial potentials for 3D editing tasks. However, how to achieve consistent edits across multiple viewpoints remains a challenge. While the iterative dataset update method is capable of achieving global consistency, it suffers from slow convergence and over-smoothed textures. We propose SyncNoise, a novel geometry-guided multi-view consistent noise editing approach for high-fidelity 3D scene editing. SyncNoise synchronously edits multiple views with 2D diffusion models while enforcing multi-view noise predictions to be geometrically consistent, which ensures global consistency in both semantic structure and low-frequency appearance. To further enhance local consistency in high-frequency details, we set a group of anchor views and propagate them to their neighboring frames through cross-view reprojection. To improve the reliability of multi-view correspondences, we introduce depth supervision during training to enhance the reconstruction of precise geometries. Our method achieves high-quality 3D editing results respecting the textual instructions, especially in scenes with complex textures, by enhancing geometric consistency at the noise and pixel levels.
CausalMMM: Learning Causal Structure for Marketing Mix Modeling
Jun 24, 2024In online advertising, marketing mix modeling (MMM) is employed to predict the gross merchandise volume (GMV) of brand shops and help decision-makers to adjust the budget allocation of various advertising channels. Traditional MMM methods leveraging regression techniques can fail in handling the complexity of marketing. Although some efforts try to encode the causal structures for better prediction, they have the strict restriction that causal structures are prior-known and unchangeable. In this paper, we define a new causal MMM problem that automatically discovers the interpretable causal structures from data and yields better GMV predictions. To achieve causal MMM, two essential challenges should be addressed: (1) Causal Heterogeneity. The causal structures of different kinds of shops vary a lot. (2) Marketing Response Patterns. Various marketing response patterns i.e., carryover effect and shape effect, have been validated in practice. We argue that causal MMM needs dynamically discover specific causal structures for different shops and the predictions should comply with the prior known marketing response patterns. Thus, we propose CausalMMM that integrates Granger causality in a variational inference framework to measure the causal relationships between different channels and predict the GMV with the regularization of both temporal and saturation marketing response patterns. Extensive experiments show that CausalMMM can not only achieve superior performance of causal structure learning on synthetic datasets with improvements of 5.7%\sim 7.1%, but also enhance the GMV prediction results on a representative E-commerce platform.
Soft Masked Mamba Diffusion Model for CT to MRI Conversion
Jun 22, 2024



Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) are the predominant modalities utilized in the field of medical imaging. Although MRI capture the complexity of anatomical structures with greater detail than CT, it entails a higher financial costs and requires longer image acquisition times. In this study, we aim to train latent diffusion model for CT to MRI conversion, replacing the commonly-used U-Net or Transformer backbone with a State-Space Model (SSM) called Mamba that operates on latent patches. First, we noted critical oversights in the scan scheme of most Mamba-based vision methods, including inadequate attention to the spatial continuity of patch tokens and the lack of consideration for their varying importance to the target task. Secondly, extending from this insight, we introduce Diffusion Mamba (DiffMa), employing soft masked to integrate Cross-Sequence Attention into Mamba and conducting selective scan in a spiral manner. Lastly, extensive experiments demonstrate impressive performance by DiffMa in medical image generation tasks, with notable advantages in input scaling efficiency over existing benchmark models. The code and models are available at https://github.com/wongzbb/DiffMa-Diffusion-Mamba
Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models
Jun 18, 2024Recently, large code generation models trained in a self-supervised manner on extensive unlabeled programming language data have achieved remarkable success. While these models acquire vast amounts of code knowledge, they perform poorly on code understanding tasks, such as code search and clone detection, as they are specifically trained for generation. Pre-training a larger encoder-only architecture model from scratch on massive code data can improve understanding performance. However, this approach is costly and time-consuming, making it suboptimal. In this paper, we pioneer the transfer of knowledge from pre-trained code generation models to code understanding tasks, significantly reducing training costs. We examine effective strategies for enabling decoder-only models to acquire robust code representations. Furthermore, we introduce CL4D, a contrastive learning method designed to enhance the representation capabilities of decoder-only models. Comprehensive experiments demonstrate that our approach achieves state-of-the-art performance in understanding tasks such as code search and clone detection. Our analysis shows that our method effectively reduces the distance between semantically identical samples in the representation space. These findings suggest the potential for unifying code understanding and generation tasks using a decoder-only structured model.
Voxel Mamba: Group-Free State Space Models for Point Cloud based 3D Object Detection
Jun 18, 2024



Serialization-based methods, which serialize the 3D voxels and group them into multiple sequences before inputting to Transformers, have demonstrated their effectiveness in 3D object detection. However, serializing 3D voxels into 1D sequences will inevitably sacrifice the voxel spatial proximity. Such an issue is hard to be addressed by enlarging the group size with existing serialization-based methods due to the quadratic complexity of Transformers with feature sizes. Inspired by the recent advances of state space models (SSMs), we present a Voxel SSM, termed as Voxel Mamba, which employs a group-free strategy to serialize the whole space of voxels into a single sequence. The linear complexity of SSMs encourages our group-free design, alleviating the loss of spatial proximity of voxels. To further enhance the spatial proximity, we propose a Dual-scale SSM Block to establish a hierarchical structure, enabling a larger receptive field in the 1D serialization curve, as well as more complete local regions in 3D space. Moreover, we implicitly apply window partition under the group-free framework by positional encoding, which further enhances spatial proximity by encoding voxel positional information. Our experiments on Waymo Open Dataset and nuScenes dataset show that Voxel Mamba not only achieves higher accuracy than state-of-the-art methods, but also demonstrates significant advantages in computational efficiency.
Integrating sensing and communications: Simultaneously transmitting and reflecting digital coding metasurfaces
Jun 16, 2024



Wireless networks are undergoing a transformative shift, driven by the crucial factors of cost effectiveness and sustainability. Digital coding metasurfaces (DCMs) might play a key role in realizing cost-effective digital modulators by harnessing energy embedded in electromagnetic waves traversing through the air. Integrated sensing and communication (ISAC) optimize power and spectral resources by combining sensing and communication functionalities on a shared hardware platform. This article presents a tutorial-style overview of the applications and advantages of DCMs in ISAC-based networks. Emphasis is placed on the dual-functionality of ISAC, necessitating the design of DCMs with simultaneously transmitting and reflecting (STAR) capabilities for comprehensive space control. Additionally, the article explores key signal processing challenges and outlines future research directions stemming from the convergence of ISAC and emerging STAR-DCM technologies.