 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthMaster: Unified Monocular Depth Estimation for Perspective and Panoramic Images
Jun 11, 2026While monocular depth estimation has achieved significant progress, achieving generalized metric depth estimation for both narrow field-of-view (FoV) perspectives and $360^\circ$ panoramas remains an unsolved challenge. Existing methods are often tailored to specific camera types and struggle to produce accurate metric depth that generalizes across diverse settings. This limitation stems from two key challenges: the inherent geometric discrepancy between perspective and panoramic cameras, and the scarcity of panoramic training data with metric annotations. In this work, we introduce DepthMaster, a unified metric depth estimation framework. Rather than employing specialized networks to learn spherical distortions, we reformulate the problem by decomposing panoramic images into overlapping perspective patches. Crucially, distinct from prior projection-based methods that rely on ad-hoc architectural modifications to handle boundaries, we introduce a novel Correspondence Consistency Loss (CCL) and inject virtual projection cameras as geometric priors, allowing us to seamlessly stitch the patches while avoiding specialized operators and keeping the backbone largely compatible with standard Transformer designs. This strategy also resolves the geometric differences by unifying all inputs into a canonical perspective representation, and effectively circumvents data scarcity by directly unlocking powerful metric priors from vast perspective datasets. Trained on a mixed dataset that contains only one panorama dataset, DepthMaster achieves state-of-the-art zero-shot performance on 13 diverse datasets, outperforming not only universal methods but also leading specialist models in both perspective and panoramic domains.
One2Scene: Geometric Consistent Explorable 3D Scene Generation from a Single Image
Feb 23, 2026Generating explorable 3D scenes from a single image is a highly challenging problem in 3D vision. Existing methods struggle to support free exploration, often producing severe geometric distortions and noisy artifacts when the viewpoint moves far from the original perspective. We introduce \textbf{One2Scene}, an effective framework that decomposes this ill-posed problem into three tractable sub-tasks to enable immersive explorable scene generation. We first use a panorama generator to produce anchor views from a single input image as initialization. Then, we lift these 2D anchors into an explicit 3D geometric scaffold via a generalizable, feed-forward Gaussian Splatting network. Instead of treating the panorama as a single image for reconstruction, we project it into multiple sparse anchor views and reformulate the reconstruction task as multi-view stereo matching, which allows us to leverage robust geometric priors learned from large-scale multi-view datasets. A bidirectional feature fusion module is used to enforce cross-view consistency, yielding an efficient and geometrically reliable scaffold. Finally, the scaffold serves as a strong prior for a novel view generator to produce photorealistic and geometrically accurate views at arbitrary cameras. By explicitly conditioning on a 3D-consistent scaffold to perform reconstruction, One2Scene works stably under large camera motions, supporting immersive scene exploration. Extensive experiments show that One2Scene substantially outperforms state-of-the-art methods in panorama depth estimation, feed-forward 360° reconstruction, and explorable 3D scene generation. Code and models will be released.
BadVLA: Towards Backdoor Attacks on Vision-Language-Action Models via Objective-Decoupled Optimization
May 22, 2025



Vision-Language-Action (VLA) models have advanced robotic control by enabling end-to-end decision-making directly from multimodal inputs. However, their tightly coupled architectures expose novel security vulnerabilities. Unlike traditional adversarial perturbations, backdoor attacks represent a stealthier, persistent, and practically significant threat-particularly under the emerging Training-as-a-Service paradigm-but remain largely unexplored in the context of VLA models. To address this gap, we propose BadVLA, a backdoor attack method based on Objective-Decoupled Optimization, which for the first time exposes the backdoor vulnerabilities of VLA models. Specifically, it consists of a two-stage process: (1) explicit feature-space separation to isolate trigger representations from benign inputs, and (2) conditional control deviations that activate only in the presence of the trigger, while preserving clean-task performance. Empirical results on multiple VLA benchmarks demonstrate that BadVLA consistently achieves near-100% attack success rates with minimal impact on clean task accuracy. Further analyses confirm its robustness against common input perturbations, task transfers, and model fine-tuning, underscoring critical security vulnerabilities in current VLA deployments. Our work offers the first systematic investigation of backdoor vulnerabilities in VLA models, highlighting an urgent need for secure and trustworthy embodied model design practices. We have released the project page at https://badvla-project.github.io/.
Large Reasoning Models in Agent Scenarios: Exploring the Necessity of Reasoning Capabilities
Mar 14, 2025The rise of Large Reasoning Models (LRMs) signifies a paradigm shift toward advanced computational reasoning. Yet, this progress disrupts traditional agent frameworks, traditionally anchored by execution-oriented Large Language Models (LLMs). To explore this transformation, we propose the LaRMA framework, encompassing nine tasks across Tool Usage, Plan Design, and Problem Solving, assessed with three top LLMs (e.g., Claude3.5-sonnet) and five leading LRMs (e.g., DeepSeek-R1). Our findings address four research questions: LRMs surpass LLMs in reasoning-intensive tasks like Plan Design, leveraging iterative reflection for superior outcomes; LLMs excel in execution-driven tasks such as Tool Usage, prioritizing efficiency; hybrid LLM-LRM configurations, pairing LLMs as actors with LRMs as reflectors, optimize agent performance by blending execution speed with reasoning depth; and LRMs' enhanced reasoning incurs higher computational costs, prolonged processing, and behavioral challenges, including overthinking and fact-ignoring tendencies. This study fosters deeper inquiry into LRMs' balance of deep thinking and overthinking, laying a critical foundation for future agent design advancements.
General Geometry-aware Weakly Supervised 3D Object Detection
Jul 18, 2024



3D object detection is an indispensable component for scene understanding. However, the annotation of large-scale 3D datasets requires significant human effort. To tackle this problem, many methods adopt weakly supervised 3D object detection that estimates 3D boxes by leveraging 2D boxes and scene/class-specific priors. However, these approaches generally depend on sophisticated manual priors, which is hard to generalize to novel categories and scenes. In this paper, we are motivated to propose a general approach, which can be easily adapted to new scenes and/or classes. A unified framework is developed for learning 3D object detectors from RGB images and associated 2D boxes. In specific, we propose three general components: prior injection module to obtain general object geometric priors from LLM model, 2D space projection constraint to minimize the discrepancy between the boundaries of projected 3D boxes and their corresponding 2D boxes on the image plane, and 3D space geometry constraint to build a Point-to-Box alignment loss to further refine the pose of estimated 3D boxes. Experiments on KITTI and SUN-RGBD datasets demonstrate that our method yields surprisingly high-quality 3D bounding boxes with only 2D annotation. The source code is available at https://github.com/gwenzhang/GGA.
Voxel Mamba: Group-Free State Space Models for Point Cloud based 3D Object Detection
Jun 18, 2024



Serialization-based methods, which serialize the 3D voxels and group them into multiple sequences before inputting to Transformers, have demonstrated their effectiveness in 3D object detection. However, serializing 3D voxels into 1D sequences will inevitably sacrifice the voxel spatial proximity. Such an issue is hard to be addressed by enlarging the group size with existing serialization-based methods due to the quadratic complexity of Transformers with feature sizes. Inspired by the recent advances of state space models (SSMs), we present a Voxel SSM, termed as Voxel Mamba, which employs a group-free strategy to serialize the whole space of voxels into a single sequence. The linear complexity of SSMs encourages our group-free design, alleviating the loss of spatial proximity of voxels. To further enhance the spatial proximity, we propose a Dual-scale SSM Block to establish a hierarchical structure, enabling a larger receptive field in the 1D serialization curve, as well as more complete local regions in 3D space. Moreover, we implicitly apply window partition under the group-free framework by positional encoding, which further enhances spatial proximity by encoding voxel positional information. Our experiments on Waymo Open Dataset and nuScenes dataset show that Voxel Mamba not only achieves higher accuracy than state-of-the-art methods, but also demonstrates significant advantages in computational efficiency.
OCDB: Revisiting Causal Discovery with a Comprehensive Benchmark and Evaluation Framework
Jun 07, 2024



Large language models (LLMs) have excelled in various natural language processing tasks, but challenges in interpretability and trustworthiness persist, limiting their use in high-stakes fields. Causal discovery offers a promising approach to improve transparency and reliability. However, current evaluations are often one-sided and lack assessments focused on interpretability performance. Additionally, these evaluations rely on synthetic data and lack comprehensive assessments of real-world datasets. These lead to promising methods potentially being overlooked. To address these issues, we propose a flexible evaluation framework with metrics for evaluating differences in causal structures and causal effects, which are crucial attributes that help improve the interpretability of LLMs. We introduce the Open Causal Discovery Benchmark (OCDB), based on real data, to promote fair comparisons and drive optimization of algorithms. Additionally, our new metrics account for undirected edges, enabling fair comparisons between Directed Acyclic Graphs (DAGs) and Completed Partially Directed Acyclic Graphs (CPDAGs). Experimental results show significant shortcomings in existing algorithms' generalization capabilities on real data, highlighting the potential for performance improvement and the importance of our framework in advancing causal discovery techniques.
ScatterFormer: Efficient Voxel Transformer with Scattered Linear Attention
Jan 01, 2024



Window-based transformers have demonstrated strong ability in large-scale point cloud understanding by capturing context-aware representations with affordable attention computation in a more localized manner. However, because of the sparse nature of point clouds, the number of voxels per window varies significantly. Current methods partition the voxels in each window into multiple subsets of equal size, which cost expensive overhead in sorting and padding the voxels, making them run slower than sparse convolution based methods. In this paper, we present ScatterFormer, which, for the first time to our best knowledge, could directly perform attention on voxel sets with variable length. The key of ScatterFormer lies in the innovative Scatter Linear Attention (SLA) module, which leverages the linear attention mechanism to process in parallel all voxels scattered in different windows. Harnessing the hierarchical computation units of the GPU and matrix blocking algorithm, we reduce the latency of the proposed SLA module to less than 1 ms on moderate GPUs. Besides, we develop a cross-window interaction module to simultaneously enhance the local representation and allow the information flow across windows, eliminating the need for window shifting. Our proposed ScatterFormer demonstrates 73 mAP (L2) on the large-scale Waymo Open Dataset and 70.5 NDS on the NuScenes dataset, running at an outstanding detection rate of 28 FPS. Code is available at https://github.com/skyhehe123/ScatterFormer
HAT: Hierarchical Aggregation Transformers for Person Re-identification
Jul 14, 2021
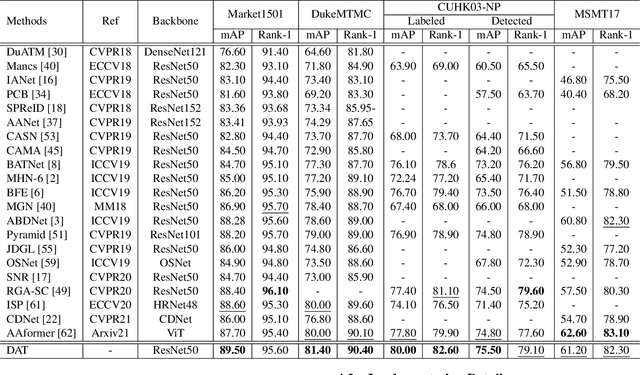
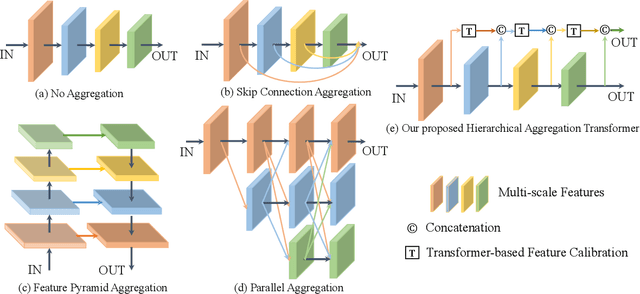
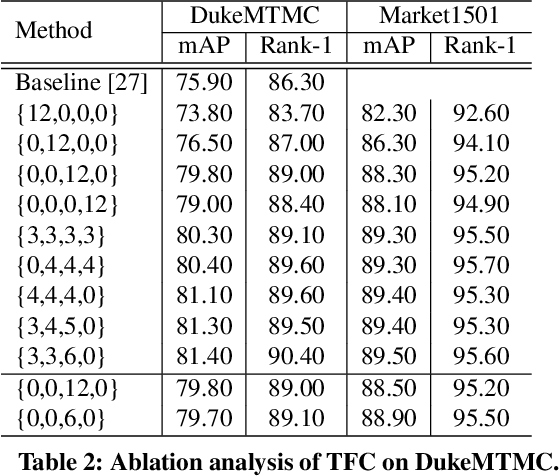
Recently, with the advance of deep Convolutional Neural Networks (CNNs), person Re-Identification (Re-ID) has witnessed great success in various applications. However, with limited receptive fields of CNNs, it is still challenging to extract discriminative representations in a global view for persons under non-overlapped cameras. Meanwhile, Transformers demonstrate strong abilities of modeling long-range dependencies for spatial and sequential data. In this work, we take advantages of both CNNs and Transformers, and propose a novel learning framework named Hierarchical Aggregation Transformer (HAT) for image-based person Re-ID with high performance. To achieve this goal, we first propose a Deeply Supervised Aggregation (DSA) to recurrently aggregate hierarchical features from CNN backbones. With multi-granularity supervisions, the DSA can enhance multi-scale features for person retrieval, which is very different from previous methods. Then, we introduce a Transformer-based Feature Calibration (TFC) to integrate low-level detail information as the global prior for high-level semantic information. The proposed TFC is inserted to each level of hierarchical features, resulting in great performance improvements. To our best knowledge, this work is the first to take advantages of both CNNs and Transformers for image-based person Re-ID. Comprehensive experiments on four large-scale Re-ID benchmarks demonstrate that our method shows better results than several state-of-the-art methods. The code is released at https://github.com/AI-Zhpp/HAT.