 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025



Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
D$^2$iT: Dynamic Diffusion Transformer for Accurate Image Generation
Apr 13, 2025

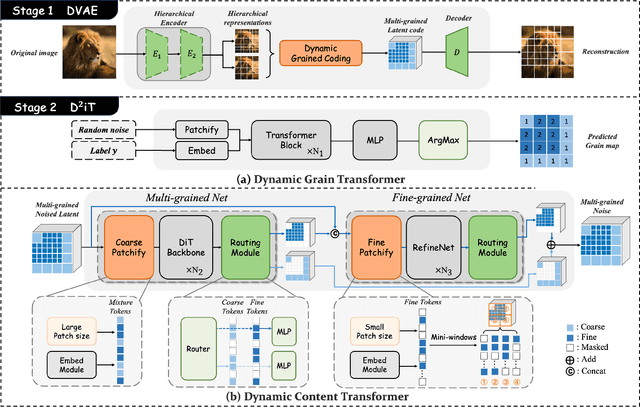

Diffusion models are widely recognized for their ability to generate high-fidelity images. Despite the excellent performance and scalability of the Diffusion Transformer (DiT) architecture, it applies fixed compression across different image regions during the diffusion process, disregarding the naturally varying information densities present in these regions. However, large compression leads to limited local realism, while small compression increases computational complexity and compromises global consistency, ultimately impacting the quality of generated images. To address these limitations, we propose dynamically compressing different image regions by recognizing the importance of different regions, and introduce a novel two-stage framework designed to enhance the effectiveness and efficiency of image generation: (1) Dynamic VAE (DVAE) at first stage employs a hierarchical encoder to encode different image regions at different downsampling rates, tailored to their specific information densities, thereby providing more accurate and natural latent codes for the diffusion process. (2) Dynamic Diffusion Transformer (D$^2$iT) at second stage generates images by predicting multi-grained noise, consisting of coarse-grained (less latent code in smooth regions) and fine-grained (more latent codes in detailed regions), through an novel combination of the Dynamic Grain Transformer and the Dynamic Content Transformer. The strategy of combining rough prediction of noise with detailed regions correction achieves a unification of global consistency and local realism. Comprehensive experiments on various generation tasks validate the effectiveness of our approach. Code will be released at https://github.com/jiawn-creator/Dynamic-DiT.
1-Tb/s/λ Transmission over Record 10714-km AR-HCF
Apr 02, 2025We present the first single-channel 1.001-Tb/s DP-36QAM-PCS recirculating transmission over 73 loops of 146.77-km ultra-low-loss & low-IMI DNANF-5 fiber, achieving a record transmission distance of 10,714.28 km.
PLM4NDV: Minimizing Data Access for Number of Distinct Values Estimation with Pre-trained Language Models
Apr 01, 2025



Number of Distinct Values (NDV) estimation of a multiset/column is a basis for many data management tasks, especially within databases. Despite decades of research, most existing methods require either a significant amount of samples through uniform random sampling or access to the entire column to produce estimates, leading to substantial data access costs and potentially ineffective estimations in scenarios with limited data access. In this paper, we propose leveraging semantic information, i.e., schema, to address these challenges. The schema contains rich semantic information that can benefit the NDV estimation. To this end, we propose PLM4NDV, a learned method incorporating Pre-trained Language Models (PLMs) to extract semantic schema information for NDV estimation. Specifically, PLM4NDV leverages the semantics of the target column and the corresponding table to gain a comprehensive understanding of the column's meaning. By using the semantics, PLM4NDV reduces data access costs, provides accurate NDV estimation, and can even operate effectively without any data access. Extensive experiments on a large-scale real-world dataset demonstrate the superiority of PLM4NDV over baseline methods. Our code is available at https://github.com/bytedance/plm4ndv.
Coca-Splat: Collaborative Optimization for Camera Parameters and 3D Gaussians
Apr 01, 2025In this work, we introduce Coca-Splat, a novel approach to addressing the challenges of sparse view pose-free scene reconstruction and novel view synthesis (NVS) by jointly optimizing camera parameters with 3D Gaussians. Inspired by deformable DEtection TRansformer, we design separate queries for 3D Gaussians and camera parameters and update them layer by layer through deformable Transformer layers, enabling joint optimization in a single network. This design demonstrates better performance because to accurately render views that closely approximate ground-truth images relies on precise estimation of both 3D Gaussians and camera parameters. In such a design, the centers of 3D Gaussians are projected onto each view by camera parameters to get projected points, which are regarded as 2D reference points in deformable cross-attention. With camera-aware multi-view deformable cross-attention (CaMDFA), 3D Gaussians and camera parameters are intrinsically connected by sharing the 2D reference points. Additionally, 2D reference point determined rays (RayRef) defined from camera centers to the reference points assist in modeling relationship between 3D Gaussians and camera parameters through RQ-decomposition on an overdetermined system of equations derived from the rays, enhancing the relationship between 3D Gaussians and camera parameters. Extensive evaluation shows that our approach outperforms previous methods, both pose-required and pose-free, on RealEstate10K and ACID within the same pose-free setting.
An Explainable Neural Radiomic Sequence Model with Spatiotemporal Continuity for Quantifying 4DCT-based Pulmonary Ventilation
Mar 31, 2025Accurate evaluation of regional lung ventilation is essential for the management and treatment of lung cancer patients, supporting assessments of pulmonary function, optimization of therapeutic strategies, and monitoring of treatment response. Currently, ventilation scintigraphy using nuclear medicine techniques is widely employed in clinical practice; however, it is often time-consuming, costly, and entails additional radiation exposure. In this study, we propose an explainable neural radiomic sequence model to identify regions of compromised pulmonary ventilation based on four-dimensional computed tomography (4DCT). A cohort of 45 lung cancer patients from the VAMPIRE dataset was analyzed. For each patient, lung volumes were segmented from 4DCT, and voxel-wise radiomic features (56-dimensional) were extracted across the respiratory cycle to capture local intensity and texture dynamics, forming temporal radiomic sequences. Ground truth ventilation defects were delineated voxel-wise using Galligas-PET and DTPA-SPECT. To identify compromised regions, we developed a temporal saliency-enhanced explainable long short-term memory (LSTM) network trained on the radiomic sequences. Temporal saliency maps were generated to highlight key features contributing to the model's predictions. The proposed model demonstrated robust performance, achieving average (range) Dice similarity coefficients of 0.78 (0.74-0.79) for 25 PET cases and 0.78 (0.74-0.82) for 20 SPECT cases. The temporal saliency map explained three key radiomic sequences in ventilation quantification: during lung exhalation, compromised pulmonary function region typically exhibits (1) an increasing trend of intensity and (2) a decreasing trend of homogeneity, in contrast to healthy lung tissue.
InstructRestore: Region-Customized Image Restoration with Human Instructions
Mar 31, 2025



Despite the significant progress in diffusion prior-based image restoration, most existing methods apply uniform processing to the entire image, lacking the capability to perform region-customized image restoration according to user instructions. In this work, we propose a new framework, namely InstructRestore, to perform region-adjustable image restoration following human instructions. To achieve this, we first develop a data generation engine to produce training triplets, each consisting of a high-quality image, the target region description, and the corresponding region mask. With this engine and careful data screening, we construct a comprehensive dataset comprising 536,945 triplets to support the training and evaluation of this task. We then examine how to integrate the low-quality image features under the ControlNet architecture to adjust the degree of image details enhancement. Consequently, we develop a ControlNet-like model to identify the target region and allocate different integration scales to the target and surrounding regions, enabling region-customized image restoration that aligns with user instructions. Experimental results demonstrate that our proposed InstructRestore approach enables effective human-instructed image restoration, such as images with bokeh effects and user-instructed local enhancement. Our work advances the investigation of interactive image restoration and enhancement techniques. Data, code, and models will be found at https://github.com/shuaizhengliu/InstructRestore.git.
Progressive Rendering Distillation: Adapting Stable Diffusion for Instant Text-to-Mesh Generation without 3D Data
Mar 27, 2025



It is highly desirable to obtain a model that can generate high-quality 3D meshes from text prompts in just seconds. While recent attempts have adapted pre-trained text-to-image diffusion models, such as Stable Diffusion (SD), into generators of 3D representations (e.g., Triplane), they often suffer from poor quality due to the lack of sufficient high-quality 3D training data. Aiming at overcoming the data shortage, we propose a novel training scheme, termed as Progressive Rendering Distillation (PRD), eliminating the need for 3D ground-truths by distilling multi-view diffusion models and adapting SD into a native 3D generator. In each iteration of training, PRD uses the U-Net to progressively denoise the latent from random noise for a few steps, and in each step it decodes the denoised latent into 3D output. Multi-view diffusion models, including MVDream and RichDreamer, are used in joint with SD to distill text-consistent textures and geometries into the 3D outputs through score distillation. Since PRD supports training without 3D ground-truths, we can easily scale up the training data and improve generation quality for challenging text prompts with creative concepts. Meanwhile, PRD can accelerate the inference speed of the generation model in just a few steps. With PRD, we train a Triplane generator, namely TriplaneTurbo, which adds only $2.5\%$ trainable parameters to adapt SD for Triplane generation. TriplaneTurbo outperforms previous text-to-3D generators in both efficiency and quality. Specifically, it can produce high-quality 3D meshes in 1.2 seconds and generalize well for challenging text input. The code is available at https://github.com/theEricMa/TriplaneTurbo.
UGNA-VPR: A Novel Training Paradigm for Visual Place Recognition Based on Uncertainty-Guided NeRF Augmentation
Mar 27, 2025



Visual place recognition (VPR) is crucial for robots to identify previously visited locations, playing an important role in autonomous navigation in both indoor and outdoor environments. However, most existing VPR datasets are limited to single-viewpoint scenarios, leading to reduced recognition accuracy, particularly in multi-directional driving or feature-sparse scenes. Moreover, obtaining additional data to mitigate these limitations is often expensive. This paper introduces a novel training paradigm to improve the performance of existing VPR networks by enhancing multi-view diversity within current datasets through uncertainty estimation and NeRF-based data augmentation. Specifically, we initially train NeRF using the existing VPR dataset. Then, our devised self-supervised uncertainty estimation network identifies places with high uncertainty. The poses of these uncertain places are input into NeRF to generate new synthetic observations for further training of VPR networks. Additionally, we propose an improved storage method for efficient organization of augmented and original training data. We conducted extensive experiments on three datasets and tested three different VPR backbone networks. The results demonstrate that our proposed training paradigm significantly improves VPR performance by fully utilizing existing data, outperforming other training approaches. We further validated the effectiveness of our approach on self-recorded indoor and outdoor datasets, consistently demonstrating superior results. Our dataset and code have been released at \href{https://github.com/nubot-nudt/UGNA-VPR}{https://github.com/nubot-nudt/UGNA-VPR}.
InsViE-1M: Effective Instruction-based Video Editing with Elaborate Dataset Construction
Mar 26, 2025



Instruction-based video editing allows effective and interactive editing of videos using only instructions without extra inputs such as masks or attributes. However, collecting high-quality training triplets (source video, edited video, instruction) is a challenging task. Existing datasets mostly consist of low-resolution, short duration, and limited amount of source videos with unsatisfactory editing quality, limiting the performance of trained editing models. In this work, we present a high-quality Instruction-based Video Editing dataset with 1M triplets, namely InsViE-1M. We first curate high-resolution and high-quality source videos and images, then design an effective editing-filtering pipeline to construct high-quality editing triplets for model training. For a source video, we generate multiple edited samples of its first frame with different intensities of classifier-free guidance, which are automatically filtered by GPT-4o with carefully crafted guidelines. The edited first frame is propagated to subsequent frames to produce the edited video, followed by another round of filtering for frame quality and motion evaluation. We also generate and filter a variety of video editing triplets from high-quality images. With the InsViE-1M dataset, we propose a multi-stage learning strategy to train our InsViE model, progressively enhancing its instruction following and editing ability. Extensive experiments demonstrate the advantages of our InsViE-1M dataset and the trained model over state-of-the-art works. Codes are available at InsViE.