 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
May 05, 2026Distillation-based acceleration has become foundational for making autoregressive streaming video diffusion models practical, with distribution matching distillation (DMD) as the de facto choice. Existing methods, however, train the student to match the teacher's output indiscriminately, treating every rollout, frame, and pixel as equally reliable supervision. We argue that this caps distilled quality, since it overlooks two complementary axes of variance in DMD supervision: Inter-Reliability across student rollouts whose supervision varies in reliability, and Intra-Perplexity across spatial regions and temporal frames that contribute unequally to where quality can still be improved. The objective thus conflates two questions under a uniform weight: whether to learn from each rollout, and where to concentrate optimization within it. To address this, we propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that adaptively reweights the distillation objective at both rollout and spatiotemporal-element levels through a single shared reward-guided mechanism. At the Inter-Reliability level, Stream-R1 rescales each rollout's loss by an exponential of a pretrained video reward score, so that rollouts with reliable supervision dominate optimization. At the Intra-Perplexity level, it back-propagates the same reward model to extract per-pixel gradient saliency, which is factored into spatial and temporal weights that concentrate optimization pressure on regions and frames where refinement yields the largest expected gain. An adaptive balancing mechanism prevents any single quality axis from dominating across visual quality, motion quality, and text alignment. Stream-R1 attains consistent improvements on all three dimensions over distillation baselines on standard streaming video generation benchmarks, without architectural modification or additional inference cost.
Rethinking Position Embedding as a Context Controller for Multi-Reference and Multi-Shot Video Generation
Apr 04, 2026Recent proprietary models such as Sora2 demonstrate promising progress in generating multi-shot videos conditioned on multiple reference characters. However, academic research on this problem remains limited. We study this task and identify a core challenge: when reference images exhibit highly similar appearances, the model often suffers from reference confusion, where semantically similar tokens degrade the model's ability to retrieve the correct context. To address this, we introduce PoCo (Position Embedding as a Context Controller), which incorporates position encoding as additional context control beyond semantic retrieval. By employing side information of tokens, PoCo enables precise token-level matching while preserving implicit semantic consistency modeling. Building on PoCo, we develop a multi-reference and multi-shot video generation model capable of reliably controlling characters with extremely similar visual traits. Extensive experiments demonstrate that PoCo improves cross-shot consistency and reference fidelity compared with various baselines.
NativeTok: Native Visual Tokenization for Improved Image Generation
Jan 30, 2026VQ-based image generation typically follows a two-stage pipeline: a tokenizer encodes images into discrete tokens, and a generative model learns their dependencies for reconstruction. However, improved tokenization in the first stage does not necessarily enhance the second-stage generation, as existing methods fail to constrain token dependencies. This mismatch forces the generative model to learn from unordered distributions, leading to bias and weak coherence. To address this, we propose native visual tokenization, which enforces causal dependencies during tokenization. Building on this idea, we introduce NativeTok, a framework that achieves efficient reconstruction while embedding relational constraints within token sequences. NativeTok consists of: (1) a Meta Image Transformer (MIT) for latent image modeling, and (2) a Mixture of Causal Expert Transformer (MoCET), where each lightweight expert block generates a single token conditioned on prior tokens and latent features. We further design a Hierarchical Native Training strategy that updates only new expert blocks, ensuring training efficiency. Extensive experiments demonstrate the effectiveness of NativeTok.
D$^2$iT: Dynamic Diffusion Transformer for Accurate Image Generation
Apr 13, 2025

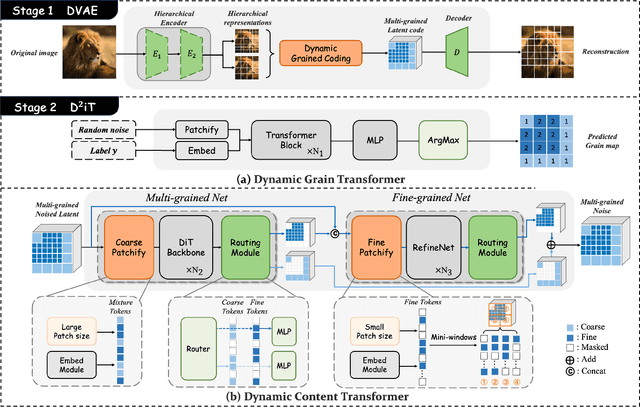

Diffusion models are widely recognized for their ability to generate high-fidelity images. Despite the excellent performance and scalability of the Diffusion Transformer (DiT) architecture, it applies fixed compression across different image regions during the diffusion process, disregarding the naturally varying information densities present in these regions. However, large compression leads to limited local realism, while small compression increases computational complexity and compromises global consistency, ultimately impacting the quality of generated images. To address these limitations, we propose dynamically compressing different image regions by recognizing the importance of different regions, and introduce a novel two-stage framework designed to enhance the effectiveness and efficiency of image generation: (1) Dynamic VAE (DVAE) at first stage employs a hierarchical encoder to encode different image regions at different downsampling rates, tailored to their specific information densities, thereby providing more accurate and natural latent codes for the diffusion process. (2) Dynamic Diffusion Transformer (D$^2$iT) at second stage generates images by predicting multi-grained noise, consisting of coarse-grained (less latent code in smooth regions) and fine-grained (more latent codes in detailed regions), through an novel combination of the Dynamic Grain Transformer and the Dynamic Content Transformer. The strategy of combining rough prediction of noise with detailed regions correction achieves a unification of global consistency and local realism. Comprehensive experiments on various generation tasks validate the effectiveness of our approach. Code will be released at https://github.com/jiawn-creator/Dynamic-DiT.