 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised High Dynamic Range Imaging with Multi-Exposure Images in Dynamic Scenes
Oct 03, 2023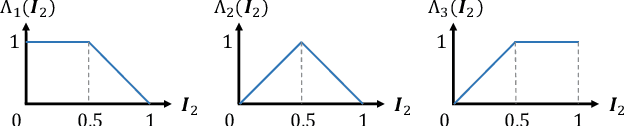
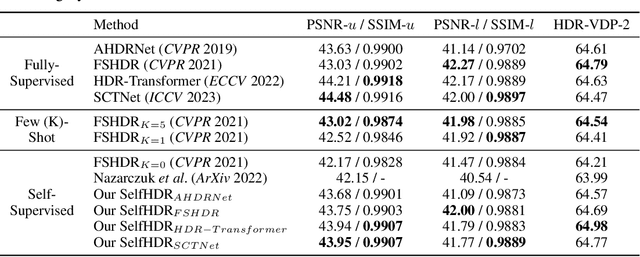
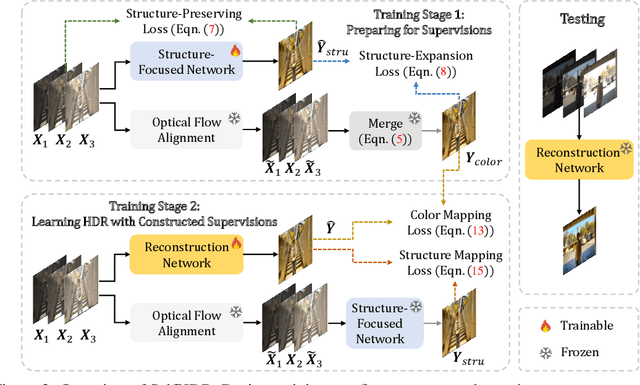

Merging multi-exposure images is a common approach for obtaining high dynamic range (HDR) images, with the primary challenge being the avoidance of ghosting artifacts in dynamic scenes. Recent methods have proposed using deep neural networks for deghosting. However, the methods typically rely on sufficient data with HDR ground-truths, which are difficult and costly to collect. In this work, to eliminate the need for labeled data, we propose SelfHDR, a self-supervised HDR reconstruction method that only requires dynamic multi-exposure images during training. Specifically, SelfHDR learns a reconstruction network under the supervision of two complementary components, which can be constructed from multi-exposure images and focus on HDR color as well as structure, respectively. The color component is estimated from aligned multi-exposure images, while the structure one is generated through a structure-focused network that is supervised by the color component and an input reference (\eg, medium-exposure) image. During testing, the learned reconstruction network is directly deployed to predict an HDR image. Experiments on real-world images demonstrate our SelfHDR achieves superior results against the state-of-the-art self-supervised methods, and comparable performance to supervised ones. Codes are available at https://github.com/cszhilu1998/SelfHDR
Implicit Sensing in Traffic Optimization: Advanced Deep Reinforcement Learning Techniques
Sep 25, 2023



A sudden roadblock on highways due to many reasons such as road maintenance, accidents, and car repair is a common situation we encounter almost daily. Autonomous Vehicles (AVs) equipped with sensors that can acquire vehicle dynamics such as speed, acceleration, and location can make intelligent decisions to change lanes before reaching a roadblock. A number of literature studies have examined car-following models and lane-changing models. However, only a few studies proposed an integrated car-following and lane-changing model, which has the potential to model practical driving maneuvers. Hence, in this paper, we present an integrated car-following and lane-changing decision-control system based on Deep Reinforcement Learning (DRL) to address this issue. Specifically, we consider a scenario where sudden construction work will be carried out along a highway. We model the scenario as a Markov Decision Process (MDP) and employ the well-known DQN algorithm to train the RL agent to make the appropriate decision accordingly (i.e., either stay in the same lane or change lanes). To overcome the delay and computational requirement of DRL algorithms, we adopt an MEC-assisted architecture where the RL agents are trained on MEC servers. We utilize the highly reputable SUMO simulator and OPENAI GYM to evaluate the performance of the proposed model under two policies; {\epsilon}-greedy policy and Boltzmann policy. The results unequivocally demonstrate that the DQN agent trained using the {\epsilon}-greedy policy significantly outperforms the one trained with the Boltzmann policy.
Beyond Image Borders: Learning Feature Extrapolation for Unbounded Image Composition
Sep 21, 2023For improving image composition and aesthetic quality, most existing methods modulate the captured images by striking out redundant content near the image borders. However, such image cropping methods are limited in the range of image views. Some methods have been suggested to extrapolate the images and predict cropping boxes from the extrapolated image. Nonetheless, the synthesized extrapolated regions may be included in the cropped image, making the image composition result not real and potentially with degraded image quality. In this paper, we circumvent this issue by presenting a joint framework for both unbounded recommendation of camera view and image composition (i.e., UNIC). In this way, the cropped image is a sub-image of the image acquired by the predicted camera view, and thus can be guaranteed to be real and consistent in image quality. Specifically, our framework takes the current camera preview frame as input and provides a recommendation for view adjustment, which contains operations unlimited by the image borders, such as zooming in or out and camera movement. To improve the prediction accuracy of view adjustment prediction, we further extend the field of view by feature extrapolation. After one or several times of view adjustments, our method converges and results in both a camera view and a bounding box showing the image composition recommendation. Extensive experiments are conducted on the datasets constructed upon existing image cropping datasets, showing the effectiveness of our UNIC in unbounded recommendation of camera view and image composition. The source code, dataset, and pretrained models is available at https://github.com/liuxiaoyu1104/UNIC.
Symbol-Level Precoding for MU-MIMO System with RIRC Receiver
Jul 27, 2023



Consider a multiuser multiple-input multiple-output (MU-MIMO) downlink system in which the base station (BS) sends multiple data streams to multi-antenna users via symbol-level precoding (SLP), where the optimization of receive combining matrix becomes crucial, unlike in the single-antenna user scenario. We begin by introducing a joint optimization problem on the symbol-level transmit precoder and receive combiner. The problem is solved using the alternating optimization (AO) method, and the optimal solution structures for transmit precoding and receive combining matrices are derived by using Lagrangian and Karush-Kuhn-Tucker (KKT) conditions, based on which, the original problem is transformed into an equivalent quadratic programming problem, enabling more efficient solutions. To address the challenge that the above joint design is difficult to implement, we propose a more practical scheme where the receive combining optimization is replaced by the interference rejection combiner (IRC), which is however difficult to directly use because of the rank-one transmit precoding matrix. Therefore, we introduce a new regularized IRC (RIRC) receiver to circumvent the above issue. Numerical results demonstrate that the practical SLP-RIRC method enjoys only a slight communication performance loss compared to the joint transmit precoding and receive combining design, both offering substantial performance gains over the conventional BD-based approaches.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Self-supervised Learning to Bring Dual Reversed Rolling Shutter Images Alive
May 31, 2023



Modern consumer cameras usually employ the rolling shutter (RS) mechanism, where images are captured by scanning scenes row-by-row, yielding RS distortions for dynamic scenes. To correct RS distortions, existing methods adopt a fully supervised learning manner, where high framerate global shutter (GS) images should be collected as ground-truth supervision. In this paper, we propose a Self-supervised learning framework for Dual reversed RS distortions Correction (SelfDRSC), where a DRSC network can be learned to generate a high framerate GS video only based on dual RS images with reversed distortions. In particular, a bidirectional distortion warping module is proposed for reconstructing dual reversed RS images, and then a self-supervised loss can be deployed to train DRSC network by enhancing the cycle consistency between input and reconstructed dual reversed RS images. Besides start and end RS scanning time, GS images at arbitrary intermediate scanning time can also be supervised in SelfDRSC, thus enabling the learned DRSC network to generate a high framerate GS video. Moreover, a simple yet effective self-distillation strategy is introduced in self-supervised loss for mitigating boundary artifacts in generated GS images. On synthetic dataset, SelfDRSC achieves better or comparable quantitative metrics in comparison to state-of-the-art methods trained in the full supervision manner. On real-world RS cases, our SelfDRSC can produce high framerate GS videos with finer correction textures and better temporary consistency. The source code and trained models are made publicly available at https://github.com/shangwei5/SelfDRSC.
Optimal Scheduling in IoT-Driven Smart Isolated Microgrids Based on Deep Reinforcement Learning
Apr 28, 2023



In this paper, we investigate the scheduling issue of diesel generators (DGs) in an Internet of Things (IoT)-Driven isolated microgrid (MG) by deep reinforcement learning (DRL). The renewable energy is fully exploited under the uncertainty of renewable generation and load demand. The DRL agent learns an optimal policy from history renewable and load data of previous days, where the policy can generate real-time decisions based on observations of past renewable and load data of previous hours collected by connected sensors. The goal is to reduce operating cost on the premise of ensuring supply-demand balance. In specific, a novel finite-horizon partial observable Markov decision process (POMDP) model is conceived considering the spinning reserve. In order to overcome the challenge of discrete-continuous hybrid action space due to the binary DG switching decision and continuous energy dispatch (ED) decision, a DRL algorithm, namely the hybrid action finite-horizon RDPG (HAFH-RDPG), is proposed. HAFH-RDPG seamlessly integrates two classical DRL algorithms, i.e., deep Q-network (DQN) and recurrent deterministic policy gradient (RDPG), based on a finite-horizon dynamic programming (DP) framework. Extensive experiments are performed with real-world data in an IoT-driven MG to evaluate the capability of the proposed algorithm in handling the uncertainty due to inter-hour and inter-day power fluctuation and to compare its performance with those of the benchmark algorithms.
Spatially Adaptive Self-Supervised Learning for Real-World Image Denoising
Mar 27, 2023Significant progress has been made in self-supervised image denoising (SSID) in the recent few years. However, most methods focus on dealing with spatially independent noise, and they have little practicality on real-world sRGB images with spatially correlated noise. Although pixel-shuffle downsampling has been suggested for breaking the noise correlation, it breaks the original information of images, which limits the denoising performance. In this paper, we propose a novel perspective to solve this problem, i.e., seeking for spatially adaptive supervision for real-world sRGB image denoising. Specifically, we take into account the respective characteristics of flat and textured regions in noisy images, and construct supervisions for them separately. For flat areas, the supervision can be safely derived from non-adjacent pixels, which are much far from the current pixel for excluding the influence of the noise-correlated ones. And we extend the blind-spot network to a blind-neighborhood network (BNN) for providing supervision on flat areas. For textured regions, the supervision has to be closely related to the content of adjacent pixels. And we present a locally aware network (LAN) to meet the requirement, while LAN itself is selectively supervised with the output of BNN. Combining these two supervisions, a denoising network (e.g., U-Net) can be well-trained. Extensive experiments show that our method performs favorably against state-of-the-art SSID methods on real-world sRGB photographs. The code is available at https://github.com/nagejacob/SpatiallyAdaptiveSSID.
SLOTH: Structured Learning and Task-based Optimization for Time Series Forecasting on Hierarchies
Feb 27, 2023



Multivariate time series forecasting with hierarchical structure is widely used in real-world applications, e.g., sales predictions for the geographical hierarchy formed by cities, states, and countries. The hierarchical time series (HTS) forecasting includes two sub-tasks, i.e., forecasting and reconciliation. In the previous works, hierarchical information is only integrated in the reconciliation step to maintain coherency, but not in forecasting step for accuracy improvement. In this paper, we propose two novel tree-based feature integration mechanisms, i.e., top-down convolution and bottom-up attention to leverage the information of the hierarchical structure to improve the forecasting performance. Moreover, unlike most previous reconciliation methods which either rely on strong assumptions or focus on coherent constraints only,we utilize deep neural optimization networks, which not only achieve coherency without any assumptions, but also allow more flexible and realistic constraints to achieve task-based targets, e.g., lower under-estimation penalty and meaningful decision-making loss to facilitate the subsequent downstream tasks. Experiments on real-world datasets demonstrate that our tree-based feature integration mechanism achieves superior performances on hierarchical forecasting tasks compared to the state-of-the-art methods, and our neural optimization networks can be applied to real-world tasks effectively without any additional effort under coherence and task-based constraints
End-to-End Modeling Hierarchical Time Series Using Autoregressive Transformer and Conditional Normalizing Flow based Reconciliation
Dec 28, 2022Multivariate time series forecasting with hierarchical structure is pervasive in real-world applications, demanding not only predicting each level of the hierarchy, but also reconciling all forecasts to ensure coherency, i.e., the forecasts should satisfy the hierarchical aggregation constraints. Moreover, the disparities of statistical characteristics between levels can be huge, worsened by non-Gaussian distributions and non-linear correlations. To this extent, we propose a novel end-to-end hierarchical time series forecasting model, based on conditioned normalizing flow-based autoregressive transformer reconciliation, to represent complex data distribution while simultaneously reconciling the forecasts to ensure coherency. Unlike other state-of-the-art methods, we achieve the forecasting and reconciliation simultaneously without requiring any explicit post-processing step. In addition, by harnessing the power of deep model, we do not rely on any assumption such as unbiased estimates or Gaussian distribution. Our evaluation experiments are conducted on four real-world hierarchical datasets from different industrial domains (three public ones and a dataset from the application servers of Alipay's data center) and the preliminary results demonstrate efficacy of our proposed method.