 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Speech Disentanglement for Voice Conversion using Rank Module and Speech Augmentation
Jun 21, 2023Voice Conversion (VC) converts the voice of a source speech to that of a target while maintaining the source's content. Speech can be mainly decomposed into four components: content, timbre, rhythm and pitch. Unfortunately, most related works only take into account content and timbre, which results in less natural speech. Some recent works are able to disentangle speech into several components, but they require laborious bottleneck tuning or various hand-crafted features, each assumed to contain disentangled speech information. In this paper, we propose a VC model that can automatically disentangle speech into four components using only two augmentation functions, without the requirement of multiple hand-crafted features or laborious bottleneck tuning. The proposed model is straightforward yet efficient, and the empirical results demonstrate that our model can achieve a better performance than the baseline, regarding disentanglement effectiveness and speech naturalness.
Learning Emotional Representations from Imbalanced Speech Data for Speech Emotion Recognition and Emotional Text-to-Speech
Jun 09, 2023



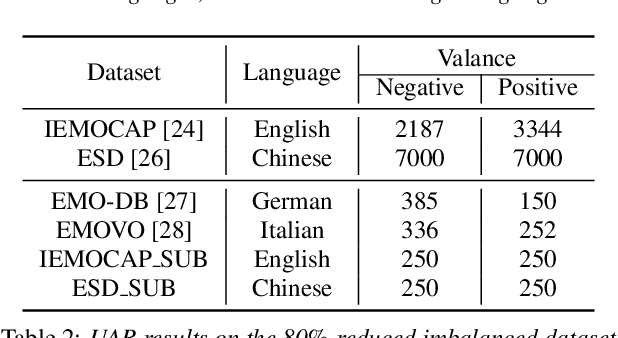
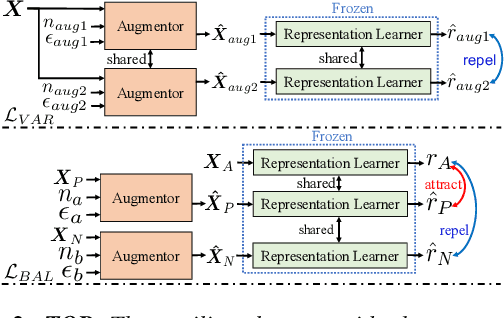
Effective speech emotional representations play a key role in Speech Emotion Recognition (SER) and Emotional Text-To-Speech (TTS) tasks. However, emotional speech samples are more difficult and expensive to acquire compared with Neutral style speech, which causes one issue that most related works unfortunately neglect: imbalanced datasets. Models might overfit to the majority Neutral class and fail to produce robust and effective emotional representations. In this paper, we propose an Emotion Extractor to address this issue. We use augmentation approaches to train the model and enable it to extract effective and generalizable emotional representations from imbalanced datasets. Our empirical results show that (1) for the SER task, the proposed Emotion Extractor surpasses the state-of-the-art baseline on three imbalanced datasets; (2) the produced representations from our Emotion Extractor benefit the TTS model, and enable it to synthesize more expressive speech.
Fine-grained Emotional Control of Text-To-Speech: Learning To Rank Inter- And Intra-Class Emotion Intensities
Mar 11, 2023



State-of-the-art Text-To-Speech (TTS) models are capable of producing high-quality speech. The generated speech, however, is usually neutral in emotional expression, whereas very often one would want fine-grained emotional control of words or phonemes. Although still challenging, the first TTS models have been recently proposed that are able to control voice by manually assigning emotion intensity. Unfortunately, due to the neglect of intra-class distance, the intensity differences are often unrecognizable. In this paper, we propose a fine-grained controllable emotional TTS, that considers both inter- and intra-class distances and be able to synthesize speech with recognizable intensity difference. Our subjective and objective experiments demonstrate that our model exceeds two state-of-the-art controllable TTS models for controllability, emotion expressiveness and naturalness.
A Graph Regularized Point Process Model For Event Propagation Sequence
Nov 21, 2022



Point process is the dominant paradigm for modeling event sequences occurring at irregular intervals. In this paper we aim at modeling latent dynamics of event propagation in graph, where the event sequence propagates in a directed weighted graph whose nodes represent event marks (e.g., event types). Most existing works have only considered encoding sequential event history into event representation and ignored the information from the latent graph structure. Besides they also suffer from poor model explainability, i.e., failing to uncover causal influence across a wide variety of nodes. To address these problems, we propose a Graph Regularized Point Process (GRPP) that can be decomposed into: 1) a graph propagation model that characterizes the event interactions across nodes with neighbors and inductively learns node representations; 2) a temporal attentive intensity model, whose excitation and time decay factors of past events on the current event are constructed via the contextualization of the node embedding. Moreover, by applying a graph regularization method, GRPP provides model interpretability by uncovering influence strengths between nodes. Numerical experiments on various datasets show that GRPP outperforms existing models on both the propagation time and node prediction by notable margins.
* IJCNN 2021
Generative Data Augmentation Guided by Triplet Loss for Speech Emotion Recognition
Aug 09, 2022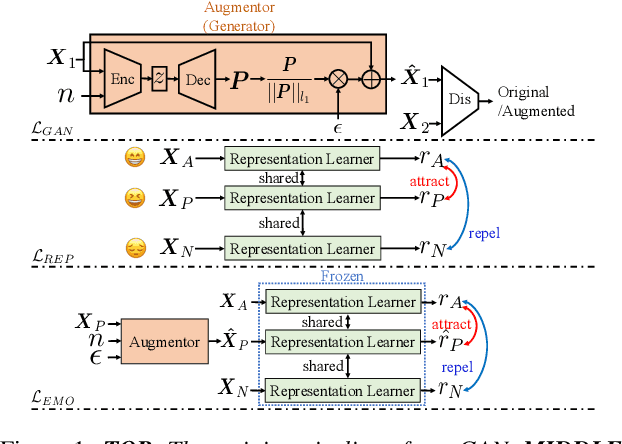
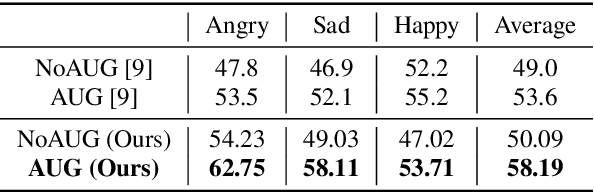
Speech Emotion Recognition (SER) is crucial for human-computer interaction but still remains a challenging problem because of two major obstacles: data scarcity and imbalance. Many datasets for SER are substantially imbalanced, where data utterances of one class (most often Neutral) are much more frequent than those of other classes. Furthermore, only a few data resources are available for many existing spoken languages. To address these problems, we exploit a GAN-based augmentation model guided by a triplet network, to improve SER performance given imbalanced and insufficient training data. We conduct experiments and demonstrate: 1) With a highly imbalanced dataset, our augmentation strategy significantly improves the SER performance (+8% recall score compared with the baseline). 2) Moreover, in a cross-lingual benchmark, where we train a model with enough source language utterances but very few target language utterances (around 50 in our experiments), our augmentation strategy brings benefits for the SER performance of all three target languages.
A Meta Reinforcement Learning Approach for Predictive Autoscaling in the Cloud
May 31, 2022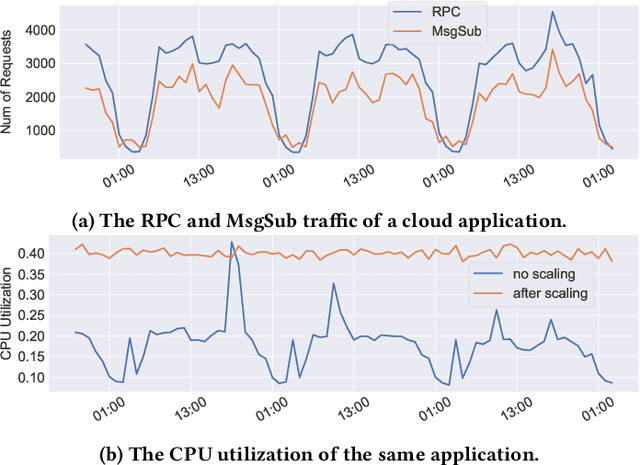

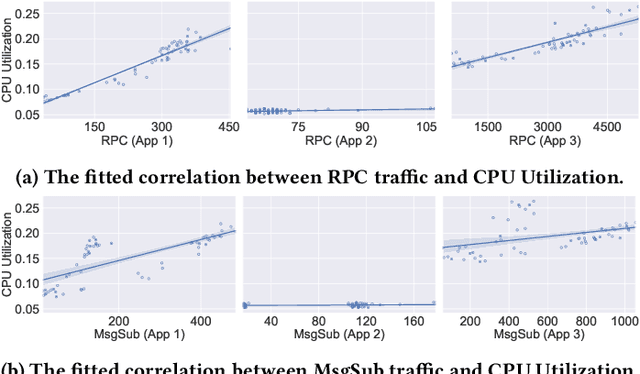

Predictive autoscaling (autoscaling with workload forecasting) is an important mechanism that supports autonomous adjustment of computing resources in accordance with fluctuating workload demands in the Cloud. In recent works, Reinforcement Learning (RL) has been introduced as a promising approach to learn the resource management policies to guide the scaling actions under the dynamic and uncertain cloud environment. However, RL methods face the following challenges in steering predictive autoscaling, such as lack of accuracy in decision-making, inefficient sampling and significant variability in workload patterns that may cause policies to fail at test time. To this end, we propose an end-to-end predictive meta model-based RL algorithm, aiming to optimally allocate resource to maintain a stable CPU utilization level, which incorporates a specially-designed deep periodic workload prediction model as the input and embeds the Neural Process to guide the learning of the optimal scaling actions over numerous application services in the Cloud. Our algorithm not only ensures the predictability and accuracy of the scaling strategy, but also enables the scaling decisions to adapt to the changing workloads with high sample efficiency. Our method has achieved significant performance improvement compared to the existing algorithms and has been deployed online at Alipay, supporting the autoscaling of applications for the world-leading payment platform.
Zero-shot Voice Conversion via Self-supervised Prosody Representation Learning
Oct 27, 2021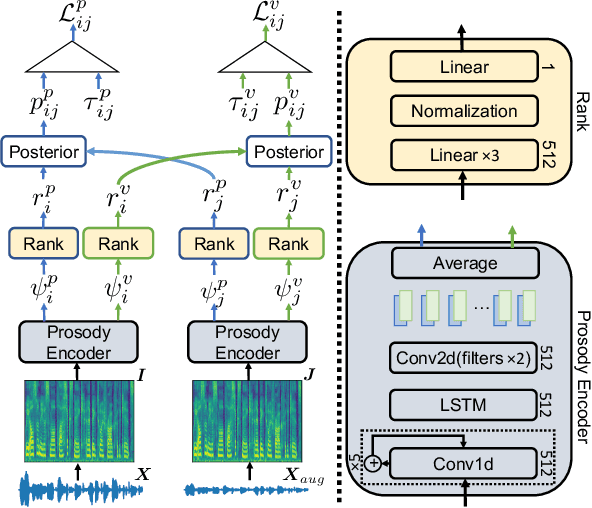
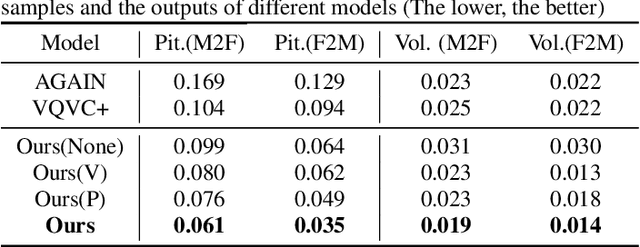
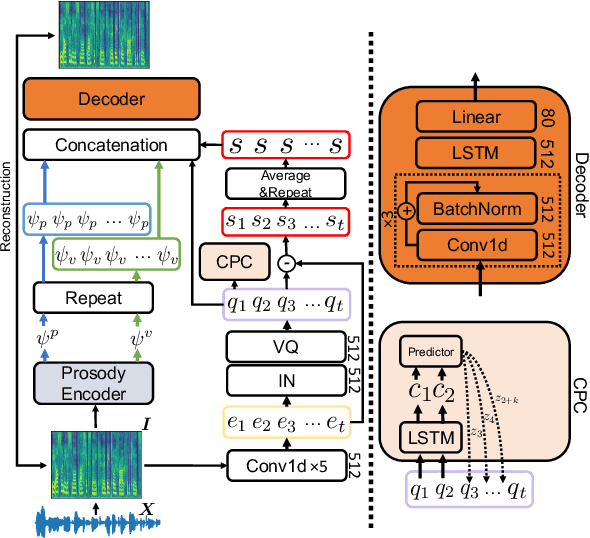
Voice Conversion (VC) for unseen speakers, also known as zero-shot VC, is an attractive topic due to its usefulness in real use-case scenarios. Recent work in this area made progress with disentanglement methods that separate utterance content and speaker characteristics. Although crucial, extracting disentangled prosody characteristics for unseen speakers remains an open issue. In this paper, we propose a novel self-supervised approach to effectively learn the prosody characteristics. Then, we use the learned prosodic representations to train our VC model for zero-shot conversion. Our evaluation demonstrates that we can efficiently extract disentangled prosody representation. Moreover, we show improved performance compared to the state-of-the-art zero-shot VC models.
NoiseVC: Towards High Quality Zero-Shot Voice Conversion
Apr 13, 2021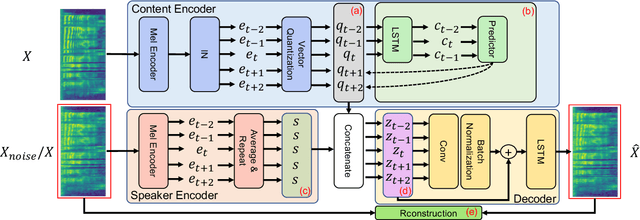
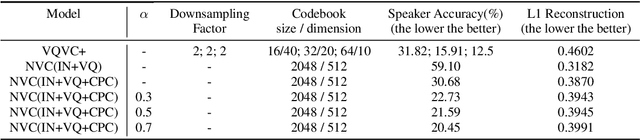
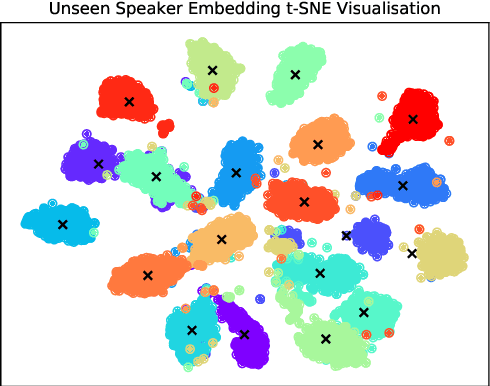
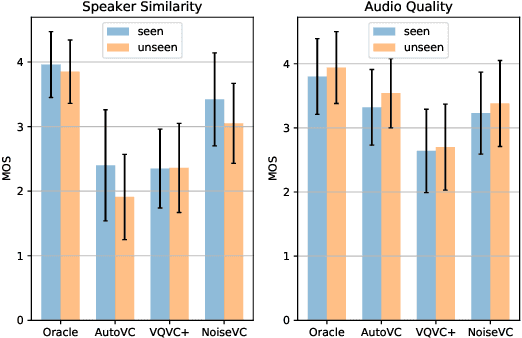
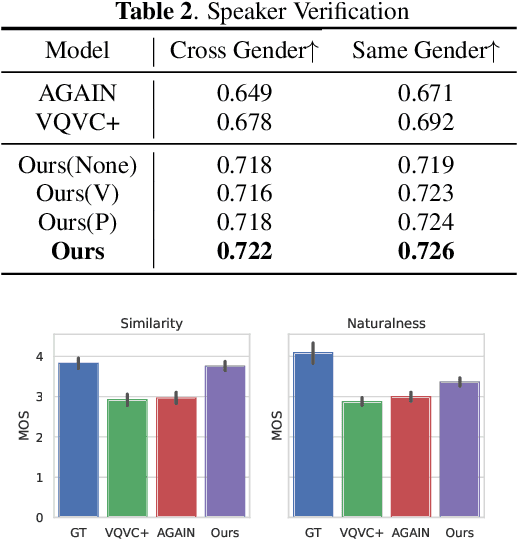
Voice conversion (VC) is a task that transforms voice from target audio to source without losing linguistic contents, it is challenging especially when source and target speakers are unseen during training (zero-shot VC). Previous approaches require a pre-trained model or linguistic data to do the zero-shot conversion. Meanwhile, VC models with Vector Quantization (VQ) or Instance Normalization (IN) are able to disentangle contents from audios and achieve successful conversions. However, disentanglement in these models highly relies on heavily constrained bottleneck layers, thus, the sound quality is drastically sacrificed. In this paper, we propose NoiseVC, an approach that can disentangle contents based on VQ and Contrastive Predictive Coding (CPC). Additionally, Noise Augmentation is performed to further enhance disentanglement capability. We conduct several experiments and demonstrate that NoiseVC has a strong disentanglement ability with a small sacrifice of quality.
Neural Physicist: Learning Physical Dynamics from Image Sequences
Jun 09, 2020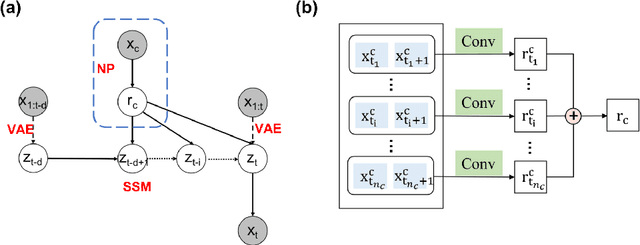
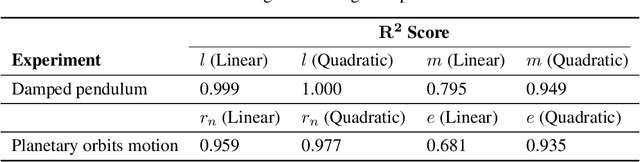

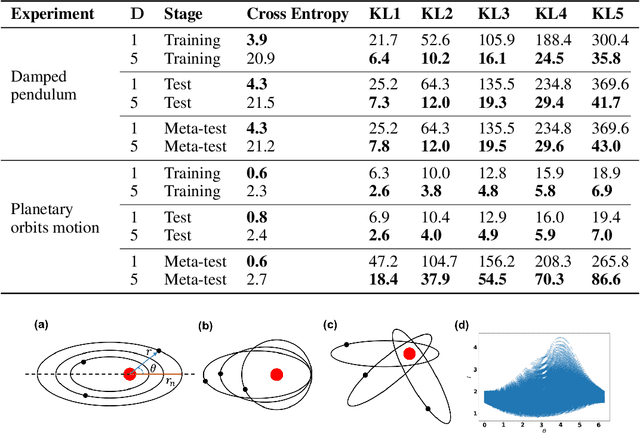
We present a novel architecture named Neural Physicist (NeurPhy) to learn physical dynamics directly from image sequences using deep neural networks. For any physical system, given the global system parameters, the time evolution of states is governed by the underlying physical laws. How to learn meaningful system representations in an end-to-end way and estimate accurate state transition dynamics facilitating long-term prediction have been long-standing challenges. In this paper, by leveraging recent progresses in representation learning and state space models (SSMs), we propose NeurPhy, which uses variational auto-encoder (VAE) to extract underlying Markovian dynamic state at each time step, neural process (NP) to extract the global system parameters, and a non-linear non-recurrent stochastic state space model to learn the physical dynamic transition. We apply NeurPhy to two physical experimental environments, i.e., damped pendulum and planetary orbits motion, and achieve promising results. Our model can not only extract the physically meaningful state representations, but also learn the state transition dynamics enabling long-term predictions for unseen image sequences. Furthermore, from the manifold dimension of the latent state space, we can easily identify the degree of freedom (DoF) of the underlying physical systems.
Riemannian Proximal Policy Optimization
May 19, 2020
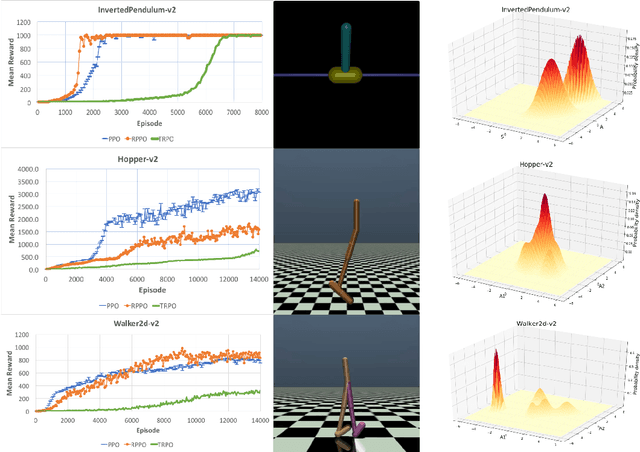
In this paper, We propose a general Riemannian proximal optimization algorithm with guaranteed convergence to solve Markov decision process (MDP) problems. To model policy functions in MDP, we employ Gaussian mixture model (GMM) and formulate it as a nonconvex optimization problem in the Riemannian space of positive semidefinite matrices. For two given policy functions, we also provide its lower bound on policy improvement by using bounds derived from the Wasserstein distance of GMMs. Preliminary experiments show the efficacy of our proposed Riemannian proximal policy optimization algorithm.