 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Electric Bus Charging Scheduling with Uncertainties Using Hierarchical Deep Reinforcement Learning
May 15, 2025



The growing adoption of Electric Buses (EBs) represents a significant step toward sustainable development. By utilizing Internet of Things (IoT) systems, charging stations can autonomously determine charging schedules based on real-time data. However, optimizing EB charging schedules remains a critical challenge due to uncertainties in travel time, energy consumption, and fluctuating electricity prices. Moreover, to address real-world complexities, charging policies must make decisions efficiently across multiple time scales and remain scalable for large EB fleets. In this paper, we propose a Hierarchical Deep Reinforcement Learning (HDRL) approach that reformulates the original Markov Decision Process (MDP) into two augmented MDPs. To solve these MDPs and enable multi-timescale decision-making, we introduce a novel HDRL algorithm, namely Double Actor-Critic Multi-Agent Proximal Policy Optimization Enhancement (DAC-MAPPO-E). Scalability challenges of the Double Actor-Critic (DAC) algorithm for large-scale EB fleets are addressed through enhancements at both decision levels. At the high level, we redesign the decentralized actor network and integrate an attention mechanism to extract relevant global state information for each EB, decreasing the size of neural networks. At the low level, the Multi-Agent Proximal Policy Optimization (MAPPO) algorithm is incorporated into the DAC framework, enabling decentralized and coordinated charging power decisions, reducing computational complexity and enhancing convergence speed. Extensive experiments with real-world data demonstrate the superior performance and scalability of DAC-MAPPO-E in optimizing EB fleet charging schedules.
Electric Bus Charging Schedules Relying on Real Data-Driven Targets Based on Hierarchical Deep Reinforcement Learning
May 15, 2025The charging scheduling problem of Electric Buses (EBs) is investigated based on Deep Reinforcement Learning (DRL). A Markov Decision Process (MDP) is conceived, where the time horizon includes multiple charging and operating periods in a day, while each period is further divided into multiple time steps. To overcome the challenge of long-range multi-phase planning with sparse reward, we conceive Hierarchical DRL (HDRL) for decoupling the original MDP into a high-level Semi-MDP (SMDP) and multiple low-level MDPs. The Hierarchical Double Deep Q-Network (HDDQN)-Hindsight Experience Replay (HER) algorithm is proposed for simultaneously solving the decision problems arising at different temporal resolutions. As a result, the high-level agent learns an effective policy for prescribing the charging targets for every charging period, while the low-level agent learns an optimal policy for setting the charging power of every time step within a single charging period, with the aim of minimizing the charging costs while meeting the charging target. It is proved that the flat policy constructed by superimposing the optimal high-level policy and the optimal low-level policy performs as well as the optimal policy of the original MDP. Since jointly learning both levels of policies is challenging due to the non-stationarity of the high-level agent and the sampling inefficiency of the low-level agent, we divide the joint learning process into two phases and exploit our new HER algorithm to manipulate the experience replay buffers for both levels of agents. Numerical experiments are performed with the aid of real-world data to evaluate the performance of the proposed algorithm.
Optimal Scheduling in IoT-Driven Smart Isolated Microgrids Based on Deep Reinforcement Learning
Apr 28, 2023



In this paper, we investigate the scheduling issue of diesel generators (DGs) in an Internet of Things (IoT)-Driven isolated microgrid (MG) by deep reinforcement learning (DRL). The renewable energy is fully exploited under the uncertainty of renewable generation and load demand. The DRL agent learns an optimal policy from history renewable and load data of previous days, where the policy can generate real-time decisions based on observations of past renewable and load data of previous hours collected by connected sensors. The goal is to reduce operating cost on the premise of ensuring supply-demand balance. In specific, a novel finite-horizon partial observable Markov decision process (POMDP) model is conceived considering the spinning reserve. In order to overcome the challenge of discrete-continuous hybrid action space due to the binary DG switching decision and continuous energy dispatch (ED) decision, a DRL algorithm, namely the hybrid action finite-horizon RDPG (HAFH-RDPG), is proposed. HAFH-RDPG seamlessly integrates two classical DRL algorithms, i.e., deep Q-network (DQN) and recurrent deterministic policy gradient (RDPG), based on a finite-horizon dynamic programming (DP) framework. Extensive experiments are performed with real-world data in an IoT-driven MG to evaluate the capability of the proposed algorithm in handling the uncertainty due to inter-hour and inter-day power fluctuation and to compare its performance with those of the benchmark algorithms.
Joint Energy Dispatch and Unit Commitment in Microgrids Based on Deep Reinforcement Learning
Jun 03, 2022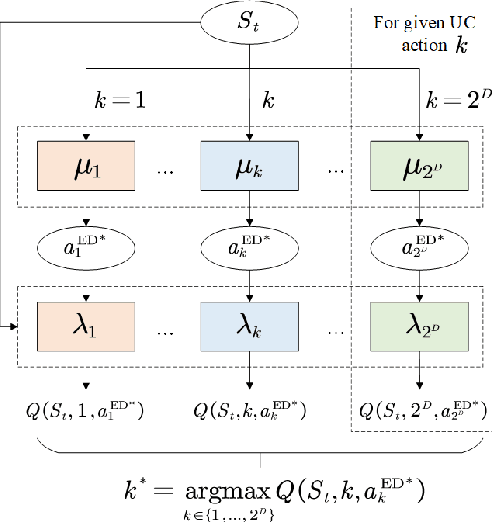
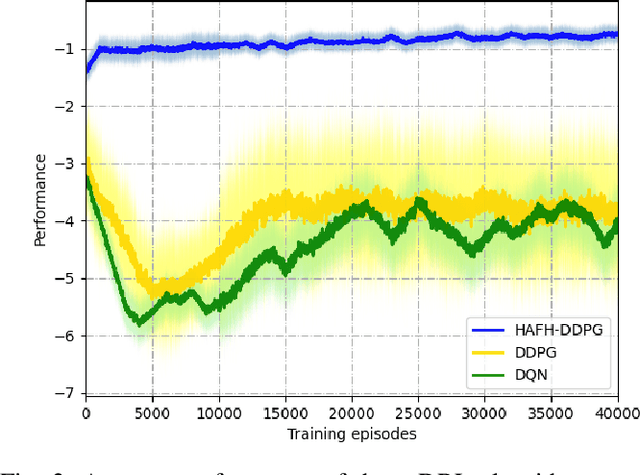
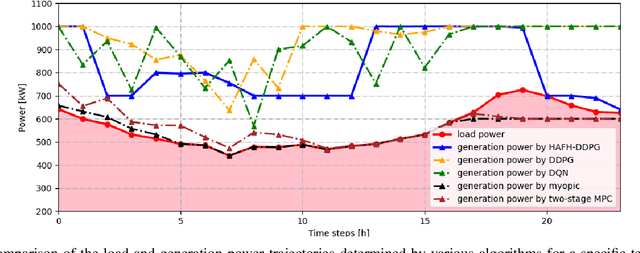
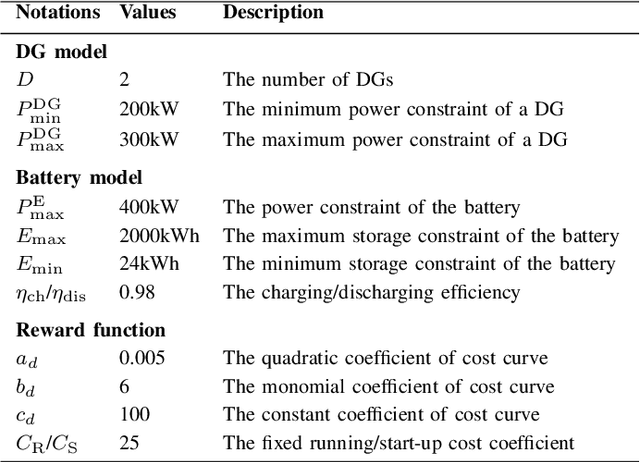
Nowadays, the application of microgrids (MG) with renewable energy is becoming more and more extensive, which creates a strong need for dynamic energy management. In this paper, deep reinforcement learning (DRL) is applied to learn an optimal policy for making joint energy dispatch (ED) and unit commitment (UC) decisions in an isolated MG, with the aim for reducing the total power generation cost on the premise of ensuring the supply-demand balance. In order to overcome the challenge of discrete-continuous hybrid action space due to joint ED and UC, we propose a DRL algorithm, i.e., the hybrid action finite-horizon DDPG (HAFH-DDPG), that seamlessly integrates two classical DRL algorithms, i.e., deep Q-network (DQN) and deep deterministic policy gradient (DDPG), based on a finite-horizon dynamic programming (DP) framework. Moreover, a diesel generator (DG) selection strategy is presented to support a simplified action space for reducing the computation complexity of this algorithm. Finally, the effectiveness of our proposed algorithm is verified through comparison with several baseline algorithms by experiments with real-world data set.
Federated Reinforcement Learning: Techniques, Applications, and Open Challenges
Aug 26, 2021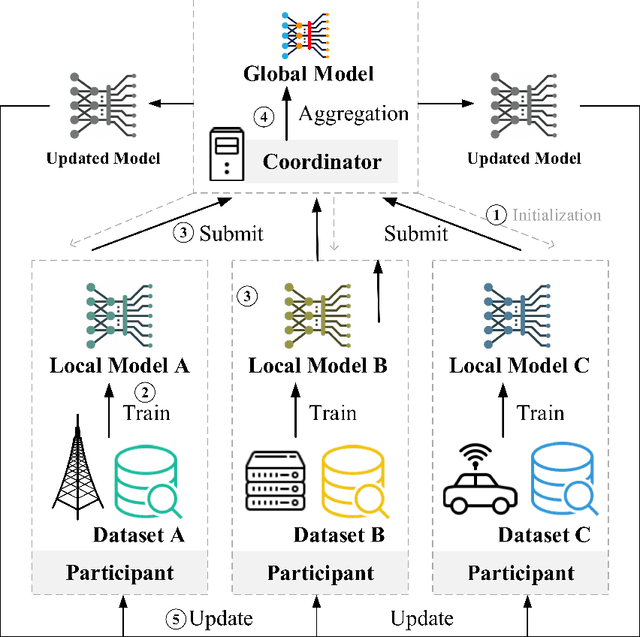
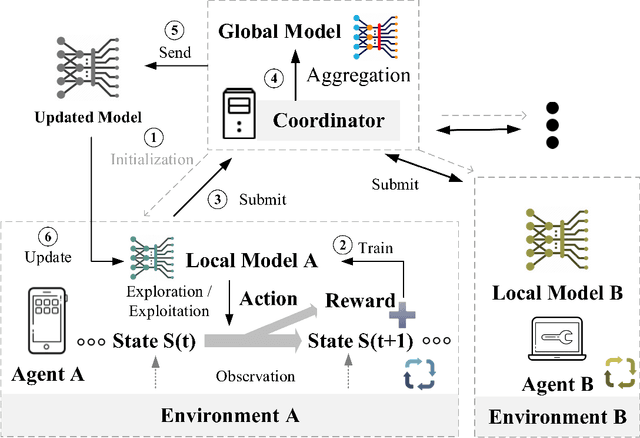
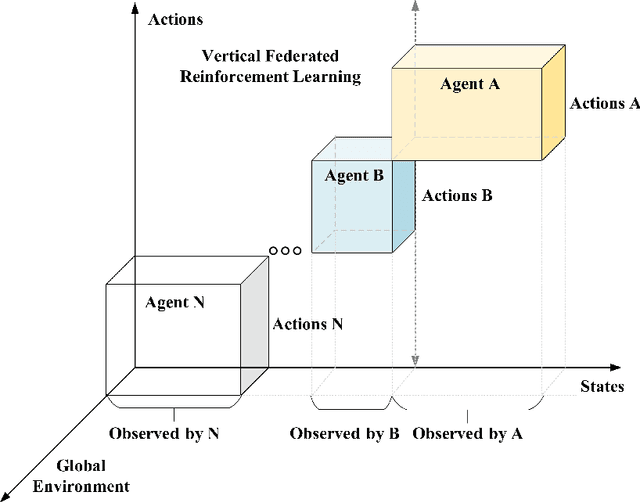
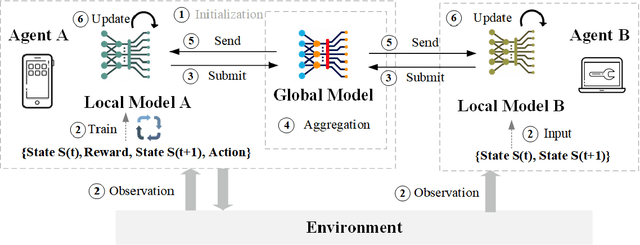
This paper presents a comprehensive survey of Federated Reinforcement Learning (FRL), an emerging and promising field in Reinforcement Learning (RL). Starting with a tutorial of Federated Learning (FL) and RL, we then focus on the introduction of FRL as a new method with great potential by leveraging the basic idea of FL to improve the performance of RL while preserving data-privacy. According to the distribution characteristics of the agents in the framework, FRL algorithms can be divided into two categories, i.e. Horizontal Federated Reinforcement Learning (HFRL) and Vertical Federated Reinforcement Learning (VFRL). We provide the detailed definitions of each category by formulas, investigate the evolution of FRL from a technical perspective, and highlight its advantages over previous RL algorithms. In addition, the existing works on FRL are summarized by application fields, including edge computing, communication, control optimization, and attack detection. Finally, we describe and discuss several key research directions that are crucial to solving the open problems within FRL.
Patent Analytics Based on Feature Vector Space Model: A Case of IoT
Apr 17, 2019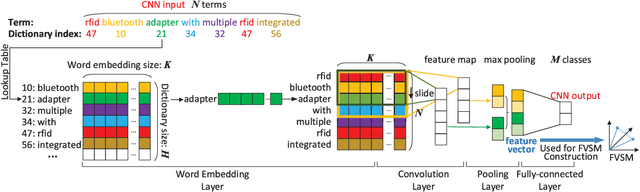
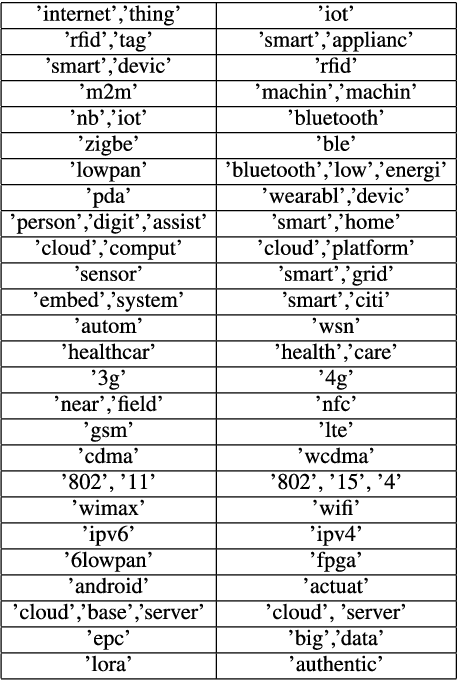
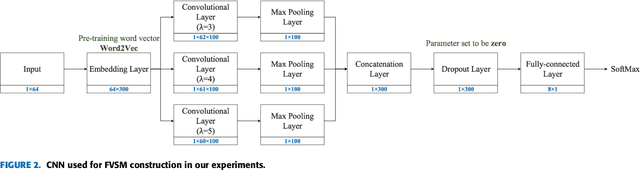

The number of approved patents worldwide increases rapidly each year, which requires new patent analytics to efficiently mine the valuable information attached to these patents. Vector space model (VSM) represents documents as high-dimensional vectors, where each dimension corresponds to a unique term. While originally proposed for information retrieval systems, VSM has also seen wide applications in patent analytics, and used as a fundamental tool to map patent documents to structured data. However, VSM method suffers from several limitations when applied to patent analysis tasks, such as loss of sentence-level semantics and curse-of-dimensionality problems. In order to address the above limitations, we propose a patent analytics based on feature vector space model (FVSM), where the FVSM is constructed by mapping patent documents to feature vectors extracted by convolutional neural networks (CNN). The applications of FVSM for three typical patent analysis tasks, i.e., patents similarity comparison, patent clustering, and patent map generation are discussed. A case study using patents related to Internet of Things (IoT) technology is illustrated to demonstrate the performance and effectiveness of FVSM. The proposed FVSM can be adopted by other patent analysis studies to replace VSM, based on which various big data learning tasks can be performed.