 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEQ-Net: Elastic Quantization Neural Networks
Aug 15, 2023



Current model quantization methods have shown their promising capability in reducing storage space and computation complexity. However, due to the diversity of quantization forms supported by different hardware, one limitation of existing solutions is that usually require repeated optimization for different scenarios. How to construct a model with flexible quantization forms has been less studied. In this paper, we explore a one-shot network quantization regime, named Elastic Quantization Neural Networks (EQ-Net), which aims to train a robust weight-sharing quantization supernet. First of all, we propose an elastic quantization space (including elastic bit-width, granularity, and symmetry) to adapt to various mainstream quantitative forms. Secondly, we propose the Weight Distribution Regularization Loss (WDR-Loss) and Group Progressive Guidance Loss (GPG-Loss) to bridge the inconsistency of the distribution for weights and output logits in the elastic quantization space gap. Lastly, we incorporate genetic algorithms and the proposed Conditional Quantization-Aware Accuracy Predictor (CQAP) as an estimator to quickly search mixed-precision quantized neural networks in supernet. Extensive experiments demonstrate that our EQ-Net is close to or even better than its static counterparts as well as state-of-the-art robust bit-width methods. Code can be available at \href{https://github.com/xuke225/EQ-Net.git}{https://github.com/xuke225/EQ-Net}.
Neural Categorical Priors for Physics-Based Character Control
Aug 14, 2023Recent advances in learning reusable motion priors have demonstrated their effectiveness in generating naturalistic behaviors. In this paper, we propose a new learning framework in this paradigm for controlling physics-based characters with significantly improved motion quality and diversity over existing state-of-the-art methods. The proposed method uses reinforcement learning (RL) to initially track and imitate life-like movements from unstructured motion clips using the discrete information bottleneck, as adopted in the Vector Quantized Variational AutoEncoder (VQ-VAE). This structure compresses the most relevant information from the motion clips into a compact yet informative latent space, i.e., a discrete space over vector quantized codes. By sampling codes in the space from a trained categorical prior distribution, high-quality life-like behaviors can be generated, similar to the usage of VQ-VAE in computer vision. Although this prior distribution can be trained with the supervision of the encoder's output, it follows the original motion clip distribution in the dataset and could lead to imbalanced behaviors in our setting. To address the issue, we further propose a technique named prior shifting to adjust the prior distribution using curiosity-driven RL. The outcome distribution is demonstrated to offer sufficient behavioral diversity and significantly facilitates upper-level policy learning for downstream tasks. We conduct comprehensive experiments using humanoid characters on two challenging downstream tasks, sword-shield striking and two-player boxing game. Our results demonstrate that the proposed framework is capable of controlling the character to perform considerably high-quality movements in terms of behavioral strategies, diversity, and realism. Videos, codes, and data are available at https://tencent-roboticsx.github.io/NCP/.
Learning Terrain-Adaptive Locomotion with Agile Behaviors by Imitating Animals
Aug 07, 2023



In this paper, we present a general learning framework for controlling a quadruped robot that can mimic the behavior of real animals and traverse challenging terrains. Our method consists of two steps: an imitation learning step to learn from motions of real animals, and a terrain adaptation step to enable generalization to unseen terrains. We capture motions from a Labrador on various terrains to facilitate terrain adaptive locomotion. Our experiments demonstrate that our policy can traverse various terrains and produce a natural-looking behavior. We deployed our method on the real quadruped robot Max via zero-shot simulation-to-reality transfer, achieving a speed of 1.1 m/s on stairs climbing.
EffLiFe: Efficient Light Field Generation via Hierarchical Sparse Gradient Descent
Jul 10, 2023



With the rise of Extended Reality (XR) technology, there is a growing need for real-time light field generation from sparse view inputs. Existing methods can be classified into offline techniques, which can generate high-quality novel views but at the cost of long inference/training time, and online methods, which either lack generalizability or produce unsatisfactory results. However, we have observed that the intrinsic sparse manifold of Multi-plane Images (MPI) enables a significant acceleration of light field generation while maintaining rendering quality. Based on this insight, we introduce EffLiFe, a novel light field optimization method, which leverages the proposed Hierarchical Sparse Gradient Descent (HSGD) to produce high-quality light fields from sparse view images in real time. Technically, the coarse MPI of a scene is first generated using a 3D CNN, and it is further sparsely optimized by focusing only on important MPI gradients in a few iterations. Nevertheless, relying solely on optimization can lead to artifacts at occlusion boundaries. Therefore, we propose an occlusion-aware iterative refinement module that removes visual artifacts in occluded regions by iteratively filtering the input. Extensive experiments demonstrate that our method achieves comparable visual quality while being 100x faster on average than state-of-the-art offline methods and delivering better performance (about 2 dB higher in PSNR) compared to other online approaches.
Crossing the Reality Gap in Tactile-Based Learning
May 23, 2023Tactile sensors are believed to be essential in robotic manipulation, and prior works often rely on experts to reason the sensor feedback and design a controller. With the recent advancement in data-driven approaches, complicated manipulation can be realised, but an accurate and efficient tactile simulation is necessary for policy training. To this end, we present an approach to model a commonly used pressure sensor array in simulation and to train a tactile-based manipulation policy with sim-to-real transfer in mind. Each taxel in our model is represented as a mass-spring-damper system, in which the parameters are iteratively identified as plausible ranges. This allows a policy to be trained with domain randomisation which improves its robustness to different environments. Then, we introduce encoders to further align the critical tactile features in a latent space. Finally, our experiments answer questions on tactile-based manipulation, tactile modelling and sim-to-real performance.
On the Impact of Data Quality on Image Classification Fairness
May 02, 2023


With the proliferation of algorithmic decision-making, increased scrutiny has been placed on these systems. This paper explores the relationship between the quality of the training data and the overall fairness of the models trained with such data in the context of supervised classification. We measure key fairness metrics across a range of algorithms over multiple image classification datasets that have a varying level of noise in both the labels and the training data itself. We describe noise in the labels as inaccuracies in the labelling of the data in the training set and noise in the data as distortions in the data, also in the training set. By adding noise to the original datasets, we can explore the relationship between the quality of the training data and the fairness of the output of the models trained on that data.
Exploiting Reward Shifting in Value-Based Deep RL
Sep 15, 2022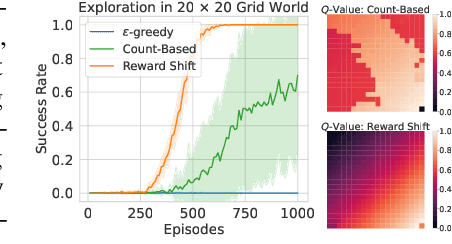
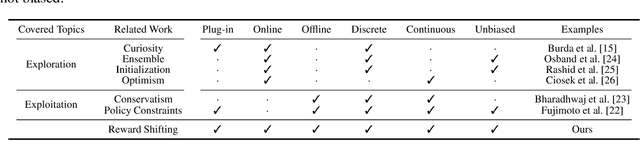

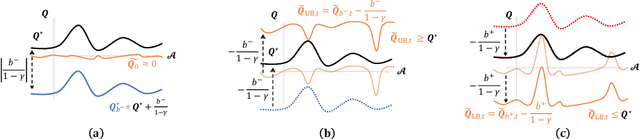
In this work, we study the simple yet universally applicable case of reward shaping in value-based Deep Reinforcement Learning (DRL). We show that reward shifting in the form of the linear transformation is equivalent to changing the initialization of the $Q$-function in function approximation. Based on such an equivalence, we bring the key insight that a positive reward shifting leads to conservative exploitation, while a negative reward shifting leads to curiosity-driven exploration. Accordingly, conservative exploitation improves offline RL value estimation, and optimistic value estimation improves exploration for online RL. We validate our insight on a range of RL tasks and show its improvement over baselines: (1) In offline RL, the conservative exploitation leads to improved performance based on off-the-shelf algorithms; (2) In online continuous control, multiple value functions with different shifting constants can be used to tackle the exploration-exploitation dilemma for better sample efficiency; (3) In discrete control tasks, a negative reward shifting yields an improvement over the curiosity-based exploration method.
Relative Policy-Transition Optimization for Fast Policy Transfer
Jun 13, 2022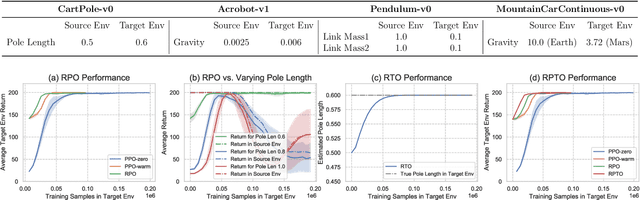
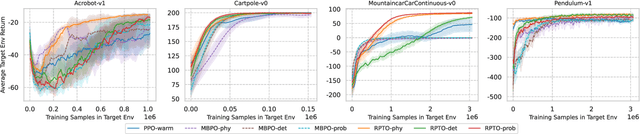
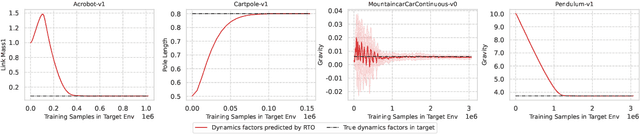
We consider the problem of policy transfer between two Markov Decision Processes (MDPs). We introduce a lemma based on existing theoretical results in reinforcement learning (RL) to measure the relativity between two arbitrary MDPs, that is the difference between any two cumulative expected returns defined on different policies and environment dynamics. Based on this lemma, we propose two new algorithms referred to as Relative Policy Optimization (RPO) and Relative Transition Optimization (RTO), which can offer fast policy transfer and dynamics modeling, respectively. RPO updates the policy using the relative policy gradient to transfer the policy evaluated in one environment to maximize the return in another, while RTO updates the parameterized dynamics model (if there exists) using the relative transition gradient to reduce the gap between the dynamics of the two environments. Then, integrating the two algorithms offers the complete algorithm Relative Policy-Transition Optimization (RPTO), in which the policy interacts with the two environments simultaneously, such that data collections from two environments, policy and transition updates are completed in one closed loop to form a principled learning framework for policy transfer. We demonstrate the effectiveness of RPTO in OpenAI gym's classic control tasks by creating policy transfer problems via variant dynamics.
RORL: Robust Offline Reinforcement Learning via Conservative Smoothing
Jun 06, 2022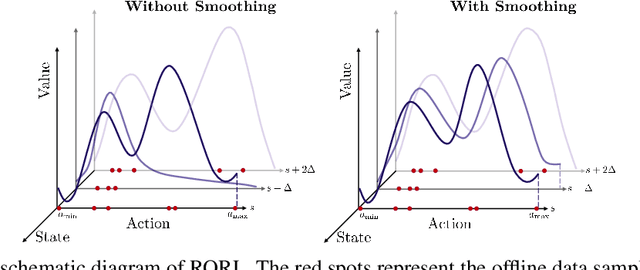
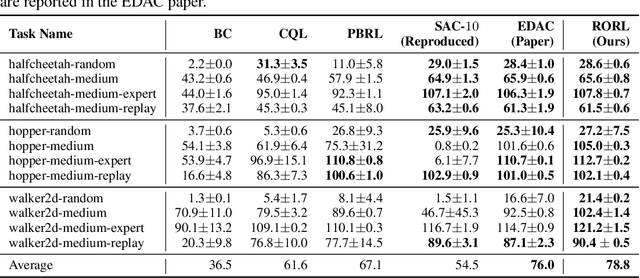
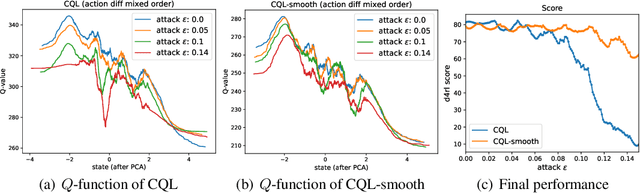
Offline reinforcement learning (RL) provides a promising direction to exploit the massive amount of offline data for complex decision-making tasks. Due to the distribution shift issue, current offline RL algorithms are generally designed to be conservative for value estimation and action selection. However, such conservatism impairs the robustness of learned policies, leading to a significant change even for a small perturbation on observations. To trade off robustness and conservatism, we propose Robust Offline Reinforcement Learning (RORL) with a novel conservative smoothing technique. In RORL, we explicitly introduce regularization on the policy and the value function for states near the dataset and additional conservative value estimation on these OOD states. Theoretically, we show RORL enjoys a tighter suboptimality bound than recent theoretical results in linear MDPs. We demonstrate that RORL can achieve the state-of-the-art performance on the general offline RL benchmark and is considerably robust to adversarial observation perturbation.
Rethinking Goal-conditioned Supervised Learning and Its Connection to Offline RL
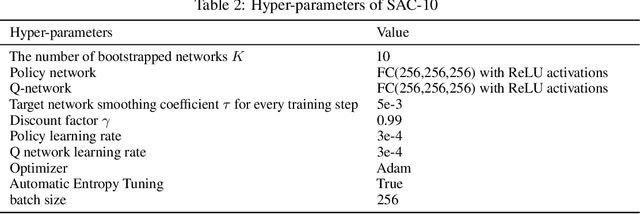
Feb 14, 2022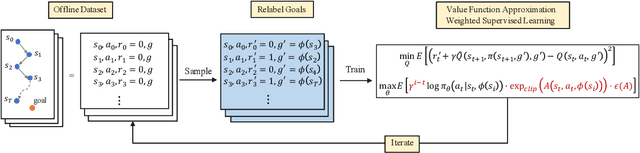
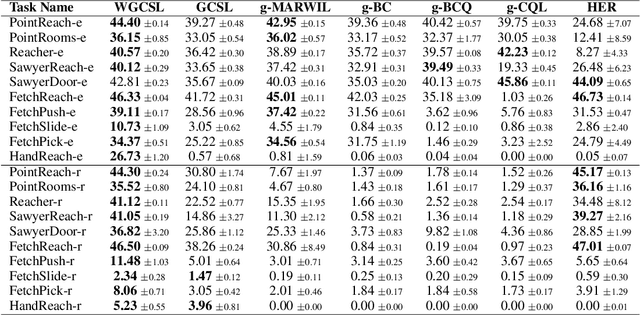
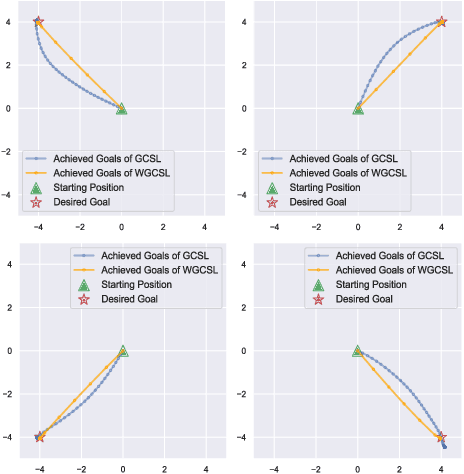
Solving goal-conditioned tasks with sparse rewards using self-supervised learning is promising because of its simplicity and stability over current reinforcement learning (RL) algorithms. A recent work, called Goal-Conditioned Supervised Learning (GCSL), provides a new learning framework by iteratively relabeling and imitating self-generated experiences. In this paper, we revisit the theoretical property of GCSL -- optimizing a lower bound of the goal reaching objective, and extend GCSL as a novel offline goal-conditioned RL algorithm. The proposed method is named Weighted GCSL (WGCSL), in which we introduce an advanced compound weight consisting of three parts (1) discounted weight for goal relabeling, (2) goal-conditioned exponential advantage weight, and (3) best-advantage weight. Theoretically, WGCSL is proved to optimize an equivalent lower bound of the goal-conditioned RL objective and generates monotonically improved policies via an iterated scheme. The monotonic property holds for any behavior policies, and therefore WGCSL can be applied to both online and offline settings. To evaluate algorithms in the offline goal-conditioned RL setting, we provide a benchmark including a range of point and simulated robot domains. Experiments in the introduced benchmark demonstrate that WGCSL can consistently outperform GCSL and existing state-of-the-art offline methods in the fully offline goal-conditioned setting.