 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative-Competitive Team Play of Real-World Craft Robots
Feb 24, 2026Multi-agent deep Reinforcement Learning (RL) has made significant progress in developing intelligent game-playing agents in recent years. However, the efficient training of collective robots using multi-agent RL and the transfer of learned policies to real-world applications remain open research questions. In this work, we first develop a comprehensive robotic system, including simulation, distributed learning framework, and physical robot components. We then propose and evaluate reinforcement learning techniques designed for efficient training of cooperative and competitive policies on this platform. To address the challenges of multi-agent sim-to-real transfer, we introduce Out of Distribution State Initialization (OODSI) to mitigate the impact of the sim-to-real gap. In the experiments, OODSI improves the Sim2Real performance by 20%. We demonstrate the effectiveness of our approach through experiments with a multi-robot car competitive game and a cooperative task in real-world settings.
Whole-Body Impedance Coordinative Control of Wheel-Legged Robot on Uncertain Terrain
Nov 15, 2024



This article propose a whole-body impedance coordinative control framework for a wheel-legged humanoid robot to achieve adaptability on complex terrains while maintaining robot upper body stability. The framework contains a bi-level control strategy. The outer level is a variable damping impedance controller, which optimizes the damping parameters to ensure the stability of the upper body while holding an object. The inner level employs Whole-Body Control (WBC) optimization that integrates real-time terrain estimation based on wheel-foot position and force data. It generates motor torques while accounting for dynamic constraints, joint limits,friction cones, real-time terrain updates, and a model-free friction compensation strategy. The proposed whole-body coordinative control method has been tested on a recently developed quadruped humanoid robot. The results demonstrate that the proposed algorithm effectively controls the robot, maintaining upper body stability to successfully complete a water-carrying task while adapting to varying terrains.
A Deconfounding Framework for Human Behavior Prediction: Enhancing Robotic Systems in Dynamic Environments
Oct 27, 2024



Accurate prediction of human behavior is crucial for effective human-robot interaction (HRI) systems, especially in dynamic environments where real-time decisions are essential. This paper addresses the challenge of forecasting future human behavior using multivariate time series data from wearable sensors, which capture various aspects of human movement. The presence of hidden confounding factors in this data often leads to biased predictions, limiting the reliability of traditional models. To overcome this, we propose a robust predictive model that integrates deconfounding techniques with advanced time series prediction methods, enhancing the model's ability to isolate true causal relationships and improve prediction accuracy. Evaluation on real-world datasets demonstrates that our approach significantly outperforms traditional methods, providing a more reliable foundation for responsive and adaptive HRI systems.
Uncovering the Secrets of Human-Like Movement: A Fresh Perspective on Motion Planning
Sep 18, 2024



This article explores human-like movement from a fresh perspective on motion planning. We analyze the coordinated and compliant movement mechanisms of the human body from the perspective of biomechanics. Based on these mechanisms, we propose an optimal control framework that integrates compliant control dynamics, optimizing robotic arm motion through a response time matrix. This matrix sets the timing parameters for joint movements, turning the system into a time-parameterized optimal control problem. The model focuses on the interaction between active and passive joints under external disturbances, improving adaptability and compliance. This method achieves optimal trajectory generation and balances precision and compliance. Experimental results on both a manipulator and a humanoid robot validate the approach.
A Fairness-Oriented Control Framework for Safety-Critical Multi-Robot Systems: Alternative Authority Control
Sep 16, 2024



This paper proposes a fair control framework for multi-robot systems, which integrates the newly introduced Alternative Authority Control (AAC) and Flexible Control Barrier Function (F-CBF). Control authority refers to a single robot which can plan its trajectory while considering others as moving obstacles, meaning the other robots do not have authority to plan their own paths. The AAC method dynamically distributes the control authority, enabling fair and coordinated movement across the system. This approach significantly improves computational efficiency, scalability, and robustness in complex environments. The proposed F-CBF extends traditional CBFs by incorporating obstacle shape, velocity, and orientation. F-CBF enhances safety by accurate dynamic obstacle avoidance. The framework is validated through simulations in multi-robot scenarios, demonstrating its safety, robustness and computational efficiency.
Combined optimization ghost imaging based on random speckle field
Mar 06, 2024



Ghost imaging is a non local imaging technology, which can obtain target information by measuring the second-order intensity correlation between the reference light field and the target detection light field. However, the current imaging environment requires a large number of measurement data, and the imaging results also have the problems of low image resolution and long reconstruction time. Therefore, using orthogonal methods such as QR decomposition, a variety of optimization methods for speckle patterns are designed combined with Kronecker product,which can help to shorten the imaging time, improve the imaging quality and image noise resistance.
Learning Highly Dynamic Behaviors for Quadrupedal Robots
Feb 21, 2024Learning highly dynamic behaviors for robots has been a longstanding challenge. Traditional approaches have demonstrated robust locomotion, but the exhibited behaviors lack diversity and agility. They employ approximate models, which lead to compromises in performance. Data-driven approaches have been shown to reproduce agile behaviors of animals, but typically have not been able to learn highly dynamic behaviors. In this paper, we propose a learning-based approach to enable robots to learn highly dynamic behaviors from animal motion data. The learned controller is deployed on a quadrupedal robot and the results show that the controller is able to reproduce highly dynamic behaviors including sprinting, jumping and sharp turning. Various behaviors can be activated through human interaction using a stick with markers attached to it. Based on the motion pattern of the stick, the robot exhibits walking, running, sitting and jumping, much like the way humans interact with a pet.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
Learning Terrain-Adaptive Locomotion with Agile Behaviors by Imitating Animals
Aug 07, 2023



In this paper, we present a general learning framework for controlling a quadruped robot that can mimic the behavior of real animals and traverse challenging terrains. Our method consists of two steps: an imitation learning step to learn from motions of real animals, and a terrain adaptation step to enable generalization to unseen terrains. We capture motions from a Labrador on various terrains to facilitate terrain adaptive locomotion. Our experiments demonstrate that our policy can traverse various terrains and produce a natural-looking behavior. We deployed our method on the real quadruped robot Max via zero-shot simulation-to-reality transfer, achieving a speed of 1.1 m/s on stairs climbing.
Relative Policy-Transition Optimization for Fast Policy Transfer
Jun 13, 2022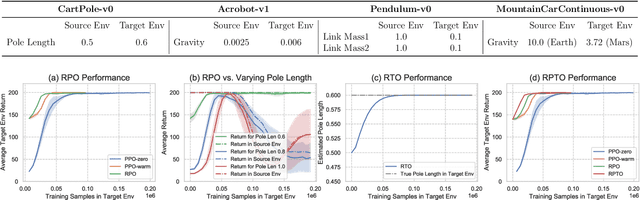
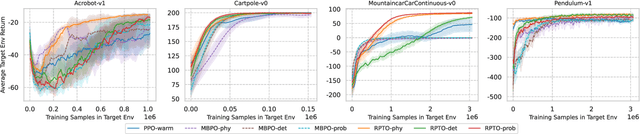
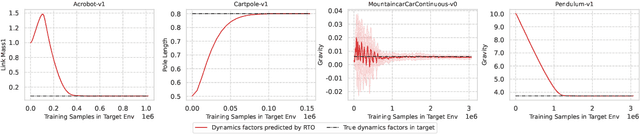
We consider the problem of policy transfer between two Markov Decision Processes (MDPs). We introduce a lemma based on existing theoretical results in reinforcement learning (RL) to measure the relativity between two arbitrary MDPs, that is the difference between any two cumulative expected returns defined on different policies and environment dynamics. Based on this lemma, we propose two new algorithms referred to as Relative Policy Optimization (RPO) and Relative Transition Optimization (RTO), which can offer fast policy transfer and dynamics modeling, respectively. RPO updates the policy using the relative policy gradient to transfer the policy evaluated in one environment to maximize the return in another, while RTO updates the parameterized dynamics model (if there exists) using the relative transition gradient to reduce the gap between the dynamics of the two environments. Then, integrating the two algorithms offers the complete algorithm Relative Policy-Transition Optimization (RPTO), in which the policy interacts with the two environments simultaneously, such that data collections from two environments, policy and transition updates are completed in one closed loop to form a principled learning framework for policy transfer. We demonstrate the effectiveness of RPTO in OpenAI gym's classic control tasks by creating policy transfer problems via variant dynamics.