 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Mix or To Merge: Toward Multi-Domain Reinforcement Learning for Large Language Models
Feb 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) plays a key role in stimulating the explicit reasoning capability of Large Language Models (LLMs). We can achieve expert-level performance in some specific domains via RLVR, such as coding or math. When a general multi-domain expert-level model is required, we need to carefully consider the collaboration of RLVR across different domains. The current state-of-the-art models mainly employ two different training paradigms for multi-domain RLVR: mixed multi-task RLVR and separate RLVR followed by model merging. However, most of the works did not provide a detailed comparison and analysis about these paradigms. To this end, we choose multiple commonly used high-level tasks (e.g., math, coding, science, and instruction following) as our target domains and design extensive qualitative and quantitative experiments using open-source datasets. We find the RLVR across domains exhibits few mutual interferences, and reasoning-intensive domains demonstrate mutually synergistic effects. Furthermore, we analyze the internal mechanisms of mutual gains from the perspectives of weight space geometry, model prediction behavior, and information constraints. This project is named as M2RL that means Mixed multi-task training or separate training followed by model Merging for Reinforcement Learning, and the homepage is at https://github.com/mosAI25/M2RL
MAG-Nav: Language-Driven Object Navigation Leveraging Memory-Reserved Active Grounding
Aug 07, 2025Visual navigation in unknown environments based solely on natural language descriptions is a key capability for intelligent robots. In this work, we propose a navigation framework built upon off-the-shelf Visual Language Models (VLMs), enhanced with two human-inspired mechanisms: perspective-based active grounding, which dynamically adjusts the robot's viewpoint for improved visual inspection, and historical memory backtracking, which enables the system to retain and re-evaluate uncertain observations over time. Unlike existing approaches that passively rely on incidental visual inputs, our method actively optimizes perception and leverages memory to resolve ambiguity, significantly improving vision-language grounding in complex, unseen environments. Our framework operates in a zero-shot manner, achieving strong generalization to diverse and open-ended language descriptions without requiring labeled data or model fine-tuning. Experimental results on Habitat-Matterport 3D (HM3D) show that our method outperforms state-of-the-art approaches in language-driven object navigation. We further demonstrate its practicality through real-world deployment on a quadruped robot, achieving robust and effective navigation performance.
MinD: Unified Visual Imagination and Control via Hierarchical World Models
Jun 23, 2025



Video generation models (VGMs) offer a promising pathway for unified world modeling in robotics by integrating simulation, prediction, and manipulation. However, their practical application remains limited due to (1) slowgeneration speed, which limits real-time interaction, and (2) poor consistency between imagined videos and executable actions. To address these challenges, we propose Manipulate in Dream (MinD), a hierarchical diffusion-based world model framework that employs a dual-system design for vision-language manipulation. MinD executes VGM at low frequencies to extract video prediction features, while leveraging a high-frequency diffusion policy for real-time interaction. This architecture enables low-latency, closed-loop control in manipulation with coherent visual guidance. To better coordinate the two systems, we introduce a video-action diffusion matching module (DiffMatcher), with a novel co-training strategy that uses separate schedulers for each diffusion model. Specifically, we introduce a diffusion-forcing mechanism to DiffMatcher that aligns their intermediate representations during training, helping the fast action model better understand video-based predictions. Beyond manipulation, MinD also functions as a world simulator, reliably predicting task success or failure in latent space before execution. Trustworthy analysis further shows that VGMs can preemptively evaluate task feasibility and mitigate risks. Extensive experiments across multiple benchmarks demonstrate that MinD achieves state-of-the-art manipulation (63%+) in RL-Bench, advancing the frontier of unified world modeling in robotics.
VLN-Game: Vision-Language Equilibrium Search for Zero-Shot Semantic Navigation
Nov 18, 2024Following human instructions to explore and search for a specified target in an unfamiliar environment is a crucial skill for mobile service robots. Most of the previous works on object goal navigation have typically focused on a single input modality as the target, which may lead to limited consideration of language descriptions containing detailed attributes and spatial relationships. To address this limitation, we propose VLN-Game, a novel zero-shot framework for visual target navigation that can process object names and descriptive language targets effectively. To be more precise, our approach constructs a 3D object-centric spatial map by integrating pre-trained visual-language features with a 3D reconstruction of the physical environment. Then, the framework identifies the most promising areas to explore in search of potential target candidates. A game-theoretic vision language model is employed to determine which target best matches the given language description. Experiments conducted on the Habitat-Matterport 3D (HM3D) dataset demonstrate that the proposed framework achieves state-of-the-art performance in both object goal navigation and language-based navigation tasks. Moreover, we show that VLN-Game can be easily deployed on real-world robots. The success of VLN-Game highlights the promising potential of using game-theoretic methods with compact vision-language models to advance decision-making capabilities in robotic systems. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/vln-game.
VidEgoThink: Assessing Egocentric Video Understanding Capabilities for Embodied AI
Oct 15, 2024Recent advancements in Multi-modal Large Language Models (MLLMs) have opened new avenues for applications in Embodied AI. Building on previous work, EgoThink, we introduce VidEgoThink, a comprehensive benchmark for evaluating egocentric video understanding capabilities. To bridge the gap between MLLMs and low-level control in Embodied AI, we design four key interrelated tasks: video question-answering, hierarchy planning, visual grounding and reward modeling. To minimize manual annotation costs, we develop an automatic data generation pipeline based on the Ego4D dataset, leveraging the prior knowledge and multimodal capabilities of GPT-4o. Three human annotators then filter the generated data to ensure diversity and quality, resulting in the VidEgoThink benchmark. We conduct extensive experiments with three types of models: API-based MLLMs, open-source image-based MLLMs, and open-source video-based MLLMs. Experimental results indicate that all MLLMs, including GPT-4o, perform poorly across all tasks related to egocentric video understanding. These findings suggest that foundation models still require significant advancements to be effectively applied to first-person scenarios in Embodied AI. In conclusion, VidEgoThink reflects a research trend towards employing MLLMs for egocentric vision, akin to human capabilities, enabling active observation and interaction in the complex real-world environments.
An Efficient Model-Based Approach on Learning Agile Motor Skills without Reinforcement
Mar 04, 2024



Learning-based methods have improved locomotion skills of quadruped robots through deep reinforcement learning. However, the sim-to-real gap and low sample efficiency still limit the skill transfer. To address this issue, we propose an efficient model-based learning framework that combines a world model with a policy network. We train a differentiable world model to predict future states and use it to directly supervise a Variational Autoencoder (VAE)-based policy network to imitate real animal behaviors. This significantly reduces the need for real interaction data and allows for rapid policy updates. We also develop a high-level network to track diverse commands and trajectories. Our simulated results show a tenfold sample efficiency increase compared to reinforcement learning methods such as PPO. In real-world testing, our policy achieves proficient command-following performance with only a two-minute data collection period and generalizes well to new speeds and paths.
Learning Highly Dynamic Behaviors for Quadrupedal Robots
Feb 21, 2024Learning highly dynamic behaviors for robots has been a longstanding challenge. Traditional approaches have demonstrated robust locomotion, but the exhibited behaviors lack diversity and agility. They employ approximate models, which lead to compromises in performance. Data-driven approaches have been shown to reproduce agile behaviors of animals, but typically have not been able to learn highly dynamic behaviors. In this paper, we propose a learning-based approach to enable robots to learn highly dynamic behaviors from animal motion data. The learned controller is deployed on a quadrupedal robot and the results show that the controller is able to reproduce highly dynamic behaviors including sprinting, jumping and sharp turning. Various behaviors can be activated through human interaction using a stick with markers attached to it. Based on the motion pattern of the stick, the robot exhibits walking, running, sitting and jumping, much like the way humans interact with a pet.
Terrain-Aware Quadrupedal Locomotion via Reinforcement Learning
Oct 11, 2023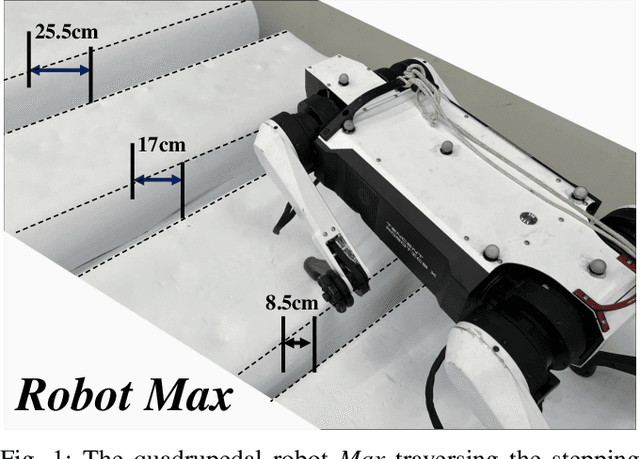
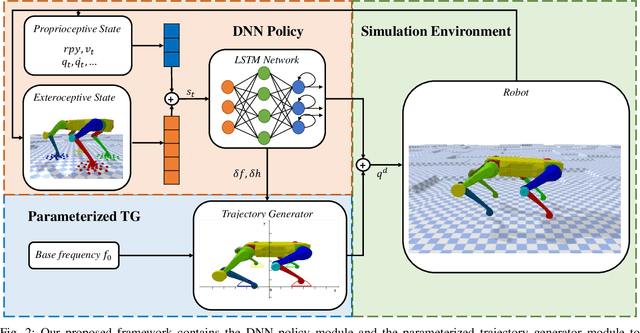
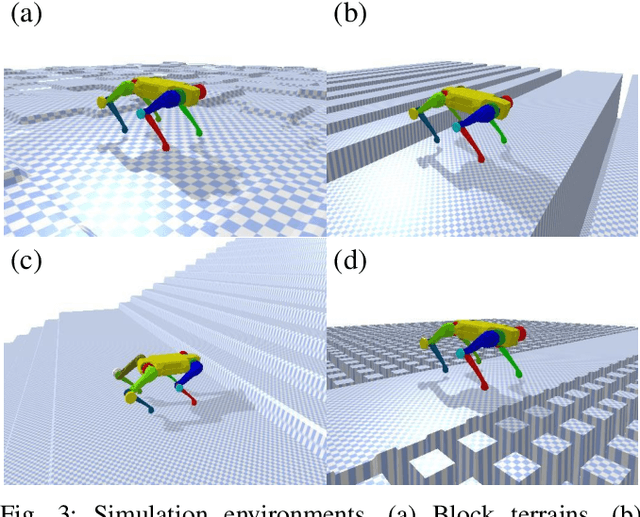
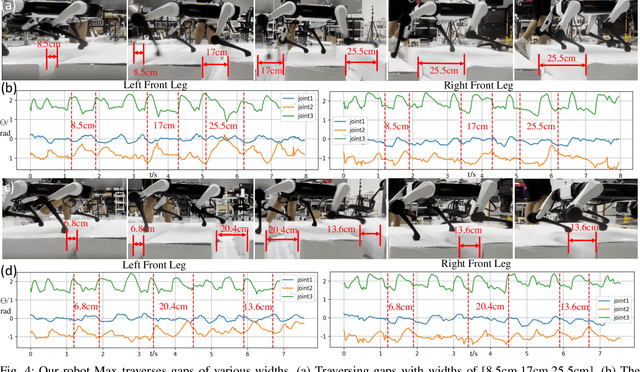
In nature, legged animals have developed the ability to adapt to challenging terrains through perception, allowing them to plan safe body and foot trajectories in advance, which leads to safe and energy-efficient locomotion. Inspired by this observation, we present a novel approach to train a Deep Neural Network (DNN) policy that integrates proprioceptive and exteroceptive states with a parameterized trajectory generator for quadruped robots to traverse rough terrains. Our key idea is to use a DNN policy that can modify the parameters of the trajectory generator, such as foot height and frequency, to adapt to different terrains. To encourage the robot to step on safe regions and save energy consumption, we propose foot terrain reward and lifting foot height reward, respectively. By incorporating these rewards, our method can learn a safer and more efficient terrain-aware locomotion policy that can move a quadruped robot flexibly in any direction. To evaluate the effectiveness of our approach, we conduct simulation experiments on challenging terrains, including stairs, stepping stones, and poles. The simulation results demonstrate that our approach can successfully direct the robot to traverse such tough terrains in any direction. Furthermore, we validate our method on a real legged robot, which learns to traverse stepping stones with gaps over 25.5cm.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
Learning Terrain-Adaptive Locomotion with Agile Behaviors by Imitating Animals
Aug 07, 2023



In this paper, we present a general learning framework for controlling a quadruped robot that can mimic the behavior of real animals and traverse challenging terrains. Our method consists of two steps: an imitation learning step to learn from motions of real animals, and a terrain adaptation step to enable generalization to unseen terrains. We capture motions from a Labrador on various terrains to facilitate terrain adaptive locomotion. Our experiments demonstrate that our policy can traverse various terrains and produce a natural-looking behavior. We deployed our method on the real quadruped robot Max via zero-shot simulation-to-reality transfer, achieving a speed of 1.1 m/s on stairs climbing.