 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeelBERto: Self-supervised Commonsense Learning for Question Answering
Mar 17, 2022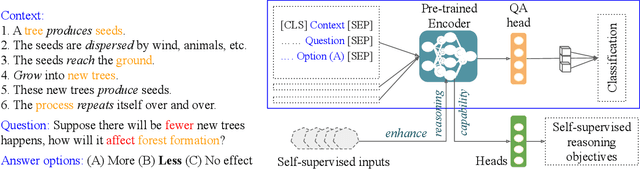

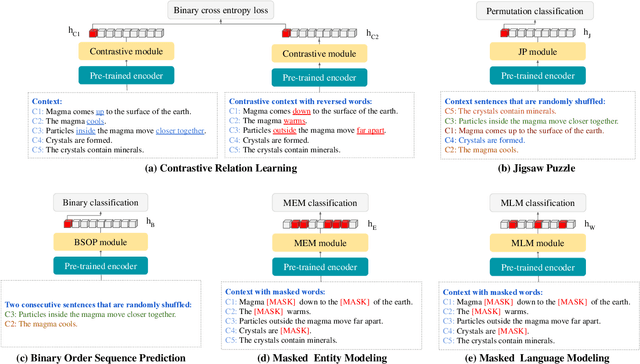
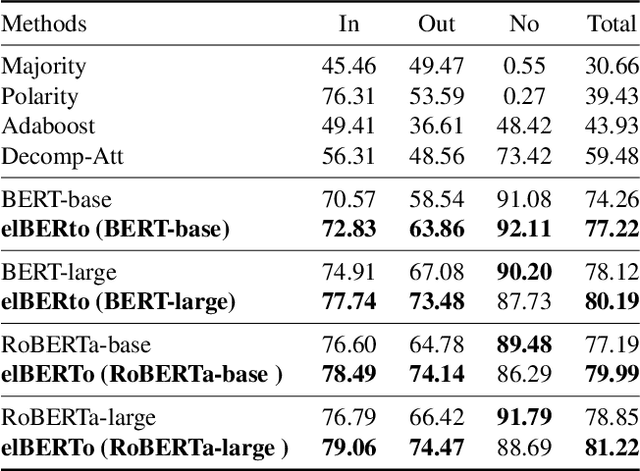
Commonsense question answering requires reasoning about everyday situations and causes and effects implicit in context. Typically, existing approaches first retrieve external evidence and then perform commonsense reasoning using these evidence. In this paper, we propose a Self-supervised Bidirectional Encoder Representation Learning of Commonsense (elBERto) framework, which is compatible with off-the-shelf QA model architectures. The framework comprises five self-supervised tasks to force the model to fully exploit the additional training signals from contexts containing rich commonsense. The tasks include a novel Contrastive Relation Learning task to encourage the model to distinguish between logically contrastive contexts, a new Jigsaw Puzzle task that requires the model to infer logical chains in long contexts, and three classic SSL tasks to maintain pre-trained models language encoding ability. On the representative WIQA, CosmosQA, and ReClor datasets, elBERto outperforms all other methods, including those utilizing explicit graph reasoning and external knowledge retrieval. Moreover, elBERto achieves substantial improvements on out-of-paragraph and no-effect questions where simple lexical similarity comparison does not help, indicating that it successfully learns commonsense and is able to leverage it when given dynamic context.
Capturing Actionable Dynamics with Structured Latent Ordinary Differential Equations
Feb 25, 2022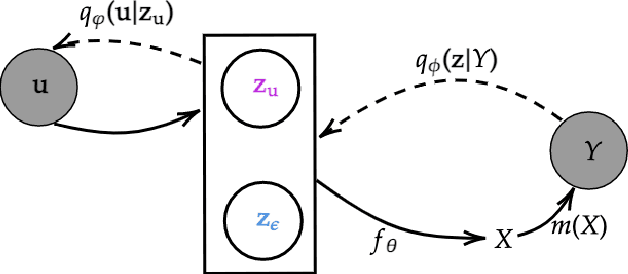


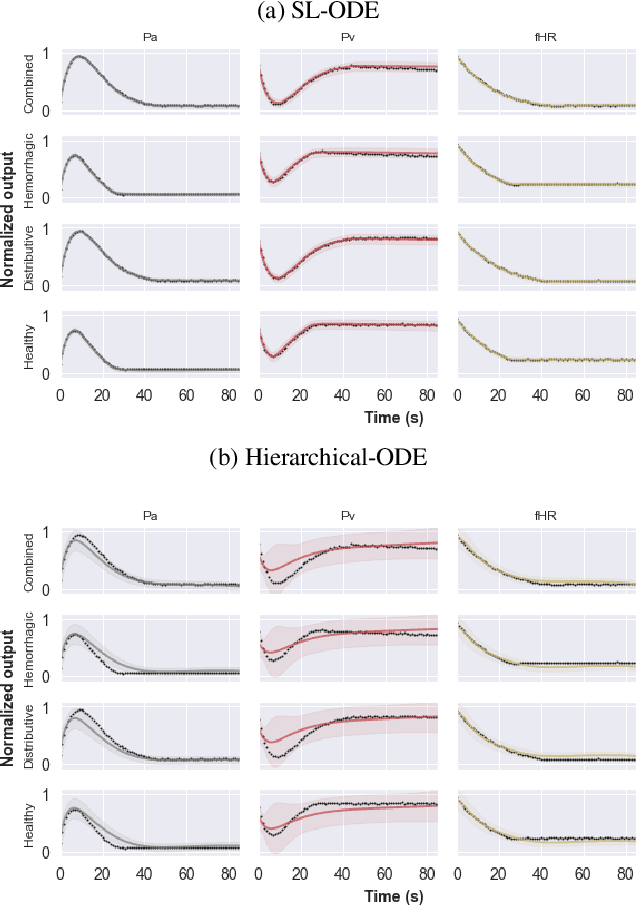
End-to-end learning of dynamical systems with black-box models, such as neural ordinary differential equations (ODEs), provides a flexible framework for learning dynamics from data without prescribing a mathematical model for the dynamics. Unfortunately, this flexibility comes at the cost of understanding the dynamical system, for which ODEs are used ubiquitously. Further, experimental data are collected under various conditions (inputs), such as treatments, or grouped in some way, such as part of sub-populations. Understanding the effects of these system inputs on system outputs is crucial to have any meaningful model of a dynamical system. To that end, we propose a structured latent ODE model that explicitly captures system input variations within its latent representation. Building on a static latent variable specification, our model learns (independent) stochastic factors of variation for each input to the system, thus separating the effects of the system inputs in the latent space. This approach provides actionable modeling through the controlled generation of time-series data for novel input combinations (or perturbations). Additionally, we propose a flexible approach for quantifying uncertainties, leveraging a quantile regression formulation. Experimental results on challenging biological datasets show consistent improvements over competitive baselines in the controlled generation of observational data and prediction of biologically meaningful system inputs.
Explainable multiple abnormality classification of chest CT volumes with AxialNet and HiResCAM
Nov 24, 2021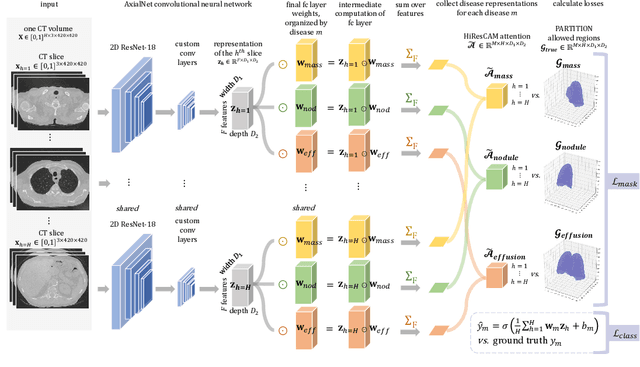
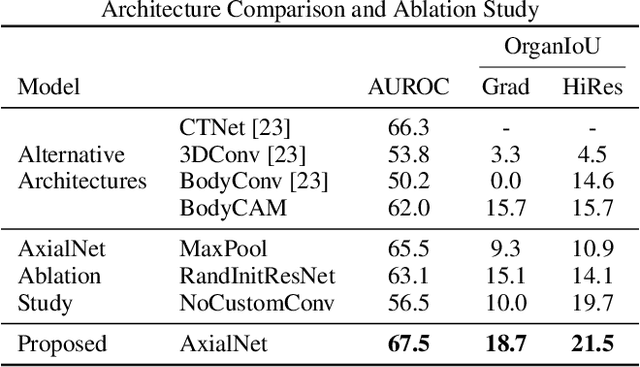
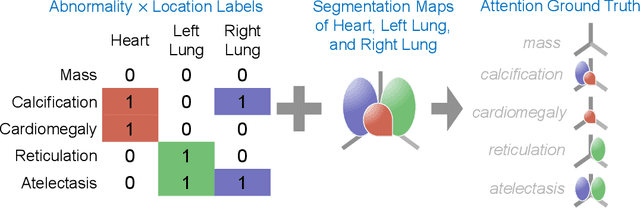

Understanding model predictions is critical in healthcare, to facilitate rapid verification of model correctness and to guard against use of models that exploit confounding variables. We introduce the challenging new task of explainable multiple abnormality classification in volumetric medical images, in which a model must indicate the regions used to predict each abnormality. To solve this task, we propose a multiple instance learning convolutional neural network, AxialNet, that allows identification of top slices for each abnormality. Next we incorporate HiResCAM, an attention mechanism, to identify sub-slice regions. We prove that for AxialNet, HiResCAM explanations are guaranteed to reflect the locations the model used, unlike Grad-CAM which sometimes highlights irrelevant locations. Armed with a model that produces faithful explanations, we then aim to improve the model's learning through a novel mask loss that leverages HiResCAM and 3D allowed regions to encourage the model to predict abnormalities based only on the organs in which those abnormalities appear. The 3D allowed regions are obtained automatically through a new approach, PARTITION, that combines location information extracted from radiology reports with organ segmentation maps obtained through morphological image processing. Overall, we propose the first model for explainable multi-abnormality prediction in volumetric medical images, and then use the mask loss to achieve a 33% improvement in organ localization of multiple abnormalities in the RAD-ChestCT data set of 36,316 scans, representing the state of the art. This work advances the clinical applicability of multiple abnormality modeling in chest CT volumes.
Finite-Time Consensus Learning for Decentralized Optimization with Nonlinear Gossiping
Nov 13, 2021
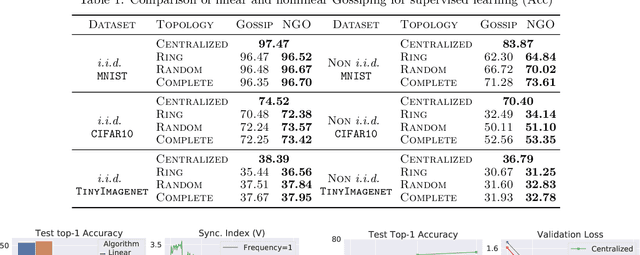
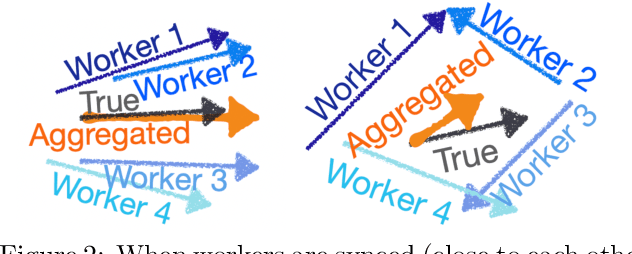

Distributed learning has become an integral tool for scaling up machine learning and addressing the growing need for data privacy. Although more robust to the network topology, decentralized learning schemes have not gained the same level of popularity as their centralized counterparts for being less competitive performance-wise. In this work, we attribute this issue to the lack of synchronization among decentralized learning workers, showing both empirically and theoretically that the convergence rate is tied to the synchronization level among the workers. Such motivated, we present a novel decentralized learning framework based on nonlinear gossiping (NGO), that enjoys an appealing finite-time consensus property to achieve better synchronization. We provide a careful analysis of its convergence and discuss its merits for modern distributed optimization applications, such as deep neural networks. Our analysis on how communication delay and randomized chats affect learning further enables the derivation of practical variants that accommodate asynchronous and randomized communications. To validate the effectiveness of our proposal, we benchmark NGO against competing solutions through an extensive set of tests, with encouraging results reported.
Variational Inference with Holder Bounds
Nov 13, 2021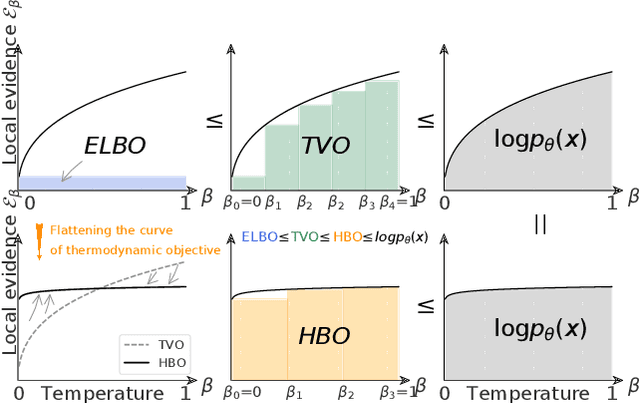
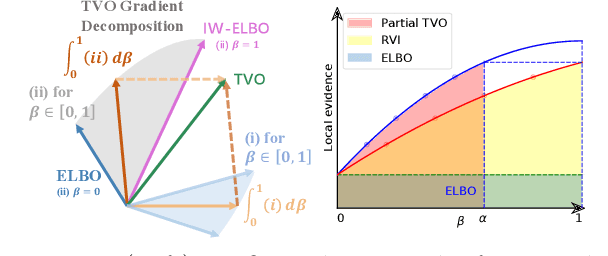
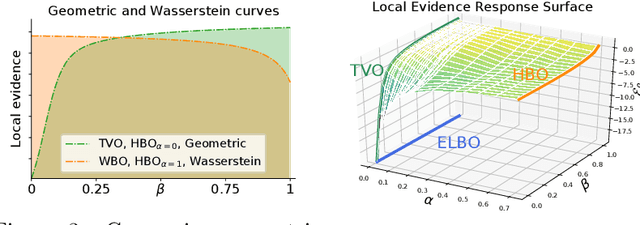
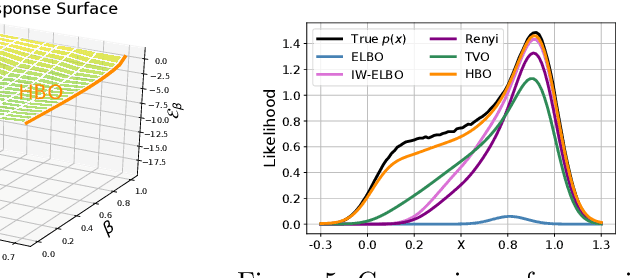
The recent introduction of thermodynamic integration techniques has provided a new framework for understanding and improving variational inference (VI). In this work, we present a careful analysis of the thermodynamic variational objective (TVO), bridging the gap between existing variational objectives and shedding new insights to advance the field. In particular, we elucidate how the TVO naturally connects the three key variational schemes, namely the importance-weighted VI, Renyi-VI, and MCMC-VI, which subsumes most VI objectives employed in practice. To explain the performance gap between theory and practice, we reveal how the pathological geometry of thermodynamic curves negatively affects TVO. By generalizing the integration path from the geometric mean to the weighted Holder mean, we extend the theory of TVO and identify new opportunities for improving VI. This motivates our new VI objectives, named the Holder bounds, which flatten the thermodynamic curves and promise to achieve a one-step approximation of the exact marginal log-likelihood. A comprehensive discussion on the choices of numerical estimators is provided. We present strong empirical evidence on both synthetic and real-world datasets to support our claims.
Hölder Bounds for Sensitivity Analysis in Causal Reasoning
Jul 09, 2021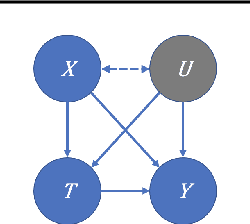

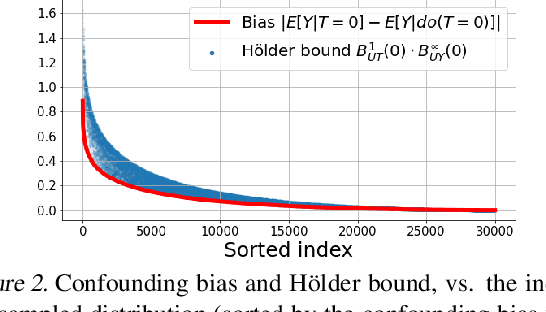
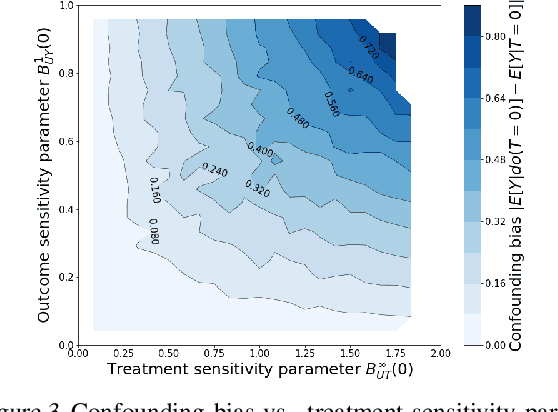
We examine interval estimation of the effect of a treatment T on an outcome Y given the existence of an unobserved confounder U. Using H\"older's inequality, we derive a set of bounds on the confounding bias |E[Y|T=t]-E[Y|do(T=t)]| based on the degree of unmeasured confounding (i.e., the strength of the connection U->T, and the strength of U->Y). These bounds are tight either when U is independent of T or when U is independent of Y given T (when there is no unobserved confounding). We focus on a special case of this bound depending on the total variation distance between the distributions p(U) and p(U|T=t), as well as the maximum (over all possible values of U) deviation of the conditional expected outcome E[Y|U=u,T=t] from the average expected outcome E[Y|T=t]. We discuss possible calibration strategies for this bound to get interval estimates for treatment effects, and experimentally validate the bound using synthetic and semi-synthetic datasets.
Imputation-Free Learning from Incomplete Observations
Jul 05, 2021

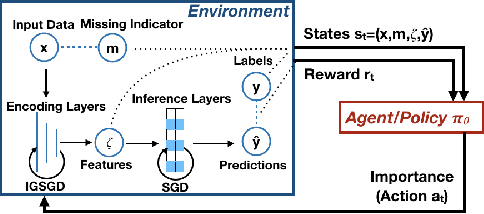
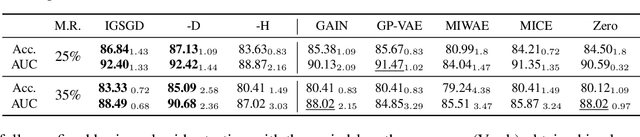
Although recent works have developed methods that can generate estimations (or imputations) of the missing entries in a dataset to facilitate downstream analysis, most depend on assumptions that may not align with real-world applications and could suffer from poor performance in subsequent tasks. This is particularly true if the data have large missingness rates or a small population. More importantly, the imputation error could be propagated into the prediction step that follows, causing the gradients used to train the prediction models to be biased. Consequently, in this work, we introduce the importance guided stochastic gradient descent (IGSGD) method to train multilayer perceptrons (MLPs) and long short-term memories (LSTMs) to directly perform inference from inputs containing missing values without imputation. Specifically, we employ reinforcement learning (RL) to adjust the gradients used to train the models via back-propagation. This not only reduces bias but allows the model to exploit the underlying information behind missingness patterns. We test the proposed approach on real-world time-series (i.e., MIMIC-III), tabular data obtained from an eye clinic, and a standard dataset (i.e., MNIST), where our imputation-free predictions outperform the traditional two-step imputation-based predictions using state-of-the-art imputation methods.
Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE
Jul 02, 2021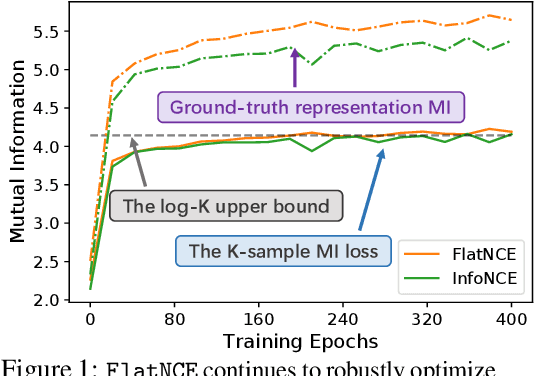


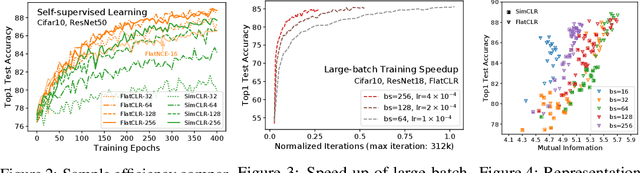
InfoNCE-based contrastive representation learners, such as SimCLR, have been tremendously successful in recent years. However, these contrastive schemes are notoriously resource demanding, as their effectiveness breaks down with small-batch training (i.e., the log-K curse, whereas K is the batch-size). In this work, we reveal mathematically why contrastive learners fail in the small-batch-size regime, and present a novel simple, non-trivial contrastive objective named FlatNCE, which fixes this issue. Unlike InfoNCE, our FlatNCE no longer explicitly appeals to a discriminative classification goal for contrastive learning. Theoretically, we show FlatNCE is the mathematical dual formulation of InfoNCE, thus bridging the classical literature on energy modeling; and empirically, we demonstrate that, with minimal modification of code, FlatNCE enables immediate performance boost independent of the subject-matter engineering efforts. The significance of this work is furthered by the powerful generalization of contrastive learning techniques, and the introduction of new tools to monitor and diagnose contrastive training. We substantiate our claims with empirical evidence on CIFAR10, ImageNet, and other datasets, where FlatNCE consistently outperforms InfoNCE.
Tight Mutual Information Estimation With Contrastive Fenchel-Legendre Optimization
Jul 02, 2021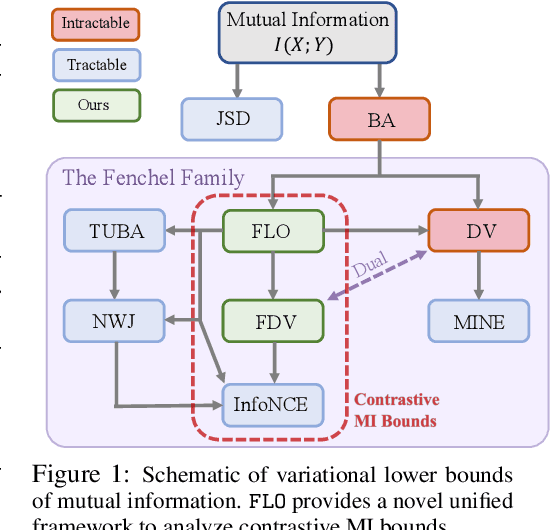
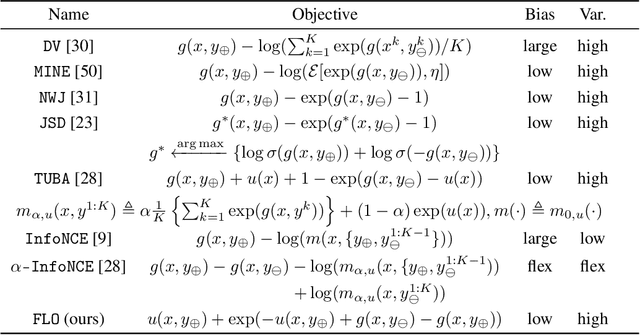
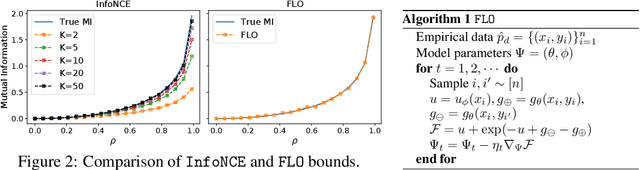

Successful applications of InfoNCE and its variants have popularized the use of contrastive variational mutual information (MI) estimators in machine learning. While featuring superior stability, these estimators crucially depend on costly large-batch training, and they sacrifice bound tightness for variance reduction. To overcome these limitations, we revisit the mathematics of popular variational MI bounds from the lens of unnormalized statistical modeling and convex optimization. Our investigation not only yields a new unified theoretical framework encompassing popular variational MI bounds but also leads to a novel, simple, and powerful contrastive MI estimator named as FLO. Theoretically, we show that the FLO estimator is tight, and it provably converges under stochastic gradient descent. Empirically, our FLO estimator overcomes the limitations of its predecessors and learns more efficiently. The utility of FLO is verified using an extensive set of benchmarks, which also reveals the trade-offs in practical MI estimation.
Towards Fair Federated Learning with Zero-Shot Data Augmentation
Apr 27, 2021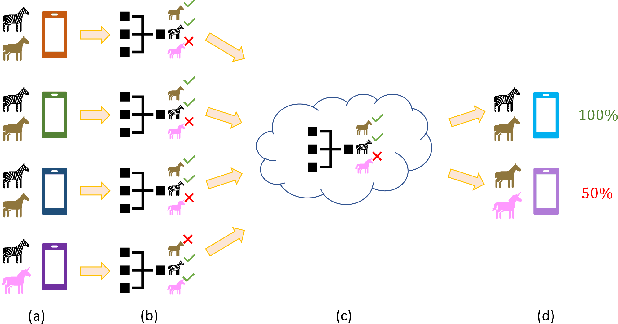
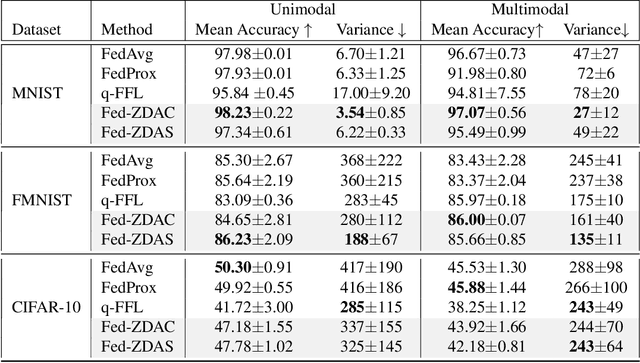
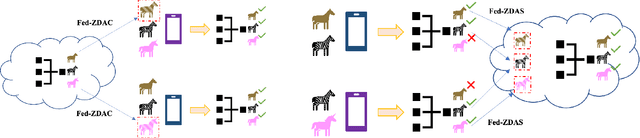
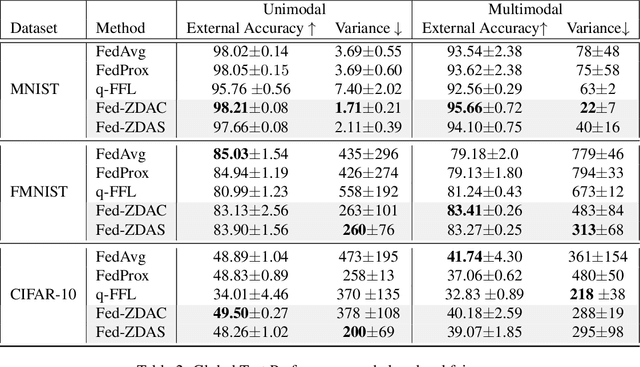
Federated learning has emerged as an important distributed learning paradigm, where a server aggregates a global model from many client-trained models while having no access to the client data. Although it is recognized that statistical heterogeneity of the client local data yields slower global model convergence, it is less commonly recognized that it also yields a biased federated global model with a high variance of accuracy across clients. In this work, we aim to provide federated learning schemes with improved fairness. To tackle this challenge, we propose a novel federated learning system that employs zero-shot data augmentation on under-represented data to mitigate statistical heterogeneity and encourage more uniform accuracy performance across clients in federated networks. We study two variants of this scheme, Fed-ZDAC (federated learning with zero-shot data augmentation at the clients) and Fed-ZDAS (federated learning with zero-shot data augmentation at the server). Empirical results on a suite of datasets demonstrate the effectiveness of our methods on simultaneously improving the test accuracy and fairness.