 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Quantization Methods for Efficient Neural Network Inference
Mar 25, 2021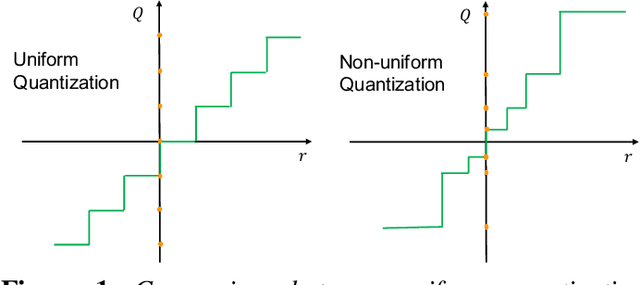
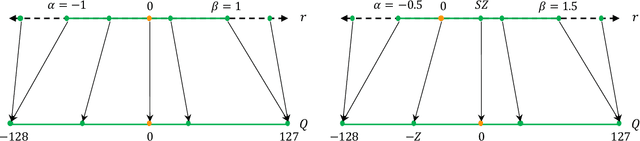
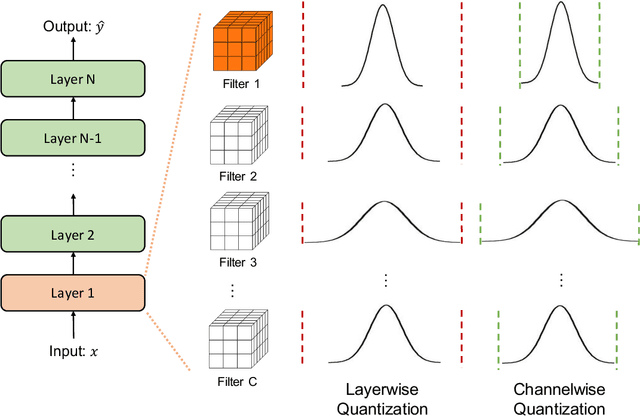
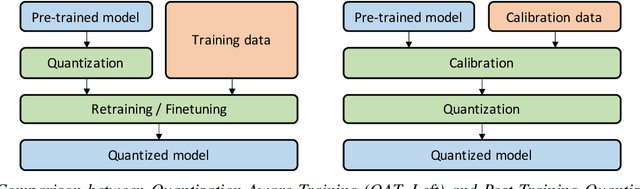
As soon as abstract mathematical computations were adapted to computation on digital computers, the problem of efficient representation, manipulation, and communication of the numerical values in those computations arose. Strongly related to the problem of numerical representation is the problem of quantization: in what manner should a set of continuous real-valued numbers be distributed over a fixed discrete set of numbers to minimize the number of bits required and also to maximize the accuracy of the attendant computations? This perennial problem of quantization is particularly relevant whenever memory and/or computational resources are severely restricted, and it has come to the forefront in recent years due to the remarkable performance of Neural Network models in computer vision, natural language processing, and related areas. Moving from floating-point representations to low-precision fixed integer values represented in four bits or less holds the potential to reduce the memory footprint and latency by a factor of 16x; and, in fact, reductions of 4x to 8x are often realized in practice in these applications. Thus, it is not surprising that quantization has emerged recently as an important and very active sub-area of research in the efficient implementation of computations associated with Neural Networks. In this article, we survey approaches to the problem of quantizing the numerical values in deep Neural Network computations, covering the advantages/disadvantages of current methods. With this survey and its organization, we hope to have presented a useful snapshot of the current research in quantization for Neural Networks and to have given an intelligent organization to ease the evaluation of future research in this area.
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Mar 25, 2021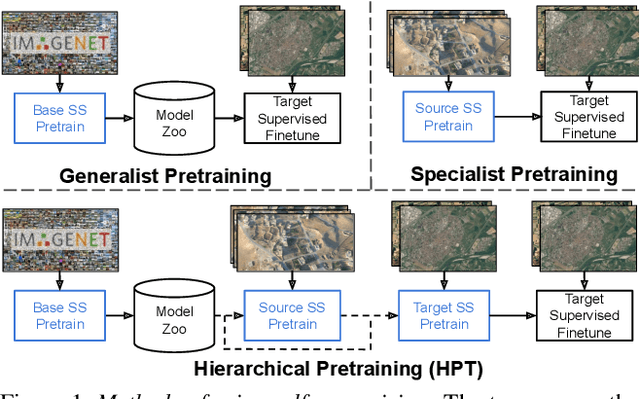
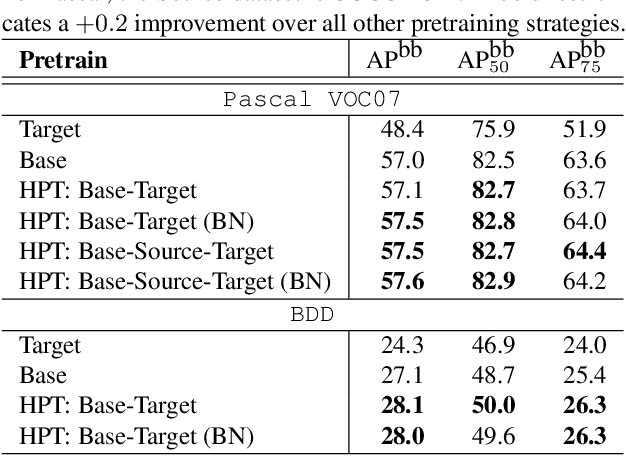
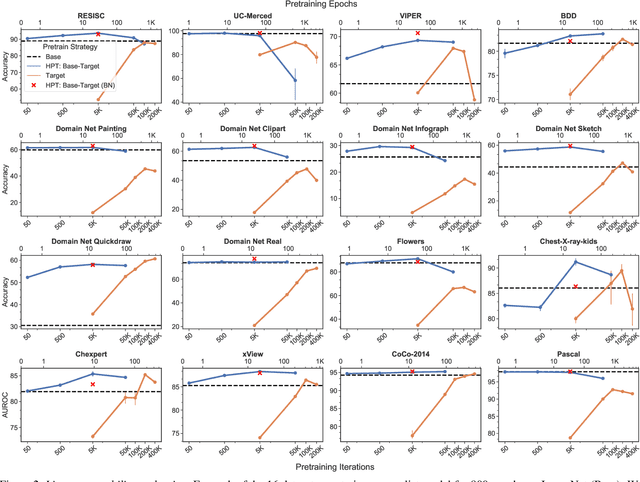
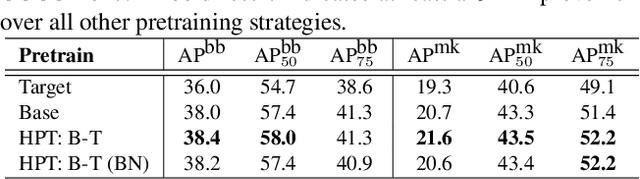
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.
You Only Group Once: Efficient Point-Cloud Processing with Token Representation and Relation Inference Module
Mar 24, 2021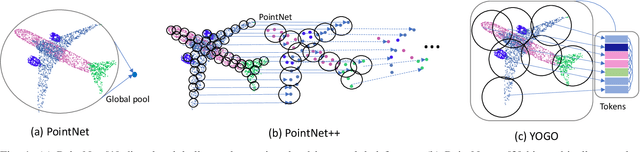
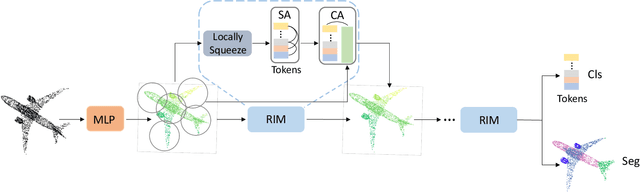
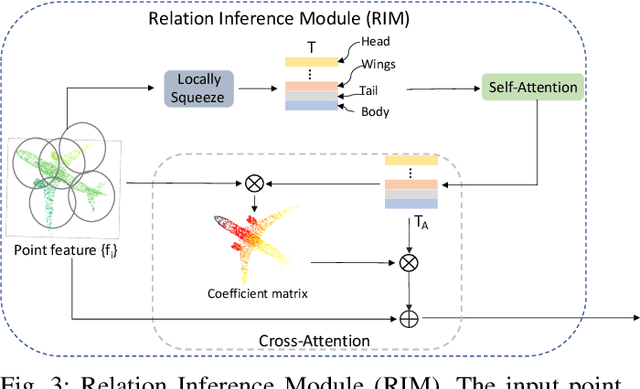
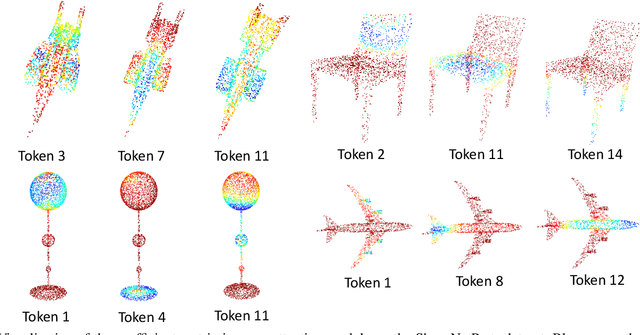
3D point-cloud-based perception is a challenging but crucial computer vision task. A point-cloud consists of a sparse, unstructured, and unordered set of points. To understand a point-cloud, previous point-based methods, such as PointNet++, extract visual features through hierarchically aggregation of local features. However, such methods have several critical limitations: 1) Such methods require several sampling and grouping operations, which slow down the inference speed. 2) Such methods spend an equal amount of computation on each points in a point-cloud, though many of points are redundant. 3) Such methods aggregate local features together through downsampling, which leads to information loss and hurts the perception performance. To overcome these challenges, we propose a novel, simple, and elegant deep learning model called YOGO (You Only Group Once). Compared with previous methods, YOGO only needs to sample and group a point-cloud once, so it is very efficient. Instead of operating on points, YOGO operates on a small number of tokens, each of which summarizes the point features in a sub-region. This allows us to avoid computing on the redundant points and thus boosts efficiency.Moreover, YOGO preserves point-wise features by projecting token features to point features although the computation is performed on tokens. This avoids information loss and can improve point-wise perception performance. We conduct thorough experiments to demonstrate that YOGO achieves at least 3.0x speedup over point-based baselines while delivering competitive classification and segmentation performance on the ModelNet, ShapeNetParts and S3DIS datasets.
Region Similarity Representation Learning
Mar 24, 2021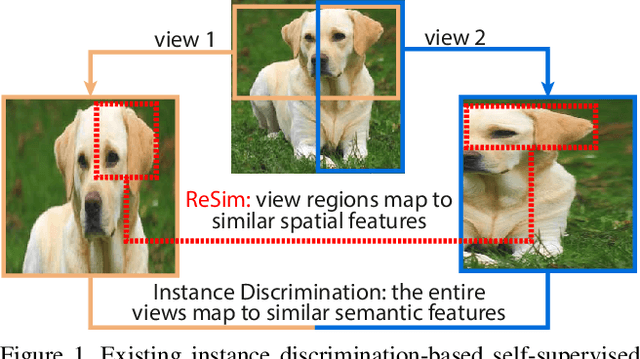
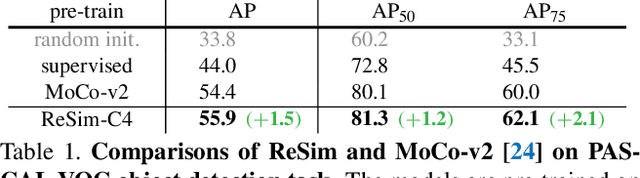
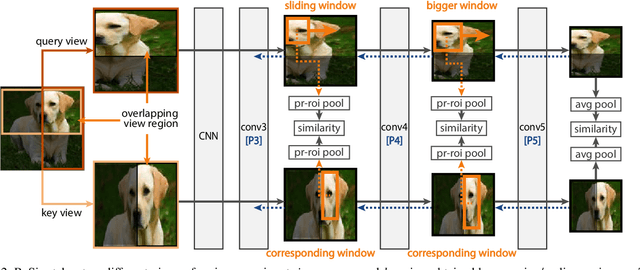
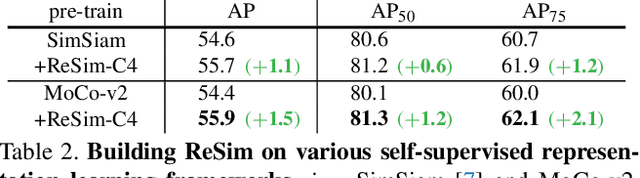
We present Region Similarity Representation Learning (ReSim), a new approach to self-supervised representation learning for localization-based tasks such as object detection and segmentation. While existing work has largely focused on solely learning global representations for an entire image, ReSim learns both regional representations for localization as well as semantic image-level representations. ReSim operates by sliding a fixed-sized window across the overlapping area between two views (e.g., image crops), aligning these areas with their corresponding convolutional feature map regions, and then maximizing the feature similarity across views. As a result, ReSim learns spatially and semantically consistent feature representation throughout the convolutional feature maps of a neural network. A shift or scale of an image region, e.g., a shift or scale of an object, has a corresponding change in the feature maps; this allows downstream tasks to leverage these representations for localization. Through object detection, instance segmentation, and dense pose estimation experiments, we illustrate how ReSim learns representations which significantly improve the localization and classification performance compared to a competitive MoCo-v2 baseline: $+2.7$ AP$^{\text{bb}}_{75}$ VOC, $+1.1$ AP$^{\text{bb}}_{75}$ COCO, and $+1.9$ AP$^{\text{mk}}$ Cityscapes. Code and pre-trained models are released at: \url{https://github.com/Tete-Xiao/ReSim}
Improving Context-Based Meta-Reinforcement Learning with Self-Supervised Trajectory Contrastive Learning
Mar 10, 2021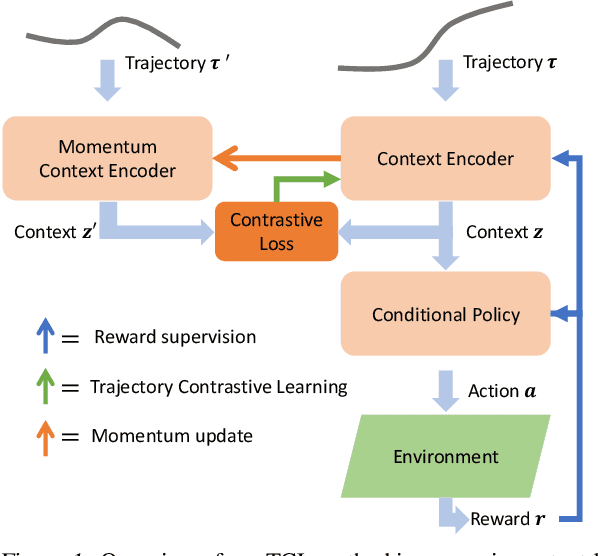
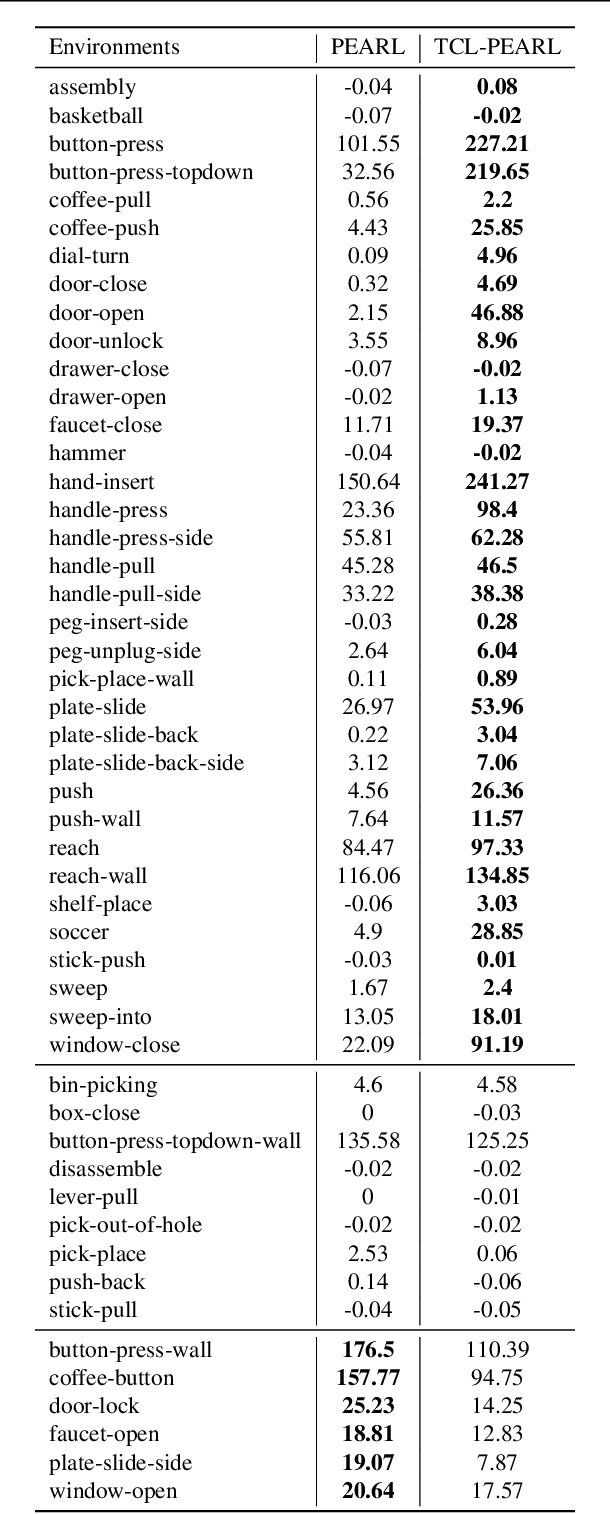
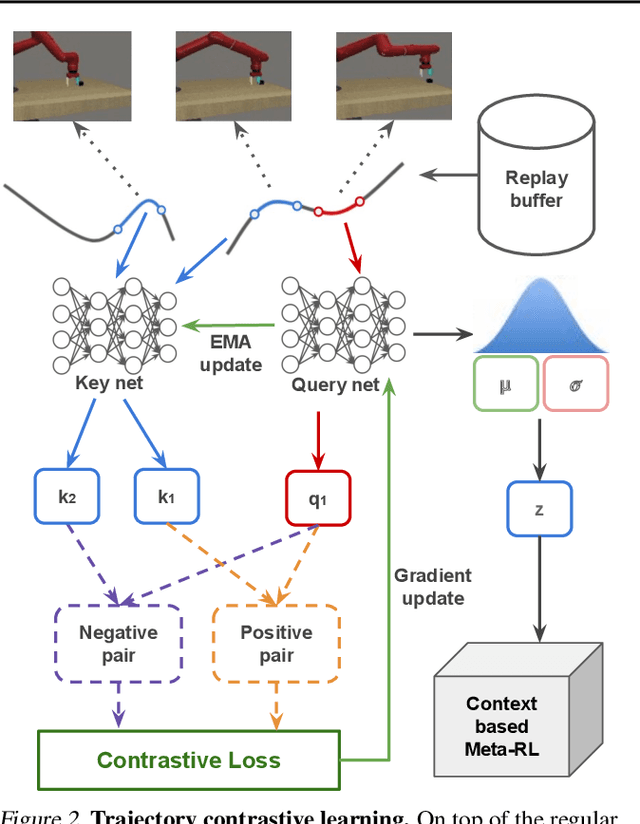

Meta-reinforcement learning typically requires orders of magnitude more samples than single task reinforcement learning methods. This is because meta-training needs to deal with more diverse distributions and train extra components such as context encoders. To address this, we propose a novel self-supervised learning task, which we named Trajectory Contrastive Learning (TCL), to improve meta-training. TCL adopts contrastive learning and trains a context encoder to predict whether two transition windows are sampled from the same trajectory. TCL leverages the natural hierarchical structure of context-based meta-RL and makes minimal assumptions, allowing it to be generally applicable to context-based meta-RL algorithms. It accelerates the training of context encoders and improves meta-training overall. Experiments show that TCL performs better or comparably than a strong meta-RL baseline in most of the environments on both meta-RL MuJoCo (5 of 6) and Meta-World benchmarks (44 out of 50).
I-BERT: Integer-only BERT Quantization
Feb 11, 2021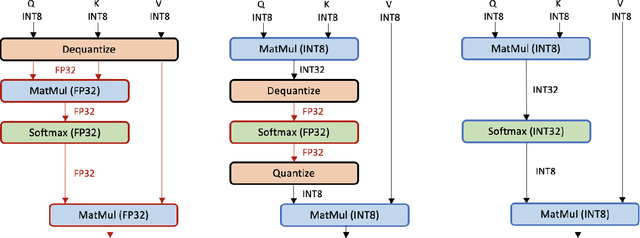
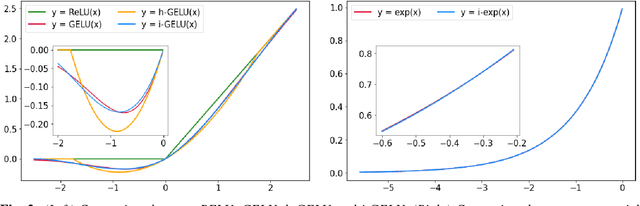
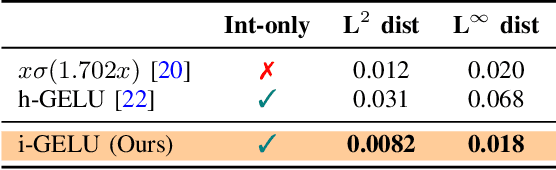
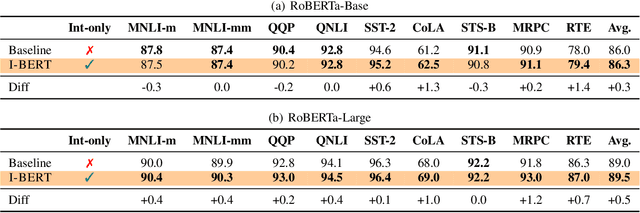
Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive for efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this, previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4 - 4.0x for INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has been open-sourced.
Hessian-Aware Pruning and Optimal Neural Implant
Feb 06, 2021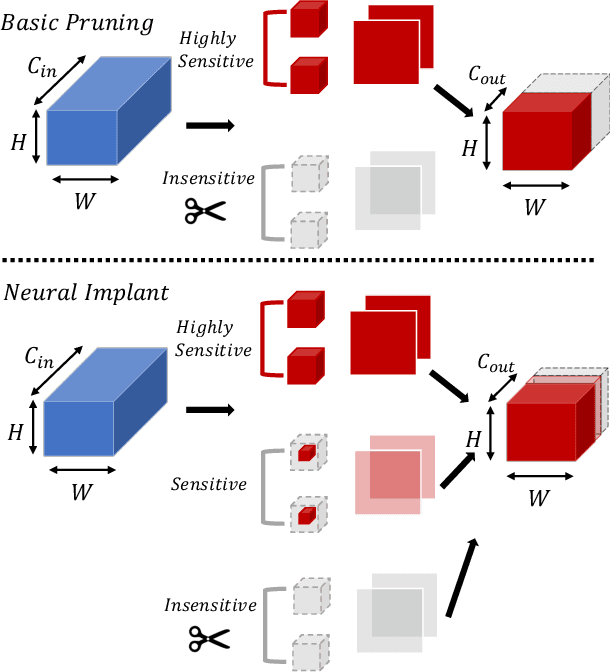
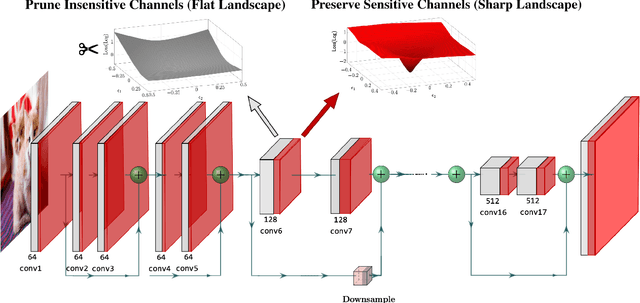
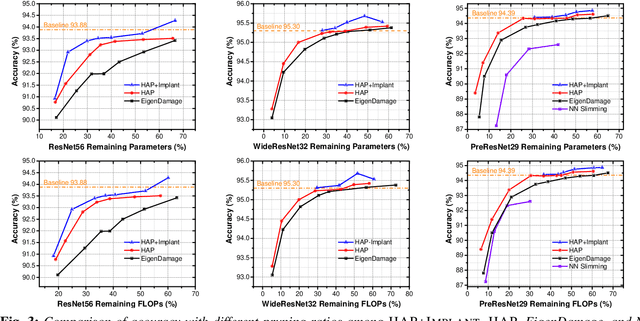
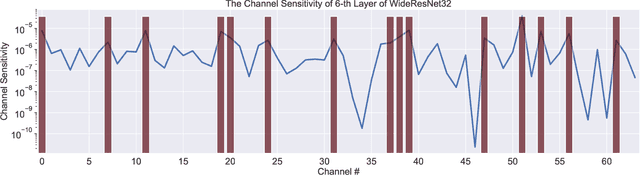
Pruning is an effective method to reduce the memory footprint and FLOPs associated with neural network models. However, existing structured-pruning methods often result in significant accuracy degradation for moderate pruning levels. To address this problem, we introduce a new Hessian Aware Pruning (HAP) method coupled with a Neural Implant approach that uses second-order sensitivity as a metric for structured pruning. The basic idea is to prune insensitive components and to use a Neural Implant for moderately sensitive components, instead of completely pruning them. For the latter approach, the moderately sensitive components are replaced with with a low rank implant that is smaller and less computationally expensive than the original component. We use the relative Hessian trace to measure sensitivity, as opposed to the magnitude based sensitivity metric commonly used in the literature. We test HAP on multiple models on CIFAR-10/ImageNet, and we achieve new state-of-the-art results. Specifically, HAP achieves 94.3\% accuracy ($<0.1\%$ degradation) on PreResNet29 (CIFAR-10), with more than 70\% of parameters pruned. Moreover, for ResNet50 HAP achieves 75.1\% top-1 accuracy (0.5\% degradation) on ImageNet, after pruning more than half of the parameters. The framework has been open sourced and available online.
Reservoir Transformer
Dec 30, 2020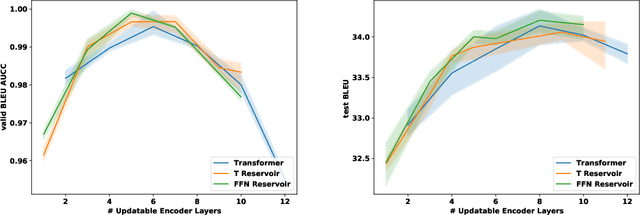
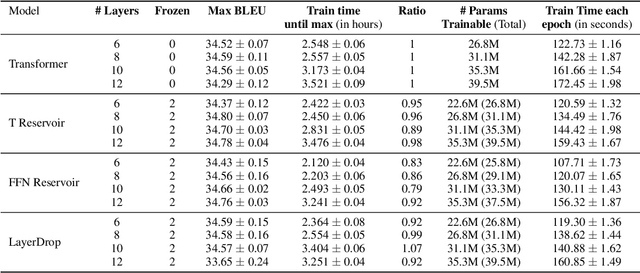
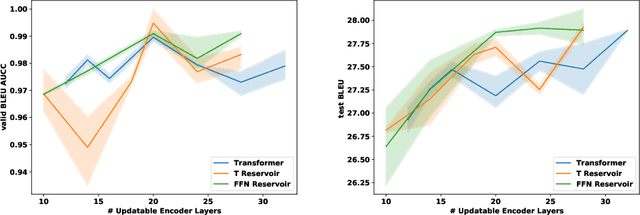
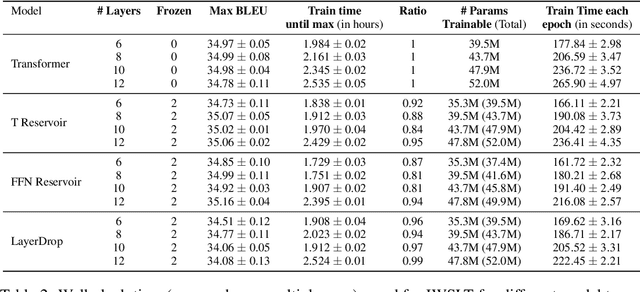
We demonstrate that transformers obtain impressive performance even when some of the layers are randomly initialized and never updated. Inspired by old and well-established ideas in machine learning, we explore a variety of non-linear "reservoir" layers interspersed with regular transformer layers, and show improvements in wall-clock compute time until convergence, as well as overall performance, on various machine translation and (masked) language modelling tasks.
BeBold: Exploration Beyond the Boundary of Explored Regions
Dec 15, 2020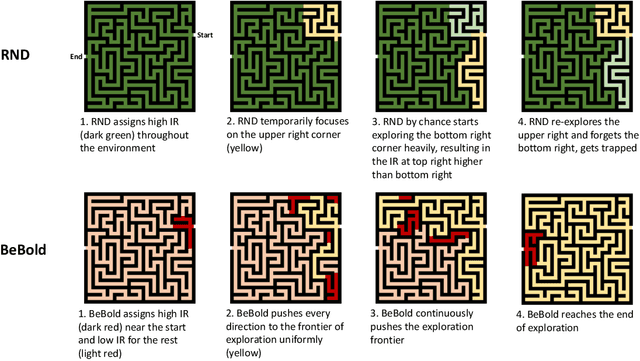
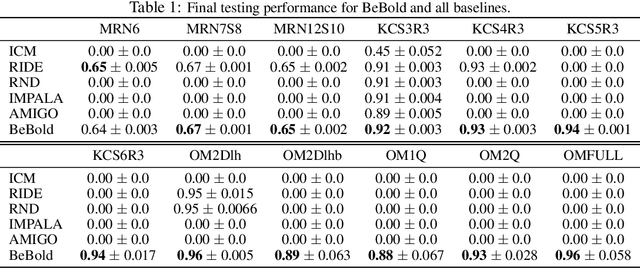
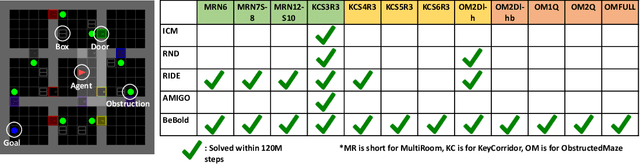

Efficient exploration under sparse rewards remains a key challenge in deep reinforcement learning. To guide exploration, previous work makes extensive use of intrinsic reward (IR). There are many heuristics for IR, including visitation counts, curiosity, and state-difference. In this paper, we analyze the pros and cons of each method and propose the regulated difference of inverse visitation counts as a simple but effective criterion for IR. The criterion helps the agent explore Beyond the Boundary of explored regions and mitigates common issues in count-based methods, such as short-sightedness and detachment. The resulting method, BeBold, solves the 12 most challenging procedurally-generated tasks in MiniGrid with just 120M environment steps, without any curriculum learning. In comparison, the previous SoTA only solves 50% of the tasks. BeBold also achieves SoTA on multiple tasks in NetHack, a popular rogue-like game that contains more challenging procedurally-generated environments.
Cross-Domain Sentiment Classification with In-Domain Contrastive Learning
Dec 05, 2020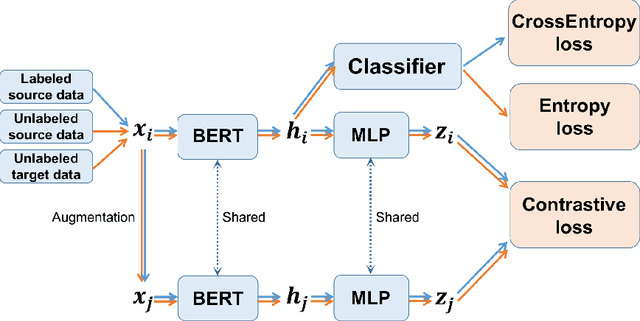
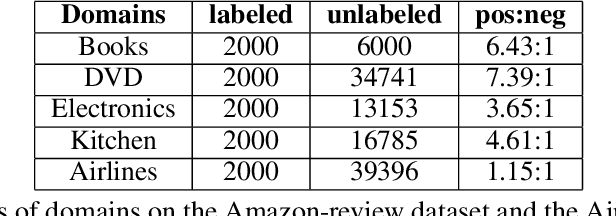

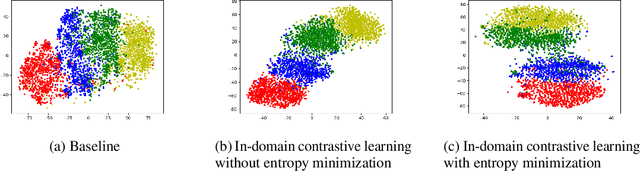
Contrastive learning (CL) has been successful as a powerful representation learning method. In this paper, we propose a contrastive learning framework for cross-domain sentiment classification. We aim to induce domain invariant optimal classifiers rather than distribution matching. To this end, we introduce in-domain contrastive learning and entropy minimization. Also, we find through ablation studies that these two techniques behaviour differently in case of large label distribution shift and conclude that the best practice is to choose one of them adaptively according to label distribution shift. The new state-of-the-art results our model achieves on standard benchmarks show the efficacy of the proposed method.