 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Based Bayesian Experimental Design for Non-Differentiable Implicit Models
Mar 08, 2022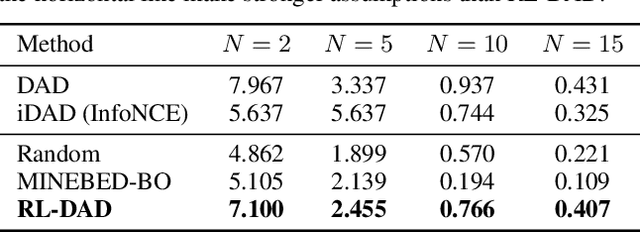
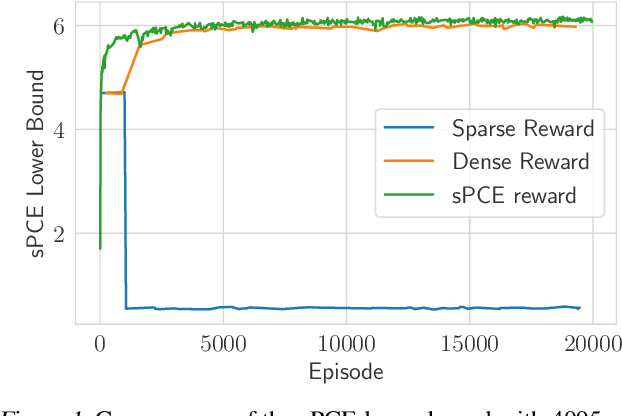
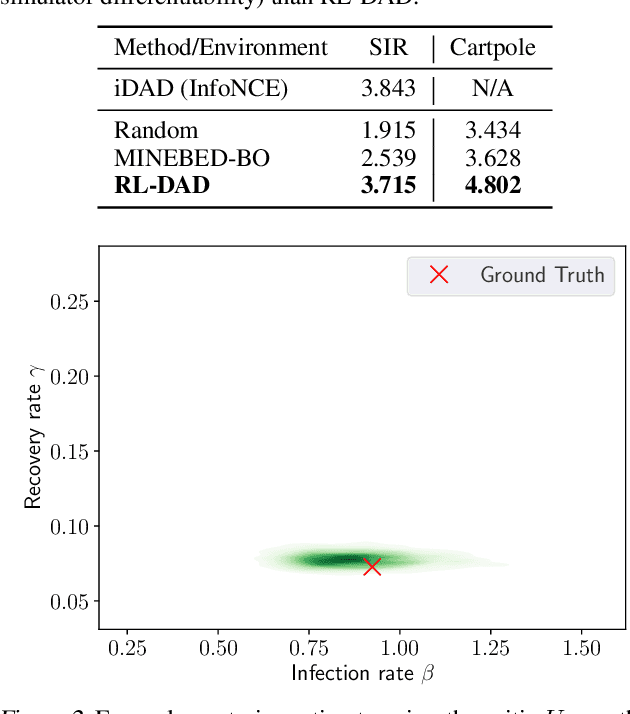
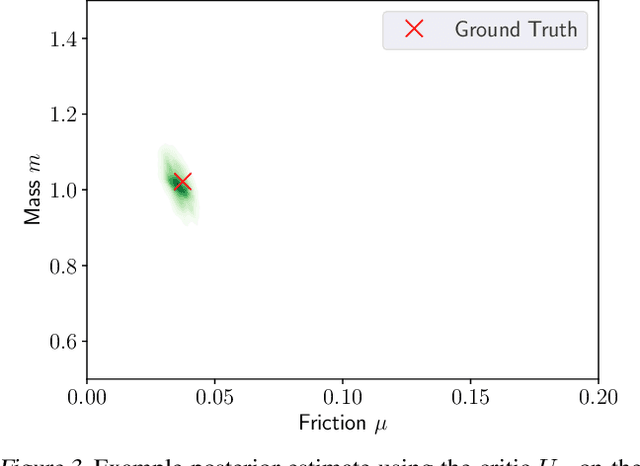
For applications in healthcare, physics, energy, robotics, and many other fields, designing maximally informative experiments is valuable, particularly when experiments are expensive, time-consuming, or pose safety hazards. While existing approaches can sequentially design experiments based on prior observation history, many of these methods do not extend to implicit models, where simulation is possible but computing the likelihood is intractable. Furthermore, they often require either significant online computation during deployment or a differentiable simulation system. We introduce Reinforcement Learning for Deep Adaptive Design (RL-DAD), a method for simulation-based optimal experimental design for non-differentiable implicit models. RL-DAD extends prior work in policy-based Bayesian Optimal Experimental Design (BOED) by reformulating it as a Markov Decision Process with a reward function based on likelihood-free information lower bounds, which is used to learn a policy via deep reinforcement learning. The learned design policy maps prior histories to experiment designs offline and can be quickly deployed during online execution. We evaluate RL-DAD and find that it performs competitively with baselines on three benchmarks.
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Mar 03, 2022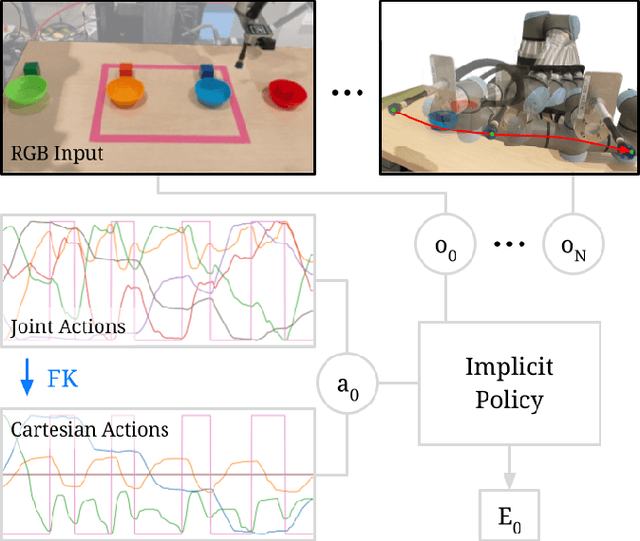
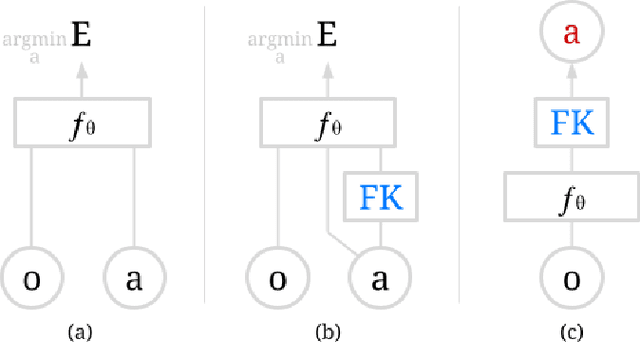
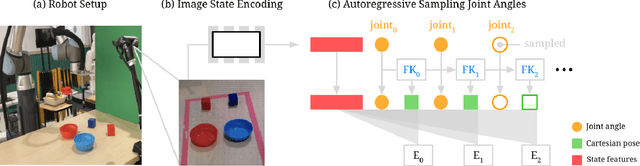
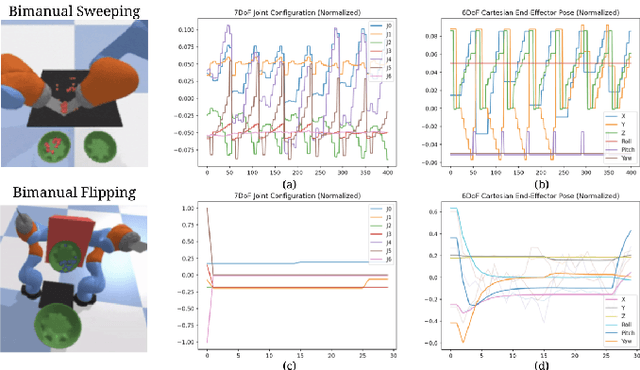
Action representation is an important yet often overlooked aspect in end-to-end robot learning with deep networks. Choosing one action space over another (e.g. target joint positions, or Cartesian end-effector poses) can result in surprisingly stark performance differences between various downstream tasks -- and as a result, considerable research has been devoted to finding the right action space for a given application. However, in this work, we instead investigate how our models can discover and learn for themselves which action space to use. Leveraging recent work on implicit behavioral cloning, which takes both observations and actions as input, we demonstrate that it is possible to present the same action in multiple different spaces to the same policy -- allowing it to learn inductive patterns from each space. Specifically, we study the benefits of combining Cartesian and joint action spaces in the context of learning manipulation skills. To this end, we present Implicit Kinematic Policies (IKP), which incorporates the kinematic chain as a differentiable module within the deep network. Quantitative experiments across several simulated continuous control tasks -- from scooping piles of small objects, to lifting boxes with elbows, to precise block insertion with miscalibrated robots -- suggest IKP not only learns complex prehensile and non-prehensile manipulation from pixels better than baseline alternatives, but also can learn to compensate for small joint encoder offset errors. Finally, we also run qualitative experiments on a real UR5e to demonstrate the feasibility of our algorithm on a physical robotic system with real data. See https://tinyurl.com/4wz3nf86 for code and supplementary material.
Mechanical Search on Shelves using a Novel "Bluction" Tool
Jan 22, 2022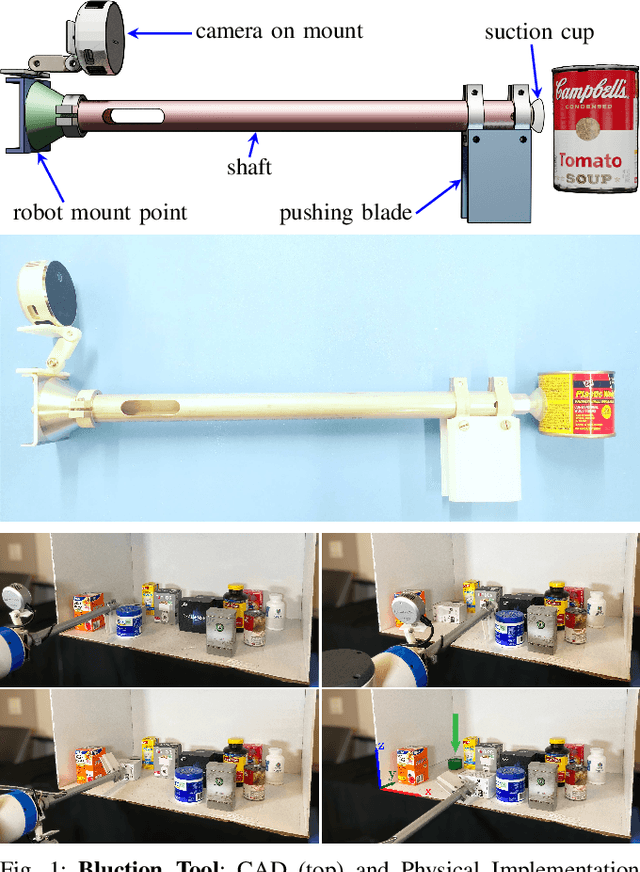
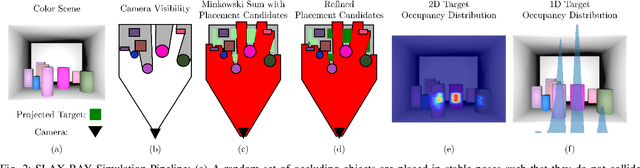

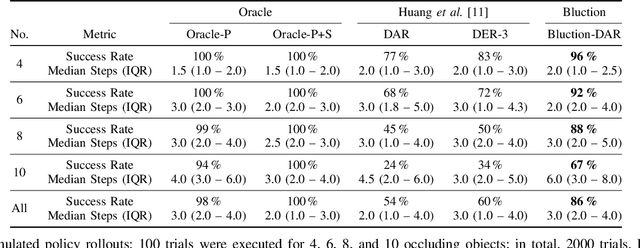
Shelves are common in homes, warehouses, and commercial settings due to their storage efficiency. However, this efficiency comes at the cost of reduced visibility and accessibility. When looking from a side (lateral) view of a shelf, most objects will be fully occluded, resulting in a constrained lateral-access mechanical search problem. To address this problem, we introduce: (1) a novel bluction tool, which combines a thin pushing blade and suction cup gripper, (2) an improved LAX-RAY simulation pipeline and perception model that combines ray-casting with 2D Minkowski sums to efficiently generate target occupancy distributions, and (3) a novel SLAX-RAY search policy, which optimally reduces target object distribution support area using the bluction tool. Experimental data from 2000 simulated shelf trials and 18 trials with a physical Fetch robot equipped with the bluction tool suggest that using suction grasping actions improves the success rate over the highest performing push-only policy by 26% in simulation and 67% in physical environments.
Learning to Localize, Grasp, and Hand Over Unmodified Surgical Needles
Dec 08, 2021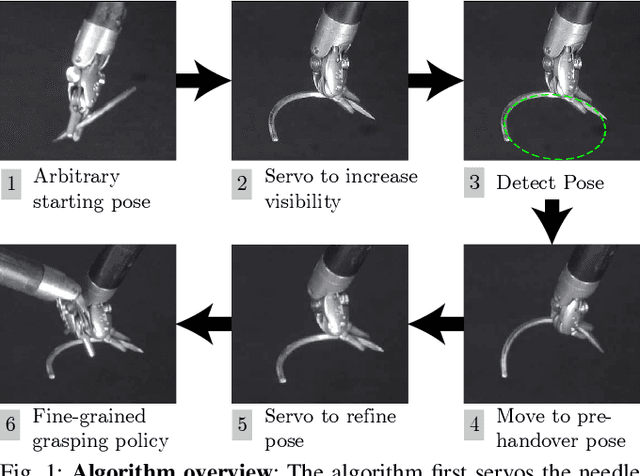
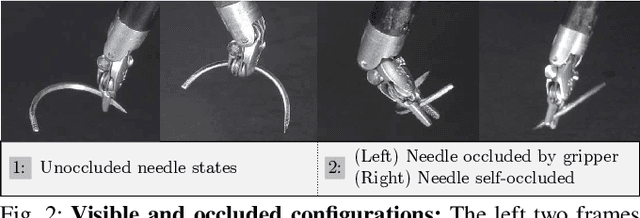
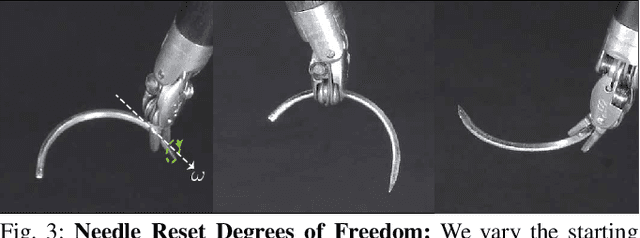

Robotic Surgical Assistants (RSAs) are commonly used to perform minimally invasive surgeries by expert surgeons. However, long procedures filled with tedious and repetitive tasks such as suturing can lead to surgeon fatigue, motivating the automation of suturing. As visual tracking of a thin reflective needle is extremely challenging, prior work has modified the needle with nonreflective contrasting paint. As a step towards automation of a suturing subtask without modifying the needle, we propose HOUSTON: Handoff of Unmodified, Surgical, Tool-Obstructed Needles, a problem and algorithm that uses a learned active sensing policy with a stereo camera to localize and align the needle into a visible and accessible pose for the other arm. To compensate for robot positioning and needle perception errors, the algorithm then executes a high-precision grasping motion that uses multiple cameras. In physical experiments using the da Vinci Research Kit (dVRK), HOUSTON successfully passes unmodified surgical needles with a success rate of 96.7% and is able to perform handover sequentially between the arms 32.4 times on average before failure. On needles unseen in training, HOUSTON achieves a success rate of 75 - 92.9%. To our knowledge, this work is the first to study handover of unmodified surgical needles. See https://tinyurl.com/houston-surgery for additional materials.
MESA: Offline Meta-RL for Safe Adaptation and Fault Tolerance
Dec 07, 2021
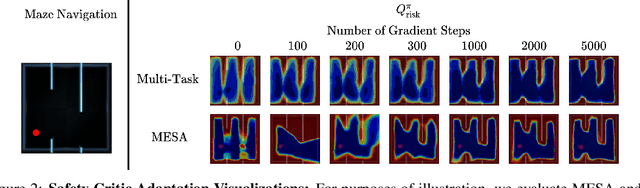

Safe exploration is critical for using reinforcement learning (RL) in risk-sensitive environments. Recent work learns risk measures which measure the probability of violating constraints, which can then be used to enable safety. However, learning such risk measures requires significant interaction with the environment, resulting in excessive constraint violations during learning. Furthermore, these measures are not easily transferable to new environments. We cast safe exploration as an offline meta-RL problem, where the objective is to leverage examples of safe and unsafe behavior across a range of environments to quickly adapt learned risk measures to a new environment with previously unseen dynamics. We then propose MEta-learning for Safe Adaptation (MESA), an approach for meta-learning a risk measure for safe RL. Simulation experiments across 5 continuous control domains suggest that MESA can leverage offline data from a range of different environments to reduce constraint violations in unseen environments by up to a factor of 2 while maintaining task performance. See https://tinyurl.com/safe-meta-rl for code and supplementary material.
LEGS: Learning Efficient Grasp Sets for Exploratory Grasping
Nov 29, 2021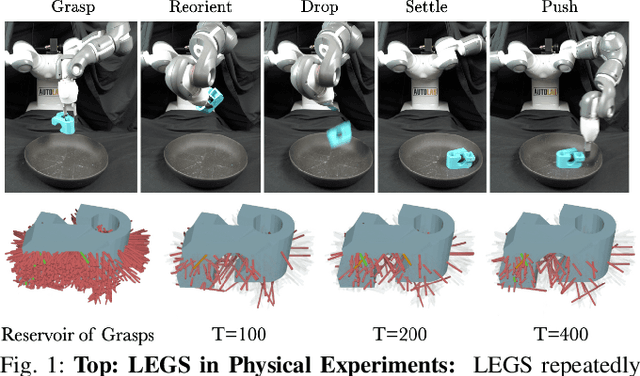
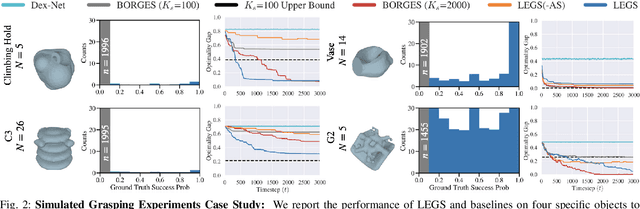
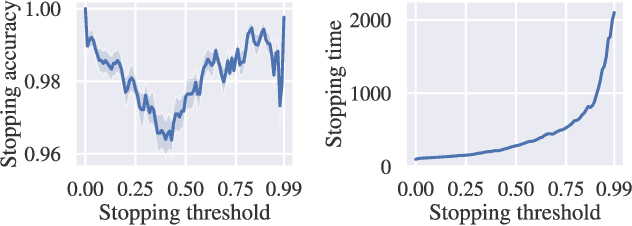
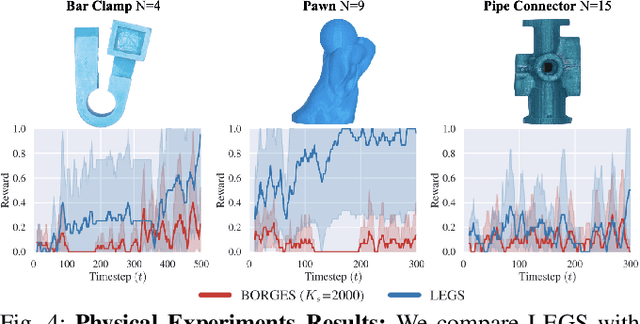
Previous work defined Exploratory Grasping, where a robot iteratively grasps and drops an unknown complex polyhedral object to discover a set of robust grasps for each recognizably distinct stable pose of the object. Recent work used a multi-armed bandit model with a small set of candidate grasps per pose; however, for objects with few successful grasps, this set may not include the most robust grasp. We present Learned Efficient Grasp Sets (LEGS), an algorithm that can efficiently explore thousands of possible grasps by constructing small active sets of promising grasps and uses learned confidence bounds to determine when, with high confidence, it can stop exploring the object. Experiments suggest that LEGS can identify a high-quality grasp more efficiently than prior algorithms which do not learn active sets. In simulation experiments, we measure the optimality gap between the success probability of the best grasp identified by LEGS and baselines and that of the true most robust grasp. After 3000 steps of exploration, LEGS outperforms baseline algorithms on 10 of the 14 Dex-Net Adversarial objects and 25 of the 39 EGAD! objects. We then develop a self-supervised grasping system, where the robot explores grasps with minimal human intervention. Physical experiments across 3 objects suggest that LEGS converges to high-performing grasps significantly faster than baselines. See \url{https://sites.google.com/view/legs-exp-grasping} for supplemental material and videos.
AlphaGarden: Learning to Autonomously Tend a Polyculture Garden
Nov 11, 2021
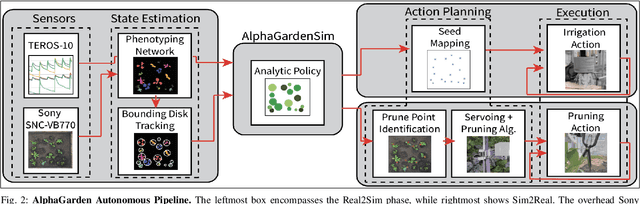

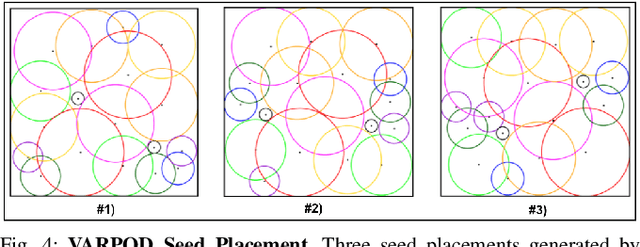
This paper presents AlphaGarden: an autonomous polyculture garden that prunes and irrigates living plants in a 1.5m x 3.0m physical testbed. AlphaGarden uses an overhead camera and sensors to track the plant distribution and soil moisture. We model individual plant growth and interplant dynamics to train a policy that chooses actions to maximize leaf coverage and diversity. For autonomous pruning, AlphaGarden uses two custom-designed pruning tools and a trained neural network to detect prune points. We present results for four 60-day garden cycles. Results suggest AlphaGarden can autonomously achieve 0.96 normalized diversity with pruning shears while maintaining an average canopy coverage of 0.86 during the peak of the cycle. Code, datasets, and supplemental material can be found at https://github.com/BerkeleyAutomation/AlphaGarden.
Planar Robot Casting with Real2Sim2Real Self-Supervised Learning
Nov 08, 2021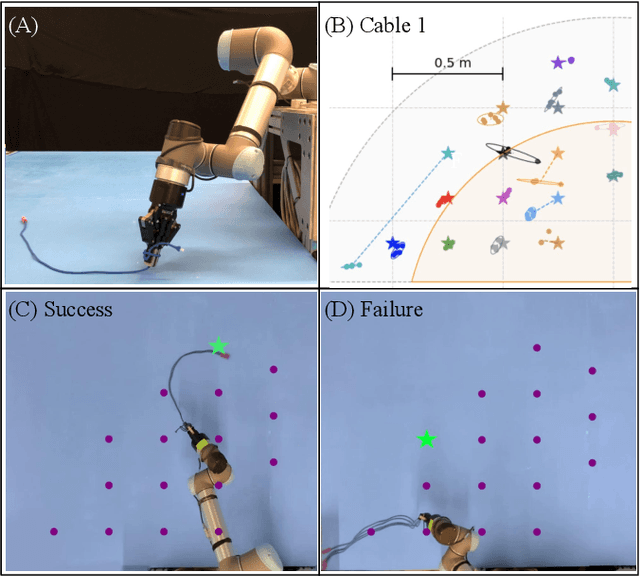
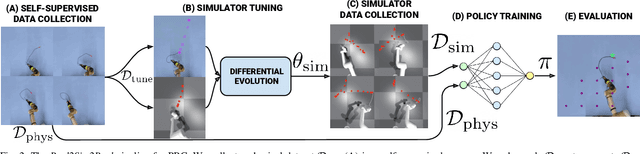
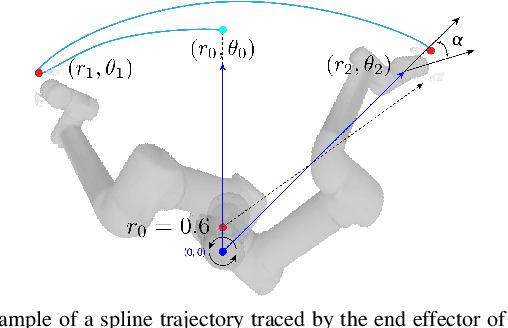

Manipulation of deformable objects using a single parameterized dynamic action can be useful for tasks such as fly fishing, lofting a blanket, and playing shuffleboard. Such tasks take as input a desired final state and output one parameterized open-loop dynamic robot action which produces a trajectory toward the final state. This is especially challenging for long-horizon trajectories with complex dynamics involving friction. This paper explores the task of Planar Robot Casting (PRC): where one planar motion of a robot wrist holding one end of a cable causes the other end to slide across the plane toward a desired target. PRC allows the cable to reach points beyond the robot's workspace and has applications for cable management in homes, warehouses, and factories. To efficiently learn a PRC policy for a given cable, we propose Real2Sim2Real, a self-supervised framework that automatically collects physical trajectory examples to tune parameters of a dynamics simulator using Differential Evolution, generates many simulated examples, and then learns a policy using a weighted combination of simulated and physical data. We evaluate Real2Sim2Real with three simulators, Isaac Gym-segmented, Isaac Gym-hybrid, and PyBullet, two function approximators, Gaussian Processes and Neural Networks (NNs), and three cables with differing stiffness, torsion, and friction. Results on 16 held-out test targets for each cable suggest that the NN PRC policies using Isaac Gym-segmented attain median error distance (as % of cable length) ranging from 8% to 14%, outperforming baselines and policies trained on only real or only simulated examples. Code, data, and videos are available at https://tinyurl.com/robotcast.
Simulation of Parallel-Jaw Grasping using Incremental Potential Contact Models
Nov 02, 2021



Soft compliant jaw tips are almost universally used with parallel-jaw robot grippers due to their ability to increase contact area and friction between the jaws and the object to be manipulated. However, interactions between the compliant surfaces and rigid objects are notoriously difficult to model. We introduce IPC-GraspSim, a novel simulator using Incremental Potential Contact (IPC) - a deformation model developed in 2020 for computer graphics - that models both the dynamics and the deformation of compliant jaw tips during grasping. IPC-GraspSim is evaluated using a set of 2,000 physical grasps across 16 adversarial objects where standard analytic models perform poorly. In comparison to both analytic quasistatic contact models (soft point contact, REACH, 6DFC) and dynamic grasp simulators (Isaac Gym with FleX backend), results suggest that IPC-GraspSim more accurately models real-world grasps, increasing F1 score by 9%. All data, code, videos, and supplementary material are available at https://sites.google.com/berkeley.edu/ipcgraspsim.
GOMP-FIT: Grasp-Optimized Motion Planning for Fast Inertial Transport
Oct 28, 2021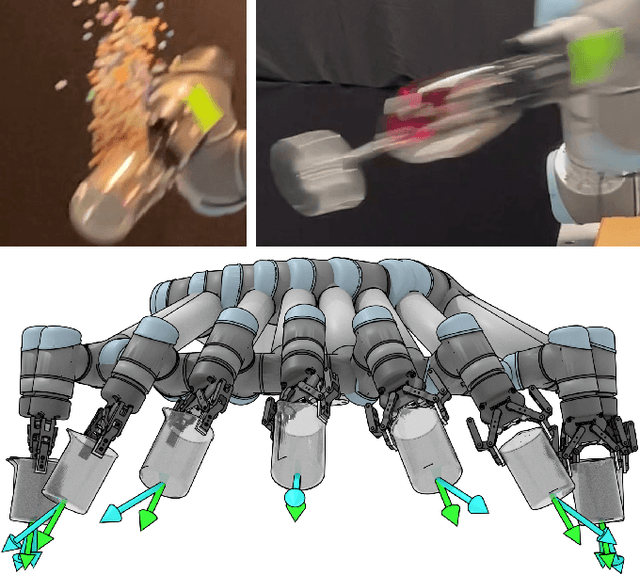
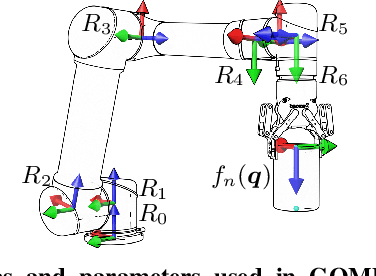


High-speed motions in pick-and-place operations are critical to making robots cost-effective in many automation scenarios, from warehouses and manufacturing to hospitals and homes. However, motions can be too fast -- such as when the object being transported has an open-top, is fragile, or both. One way to avoid spills or damage, is to move the arm slowly. We propose Grasp-Optimized Motion Planning for Fast Inertial Transport (GOMP-FIT), a time-optimizing motion planner based on our prior work, that includes constraints based on accelerations at the robot end-effector. With GOMP-FIT, a robot can perform high-speed motions that avoid obstacles and use inertial forces to its advantage. In experiments transporting open-top containers with varying tilt tolerances, whereas GOMP computes sub-second motions that spill up to 90% of the contents during transport, GOMP-FIT generates motions that spill 0% of contents while being slowed by as little as 0% when there are few obstacles, 30% when there are high obstacles and 45-degree tolerances, and 50% when there 15-degree tolerances and few obstacles.