 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adaptive Parallel Execution for Efficient Code Localization
Jan 27, 2026Code localization constitutes a key bottleneck in automated software development pipelines. While concurrent tool execution can enhance discovery speed, current agents demonstrate a 34.9\% redundant invocation rate, which negates parallelism benefits. We propose \textbf{FuseSearch}, reformulating parallel code localization as a \textbf{joint quality-efficiency optimization} task. Through defining \textbf{tool efficiency} -- the ratio of unique information gain to invocation count -- we utilize a two-phase SFT and RL training approach for learning adaptive parallel strategies. Different from fixed-breadth approaches, FuseSearch dynamically modulates search breadth according to task context, evolving from exploration phases to refinement stages. Evaluated on SWE-bench Verified, FuseSearch-4B achieves SOTA-level performance (84.7\% file-level and 56.4\% function-level $F_1$ scores) with 93.6\% speedup, utilizing 67.7\% fewer turns and 68.9\% fewer tokens. Results indicate that efficiency-aware training naturally improves quality through eliminating noisy redundant signals, enabling high-performance cost-effective localization agents.
Vision-Language Reasoning for Geolocalization: A Reinforcement Learning Approach
Jan 05, 2026Recent advances in vision-language models have opened up new possibilities for reasoning-driven image geolocalization. However, existing approaches often rely on synthetic reasoning annotations or external image retrieval, which can limit interpretability and generalizability. In this paper, we present Geo-R, a retrieval-free framework that uncovers structured reasoning paths from existing ground-truth coordinates and optimizes geolocation accuracy via reinforcement learning. We propose the Chain of Region, a rule-based hierarchical reasoning paradigm that generates precise, interpretable supervision by mapping GPS coordinates to geographic entities (e.g., country, province, city) without relying on model-generated or synthetic labels. Building on this, we introduce a lightweight reinforcement learning strategy with coordinate-aligned rewards based on Haversine distance, enabling the model to refine predictions through spatially meaningful feedback. Our approach bridges structured geographic reasoning with direct spatial supervision, yielding improved localization accuracy, stronger generalization, and more transparent inference. Experimental results across multiple benchmarks confirm the effectiveness of Geo-R, establishing a new retrieval-free paradigm for scalable and interpretable image geolocalization. To facilitate further research and ensure reproducibility, both the model and code will be made publicly available.
LLM-MemCluster: Empowering Large Language Models with Dynamic Memory for Text Clustering
Nov 19, 2025Large Language Models (LLMs) are reshaping unsupervised learning by offering an unprecedented ability to perform text clustering based on their deep semantic understanding. However, their direct application is fundamentally limited by a lack of stateful memory for iterative refinement and the difficulty of managing cluster granularity. As a result, existing methods often rely on complex pipelines with external modules, sacrificing a truly end-to-end approach. We introduce LLM-MemCluster, a novel framework that reconceptualizes clustering as a fully LLM-native task. It leverages a Dynamic Memory to instill state awareness and a Dual-Prompt Strategy to enable the model to reason about and determine the number of clusters. Evaluated on several benchmark datasets, our tuning-free framework significantly and consistently outperforms strong baselines. LLM-MemCluster presents an effective, interpretable, and truly end-to-end paradigm for LLM-based text clustering.
Graph Out-of-Distribution Detection via Test-Time Calibration with Dual Dynamic Dictionaries
Nov 17, 2025A key challenge in graph out-of-distribution (OOD) detection lies in the absence of ground-truth OOD samples during training. Existing methods are typically optimized to capture features within the in-distribution (ID) data and calculate OOD scores, which often limits pre-trained models from representing distributional boundaries, leading to unreliable OOD detection. Moreover, the latent structure of graph data is often governed by multiple underlying factors, which remains less explored. To address these challenges, we propose a novel test-time graph OOD detection method, termed BaCa, that calibrates OOD scores using dual dynamically updated dictionaries without requiring fine-tuning the pre-trained model. Specifically, BaCa estimates graphons and applies a mix-up strategy solely with test samples to generate diverse boundary-aware discriminative topologies, eliminating the need for exposing auxiliary datasets as outliers. We construct dual dynamic dictionaries via priority queues and attention mechanisms to adaptively capture latent ID and OOD representations, which are then utilized for boundary-aware OOD score calibration. To the best of our knowledge, extensive experiments on real-world datasets show that BaCa significantly outperforms existing state-of-the-art methods in OOD detection.
Spectral Bias Mitigation via xLSTM-PINN: Memory-Gated Representation Refinement for Physics-Informed Learning
Nov 16, 2025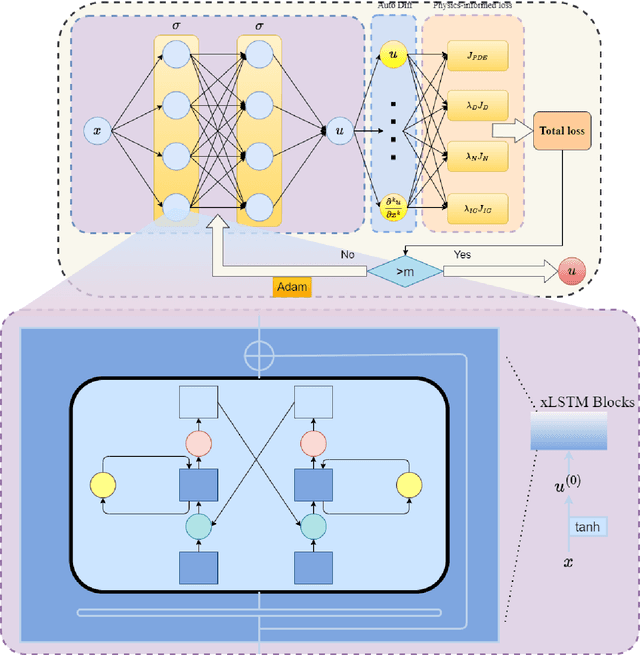

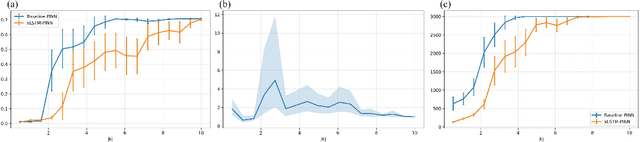

Physics-informed learning for PDEs is surging across scientific computing and industrial simulation, yet prevailing methods face spectral bias, residual-data imbalance, and weak extrapolation. We introduce a representation-level spectral remodeling xLSTM-PINN that combines gated-memory multiscale feature extraction with adaptive residual-data weighting to curb spectral bias and strengthen extrapolation. Across four benchmarks, we integrate gated cross-scale memory, a staged frequency curriculum, and adaptive residual reweighting, and verify with analytic references and extrapolation tests, achieving markedly lower spectral error and RMSE and a broader stable learning-rate window. Frequency-domain benchmarks show raised high-frequency kernel weights and a right-shifted resolvable bandwidth, shorter high-k error decay and time-to-threshold, and narrower error bands with lower MSE, RMSE, MAE, and MaxAE. Compared with the baseline PINN, we reduce MSE, RMSE, MAE, and MaxAE across all four benchmarks and deliver cleaner boundary transitions with attenuated high-frequency ripples in both frequency and field maps. This work suppresses spectral bias, widens the resolvable band and shortens the high-k time-to-threshold under the same budget, and without altering AD or physics losses improves accuracy, reproducibility, and transferability.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
ALMGuard: Safety Shortcuts and Where to Find Them as Guardrails for Audio-Language Models
Oct 30, 2025Recent advances in Audio-Language Models (ALMs) have significantly improved multimodal understanding capabilities. However, the introduction of the audio modality also brings new and unique vulnerability vectors. Previous studies have proposed jailbreak attacks that specifically target ALMs, revealing that defenses directly transferred from traditional audio adversarial attacks or text-based Large Language Model (LLM) jailbreaks are largely ineffective against these ALM-specific threats. To address this issue, we propose ALMGuard, the first defense framework tailored to ALMs. Based on the assumption that safety-aligned shortcuts naturally exist in ALMs, we design a method to identify universal Shortcut Activation Perturbations (SAPs) that serve as triggers that activate the safety shortcuts to safeguard ALMs at inference time. To better sift out effective triggers while preserving the model's utility on benign tasks, we further propose Mel-Gradient Sparse Mask (M-GSM), which restricts perturbations to Mel-frequency bins that are sensitive to jailbreaks but insensitive to speech understanding. Both theoretical analyses and empirical results demonstrate the robustness of our method against both seen and unseen attacks. Overall, \MethodName reduces the average success rate of advanced ALM-specific jailbreak attacks to 4.6% across four models, while maintaining comparable utility on benign benchmarks, establishing it as the new state of the art. Our code and data are available at https://github.com/WeifeiJin/ALMGuard.
Exploring Semantic-constrained Adversarial Example with Instruction Uncertainty Reduction
Oct 27, 2025



Recently, semantically constrained adversarial examples (SemanticAE), which are directly generated from natural language instructions, have become a promising avenue for future research due to their flexible attacking forms. To generate SemanticAEs, current methods fall short of satisfactory attacking ability as the key underlying factors of semantic uncertainty in human instructions, such as referring diversity, descriptive incompleteness, and boundary ambiguity, have not been fully investigated. To tackle the issues, this paper develops a multi-dimensional instruction uncertainty reduction (InSUR) framework to generate more satisfactory SemanticAE, i.e., transferable, adaptive, and effective. Specifically, in the dimension of the sampling method, we propose the residual-driven attacking direction stabilization to alleviate the unstable adversarial optimization caused by the diversity of language references. By coarsely predicting the language-guided sampling process, the optimization process will be stabilized by the designed ResAdv-DDIM sampler, therefore releasing the transferable and robust adversarial capability of multi-step diffusion models. In task modeling, we propose the context-encoded attacking scenario constraint to supplement the missing knowledge from incomplete human instructions. Guidance masking and renderer integration are proposed to regulate the constraints of 2D/3D SemanticAE, activating stronger scenario-adapted attacks. Moreover, in the dimension of generator evaluation, we propose the semantic-abstracted attacking evaluation enhancement by clarifying the evaluation boundary, facilitating the development of more effective SemanticAE generators. Extensive experiments demonstrate the superiority of the transfer attack performance of InSUR. Moreover, we realize the reference-free generation of semantically constrained 3D adversarial examples for the first time.
Toward Robust Signed Graph Learning through Joint Input-Target Denoising
Oct 26, 2025Signed Graph Neural Networks (SGNNs) are widely adopted to analyze complex patterns in signed graphs with both positive and negative links. Given the noisy nature of real-world connections, the robustness of SGNN has also emerged as a pivotal research area. Under the supervision of empirical properties, graph structure learning has shown its robustness on signed graph representation learning, however, there remains a paucity of research investigating a robust SGNN with theoretical guidance. Inspired by the success of graph information bottleneck (GIB) in information extraction, we propose RIDGE, a novel framework for Robust sI gned graph learning through joint Denoising of Graph inputs and supervision targEts. Different from the basic GIB, we extend the GIB theory with the capability of target space denoising as the co-existence of noise in both input and target spaces. In instantiation, RIDGE effectively cleanses input data and supervision targets via a tractable objective function produced by reparameterization mechanism and variational approximation. We extensively validate our method on four prevalent signed graph datasets, and the results show that RIDGE clearly improves the robustness of popular SGNN models under various levels of noise.
Beyond a Single Perspective: Towards a Realistic Evaluation of Website Fingerprinting Attacks
Oct 16, 2025Website Fingerprinting (WF) attacks exploit patterns in encrypted traffic to infer the websites visited by users, posing a serious threat to anonymous communication systems. Although recent WF techniques achieve over 90% accuracy in controlled experimental settings, most studies remain confined to single scenarios, overlooking the complexity of real-world environments. This paper presents the first systematic and comprehensive evaluation of existing WF attacks under diverse realistic conditions, including defense mechanisms, traffic drift, multi-tab browsing, early-stage detection, open-world settings, and few-shot scenarios. Experimental results show that many WF techniques with strong performance in isolated settings degrade significantly when facing other conditions. Since real-world environments often combine multiple challenges, current WF attacks are difficult to apply directly in practice. This study highlights the limitations of WF attacks and introduces a multidimensional evaluation framework, offering critical insights for developing more robust and practical WF attacks.