 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Inheritance in Neural-Symbolic Discovery of Constitutive Closures Under Function-Class Mismatch
Apr 01, 2026We investigate the data-driven discovery of constitutive closures in nonlinear reaction-diffusion systems with known governing PDE structures. Our objective is to robustly recover diffusion and reaction laws from spatiotemporal observations while avoiding the common pitfall where low residuals or short-horizon predictions are conflated with physical recovery. We propose a three-stage neural-symbolic framework: (1) learning numerical surrogates under physical constraints using a noise-robust weak-form-driven objective; (2) compressing these surrogates into restricted interpretable symbolic families (e.g., polynomial, rational, and saturation forms); and (3) validating the symbolic closures through explicit forward re-simulation on unseen initial conditions. Extensive numerical experiments reveal two distinct regimes. Under matched-library settings, weak polynomial baselines behave as correctly specified reference estimators, showing that neural surrogates do not uniformly outperform classical bases. Conversely, under function-class mismatch, neural surrogates provide necessary flexibility and can be compressed into compact symbolic laws with minimal rollout degradation. However, we identify a critical "bias inheritance" mechanism where symbolic compression does not automatically repair constitutive bias. Across various observation regimes, the true error of the symbolic closure closely tracks that of the neural surrogate, yielding a bias inheritance ratio near one. These findings demonstrate that the primary bottleneck in neural-symbolic modeling lies in the initial numerical inverse problem rather than the subsequent symbolic compression. We underscore that constitutive claims must be rigorously supported by forward validation rather than residual minimization alone.
Residual Attention Physics-Informed Neural Networks for Robust Multiphysics Simulation of Steady-State Electrothermal Energy Systems
Mar 24, 2026Efficient thermal management and precise field prediction are critical for the design of advanced energy systems, including electrohydrodynamic transport, microfluidic energy harvesters, and electrically driven thermal regulators. However, the steady-state simulation of these electrothermal coupled multiphysics systems remains challenging for physics-informed neural computation due to strong nonlinear field coupling, temperature-dependent coefficient variability, and complex interface dynamics. This study proposes a Residual Attention Physics-Informed Neural Network (RA-PINN) framework for the unified solution of coupled velocity, pressure, electric-potential, and temperature fields. By integrating a unified five-field operator formulation with residual-connected feature propagation and attention-guided channel modulation, the proposed architecture effectively captures localized coupling structures and steep gradients. We evaluate RA-PINN across four representative energy-relevant benchmarks: constant-coefficient coupling, indirect pressure-gauge constraints, temperature-dependent transport, and oblique-interface consistency. Comparative analysis against Pure-MLP, LSTM-PINN, and pLSTM-PINN demonstrates that RA-PINN achieves superior accuracy, yielding the lowest MSE, RMSE, and relative $L_2$ errors across all scenarios. Notably, RA-PINN maintains high structural fidelity in interface-dominated and variable-coefficient settings where conventional PINN backbones often fail. These results establish RA-PINN as a robust and accurate computational framework for the high-fidelity modeling and optimization of complex electrothermal multiphysics in sustainable energy applications.
Spectral Bias Mitigation via xLSTM-PINN: Memory-Gated Representation Refinement for Physics-Informed Learning
Nov 16, 2025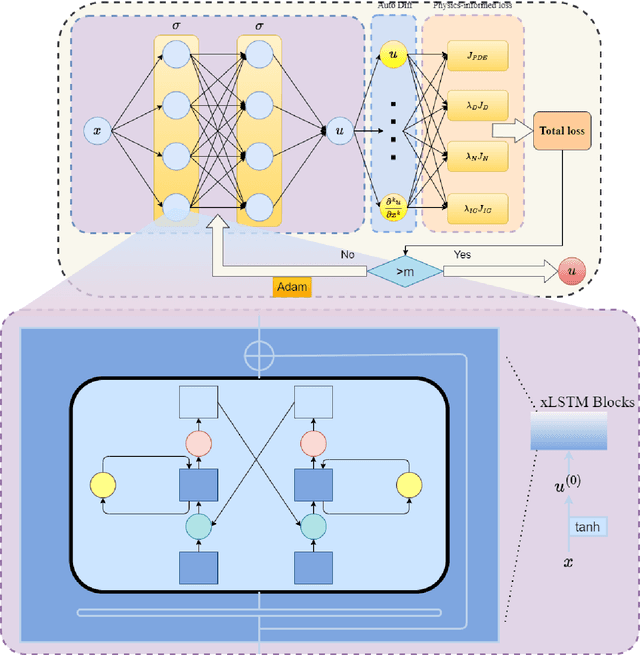

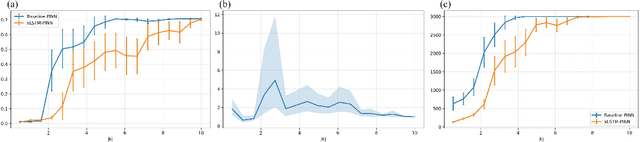

Physics-informed learning for PDEs is surging across scientific computing and industrial simulation, yet prevailing methods face spectral bias, residual-data imbalance, and weak extrapolation. We introduce a representation-level spectral remodeling xLSTM-PINN that combines gated-memory multiscale feature extraction with adaptive residual-data weighting to curb spectral bias and strengthen extrapolation. Across four benchmarks, we integrate gated cross-scale memory, a staged frequency curriculum, and adaptive residual reweighting, and verify with analytic references and extrapolation tests, achieving markedly lower spectral error and RMSE and a broader stable learning-rate window. Frequency-domain benchmarks show raised high-frequency kernel weights and a right-shifted resolvable bandwidth, shorter high-k error decay and time-to-threshold, and narrower error bands with lower MSE, RMSE, MAE, and MaxAE. Compared with the baseline PINN, we reduce MSE, RMSE, MAE, and MaxAE across all four benchmarks and deliver cleaner boundary transitions with attenuated high-frequency ripples in both frequency and field maps. This work suppresses spectral bias, widens the resolvable band and shortens the high-k time-to-threshold under the same budget, and without altering AD or physics losses improves accuracy, reproducibility, and transferability.
LNN-PINN: A Unified Physics-Only Training Framework with Liquid Residual Blocks
Aug 12, 2025



Physics-informed neural networks (PINNs) have attracted considerable attention for their ability to integrate partial differential equation priors into deep learning frameworks; however, they often exhibit limited predictive accuracy when applied to complex problems. To address this issue, we propose LNN-PINN, a physics-informed neural network framework that incorporates a liquid residual gating architecture while preserving the original physics modeling and optimization pipeline to improve predictive accuracy. The method introduces a lightweight gating mechanism solely within the hidden-layer mapping, keeping the sampling strategy, loss composition, and hyperparameter settings unchanged to ensure that improvements arise purely from architectural refinement. Across four benchmark problems, LNN-PINN consistently reduced RMSE and MAE under identical training conditions, with absolute error plots further confirming its accuracy gains. Moreover, the framework demonstrates strong adaptability and stability across varying dimensions, boundary conditions, and operator characteristics. In summary, LNN-PINN offers a concise and effective architectural enhancement for improving the predictive accuracy of physics-informed neural networks in complex scientific and engineering problems.
An LSTM-PINN Hybrid Method to the specific problem of population forecasting
May 03, 2025Deep learning has emerged as a powerful tool in scientific modeling, particularly for complex dynamical systems; however, accurately capturing age-structured population dynamics under policy-driven fertility changes remains a significant challenge due to the lack of effective integration between domain knowledge and long-term temporal dependencies. To address this issue, we propose two physics-informed deep learning frameworks--PINN and LSTM-PINN--that incorporate policy-aware fertility functions into a transport-reaction partial differential equation to simulate population evolution from 2024 to 2054. The standard PINN model enforces the governing equation and boundary conditions via collocation-based training, enabling accurate learning of underlying population dynamics and ensuring stable convergence. Building on this, the LSTM-PINN framework integrates sequential memory mechanisms to effectively capture long-range dependencies in the age-time domain, achieving robust training performance across multiple loss components. Simulation results under three distinct fertility policy scenarios-the Three-child policy, the Universal two-child policy, and the Separate two-child policy--demonstrate the models' ability to reflect policy-sensitive demographic shifts and highlight the effectiveness of integrating domain knowledge into data-driven forecasting. This study provides a novel and extensible framework for modeling age-structured population dynamics under policy interventions, offering valuable insights for data-informed demographic forecasting and long-term policy planning in the face of emerging population challenges.
ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition
Feb 23, 2024Self-attention is an essential component of large language models(LLMs) but a significant source of inference latency for long sequences. In multi-tenant LLMs serving scenarios, the compute and memory operation cost of self-attention can be optimized by using the probability that multiple LLM requests have shared system prompts in prefixes. In this paper, we introduce ChunkAttention, a prefix-aware self-attention module that can detect matching prompt prefixes across multiple requests and share their key/value tensors in memory at runtime to improve the memory utilization of KV cache. This is achieved by breaking monolithic key/value tensors into smaller chunks and structuring them into the auxiliary prefix tree. Consequently, on top of the prefix-tree based KV cache, we design an efficient self-attention kernel, where a two-phase partition algorithm is implemented to improve the data locality during self-attention computation in the presence of shared system prompts. Experiments show that ChunkAttention can speed up the self-attention kernel by 3.2-4.8$\times$ compared to the start-of-the-art implementation, with the length of the system prompt ranging from 1024 to 4096.