 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Inheritance in Neural-Symbolic Discovery of Constitutive Closures Under Function-Class Mismatch
Apr 01, 2026We investigate the data-driven discovery of constitutive closures in nonlinear reaction-diffusion systems with known governing PDE structures. Our objective is to robustly recover diffusion and reaction laws from spatiotemporal observations while avoiding the common pitfall where low residuals or short-horizon predictions are conflated with physical recovery. We propose a three-stage neural-symbolic framework: (1) learning numerical surrogates under physical constraints using a noise-robust weak-form-driven objective; (2) compressing these surrogates into restricted interpretable symbolic families (e.g., polynomial, rational, and saturation forms); and (3) validating the symbolic closures through explicit forward re-simulation on unseen initial conditions. Extensive numerical experiments reveal two distinct regimes. Under matched-library settings, weak polynomial baselines behave as correctly specified reference estimators, showing that neural surrogates do not uniformly outperform classical bases. Conversely, under function-class mismatch, neural surrogates provide necessary flexibility and can be compressed into compact symbolic laws with minimal rollout degradation. However, we identify a critical "bias inheritance" mechanism where symbolic compression does not automatically repair constitutive bias. Across various observation regimes, the true error of the symbolic closure closely tracks that of the neural surrogate, yielding a bias inheritance ratio near one. These findings demonstrate that the primary bottleneck in neural-symbolic modeling lies in the initial numerical inverse problem rather than the subsequent symbolic compression. We underscore that constitutive claims must be rigorously supported by forward validation rather than residual minimization alone.
Macroscopic transport patterns of UAV traffic in 3D anisotropic wind fields: A constraint-preserving hybrid PINN-FVM approach
Apr 01, 2026Macroscopic unmanned aerial vehicle (UAV) traffic organization in three-dimensional airspace faces significant challenges from static wind fields and complex obstacles. A critical difficulty lies in simultaneously capturing the strong anisotropy induced by wind while strictly preserving transport consistency and boundary semantics, which are often compromised in standard physics-informed learning approaches. To resolve this, we propose a constraint-preserving hybrid solver that integrates a physics-informed neural network for the anisotropic Eikonal value problem with a conservative finite-volume method for steady density transport. These components are coupled through an outer Picard iteration with under-relaxation, where the target condition is hard-encoded and strictly conservative no-flux boundaries are enforced during the transport step. We evaluate the framework on reproducible homing and point-to-point scenarios, effectively capturing value slices, induced-motion patterns, and steady density structures such as bands and bottlenecks. Ultimately, our perspective emphasizes the value of a reproducible computational framework supported by transparent empirical diagnostics to enable the traceable assessment of macroscopic traffic phenomena.
Residual Attention Physics-Informed Neural Networks for Robust Multiphysics Simulation of Steady-State Electrothermal Energy Systems
Mar 24, 2026Efficient thermal management and precise field prediction are critical for the design of advanced energy systems, including electrohydrodynamic transport, microfluidic energy harvesters, and electrically driven thermal regulators. However, the steady-state simulation of these electrothermal coupled multiphysics systems remains challenging for physics-informed neural computation due to strong nonlinear field coupling, temperature-dependent coefficient variability, and complex interface dynamics. This study proposes a Residual Attention Physics-Informed Neural Network (RA-PINN) framework for the unified solution of coupled velocity, pressure, electric-potential, and temperature fields. By integrating a unified five-field operator formulation with residual-connected feature propagation and attention-guided channel modulation, the proposed architecture effectively captures localized coupling structures and steep gradients. We evaluate RA-PINN across four representative energy-relevant benchmarks: constant-coefficient coupling, indirect pressure-gauge constraints, temperature-dependent transport, and oblique-interface consistency. Comparative analysis against Pure-MLP, LSTM-PINN, and pLSTM-PINN demonstrates that RA-PINN achieves superior accuracy, yielding the lowest MSE, RMSE, and relative $L_2$ errors across all scenarios. Notably, RA-PINN maintains high structural fidelity in interface-dominated and variable-coefficient settings where conventional PINN backbones often fail. These results establish RA-PINN as a robust and accurate computational framework for the high-fidelity modeling and optimization of complex electrothermal multiphysics in sustainable energy applications.
Spectral Bias Mitigation via xLSTM-PINN: Memory-Gated Representation Refinement for Physics-Informed Learning
Nov 16, 2025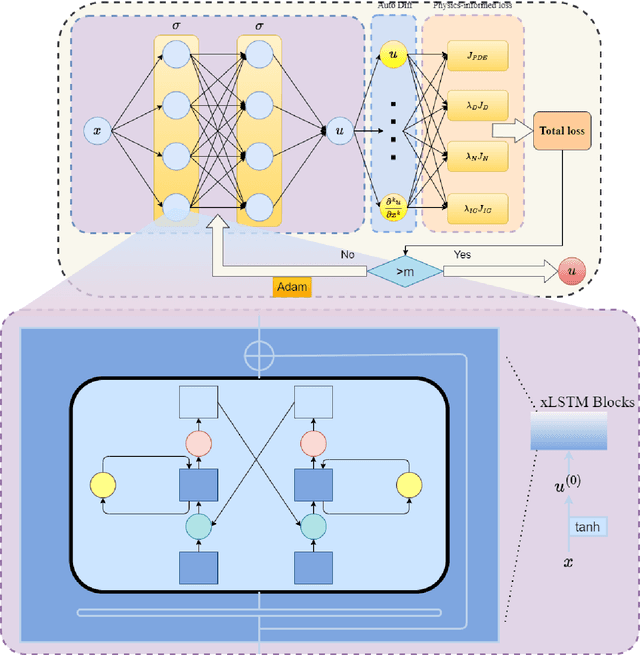

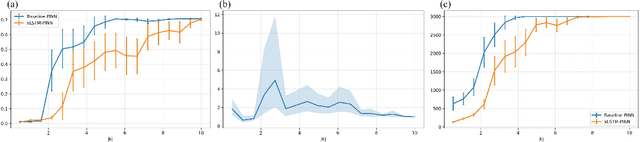

Physics-informed learning for PDEs is surging across scientific computing and industrial simulation, yet prevailing methods face spectral bias, residual-data imbalance, and weak extrapolation. We introduce a representation-level spectral remodeling xLSTM-PINN that combines gated-memory multiscale feature extraction with adaptive residual-data weighting to curb spectral bias and strengthen extrapolation. Across four benchmarks, we integrate gated cross-scale memory, a staged frequency curriculum, and adaptive residual reweighting, and verify with analytic references and extrapolation tests, achieving markedly lower spectral error and RMSE and a broader stable learning-rate window. Frequency-domain benchmarks show raised high-frequency kernel weights and a right-shifted resolvable bandwidth, shorter high-k error decay and time-to-threshold, and narrower error bands with lower MSE, RMSE, MAE, and MaxAE. Compared with the baseline PINN, we reduce MSE, RMSE, MAE, and MaxAE across all four benchmarks and deliver cleaner boundary transitions with attenuated high-frequency ripples in both frequency and field maps. This work suppresses spectral bias, widens the resolvable band and shortens the high-k time-to-threshold under the same budget, and without altering AD or physics losses improves accuracy, reproducibility, and transferability.
LNN-PINN: A Unified Physics-Only Training Framework with Liquid Residual Blocks
Aug 12, 2025



Physics-informed neural networks (PINNs) have attracted considerable attention for their ability to integrate partial differential equation priors into deep learning frameworks; however, they often exhibit limited predictive accuracy when applied to complex problems. To address this issue, we propose LNN-PINN, a physics-informed neural network framework that incorporates a liquid residual gating architecture while preserving the original physics modeling and optimization pipeline to improve predictive accuracy. The method introduces a lightweight gating mechanism solely within the hidden-layer mapping, keeping the sampling strategy, loss composition, and hyperparameter settings unchanged to ensure that improvements arise purely from architectural refinement. Across four benchmark problems, LNN-PINN consistently reduced RMSE and MAE under identical training conditions, with absolute error plots further confirming its accuracy gains. Moreover, the framework demonstrates strong adaptability and stability across varying dimensions, boundary conditions, and operator characteristics. In summary, LNN-PINN offers a concise and effective architectural enhancement for improving the predictive accuracy of physics-informed neural networks in complex scientific and engineering problems.
Inference Compute-Optimal Video Vision Language Models
May 24, 2025This work investigates the optimal allocation of inference compute across three key scaling factors in video vision language models: language model size, frame count, and the number of visual tokens per frame. While prior works typically focuses on optimizing model efficiency or improving performance without considering resource constraints, we instead identify optimal model configuration under fixed inference compute budgets. We conduct large-scale training sweeps and careful parametric modeling of task performance to identify the inference compute-optimal frontier. Our experiments reveal how task performance depends on scaling factors and finetuning data size, as well as how changes in data size shift the compute-optimal frontier. These findings translate to practical tips for selecting these scaling factors.