 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaViDa: A Large Diffusion Language Model for Multimodal Understanding
May 22, 2025Modern Vision-Language Models (VLMs) can solve a wide range of tasks requiring visual reasoning. In real-world scenarios, desirable properties for VLMs include fast inference and controllable generation (e.g., constraining outputs to adhere to a desired format). However, existing autoregressive (AR) VLMs like LLaVA struggle in these aspects. Discrete diffusion models (DMs) offer a promising alternative, enabling parallel decoding for faster inference and bidirectional context for controllable generation through text-infilling. While effective in language-only settings, DMs' potential for multimodal tasks is underexplored. We introduce LaViDa, a family of VLMs built on DMs. We build LaViDa by equipping DMs with a vision encoder and jointly fine-tune the combined parts for multimodal instruction following. To address challenges encountered, LaViDa incorporates novel techniques such as complementary masking for effective training, prefix KV cache for efficient inference, and timestep shifting for high-quality sampling. Experiments show that LaViDa achieves competitive or superior performance to AR VLMs on multi-modal benchmarks such as MMMU, while offering unique advantages of DMs, including flexible speed-quality tradeoff, controllability, and bidirectional reasoning. On COCO captioning, LaViDa surpasses Open-LLaVa-Next-8B by +4.1 CIDEr with 1.92x speedup. On bidirectional tasks, it achieves +59% improvement on Constrained Poem Completion. These results demonstrate LaViDa as a strong alternative to AR VLMs. Code and models will be released in the camera-ready version.
Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision
May 21, 2025Mathematical reasoning presents a significant challenge for Large Language Models (LLMs), often requiring robust multi step logical consistency. While Chain of Thought (CoT) prompting elicits reasoning steps, it doesn't guarantee correctness, and improving reliability via extensive sampling is computationally costly. This paper introduces the Energy Outcome Reward Model (EORM), an effective, lightweight, post hoc verifier. EORM leverages Energy Based Models (EBMs) to simplify the training of reward models by learning to assign a scalar energy score to CoT solutions using only outcome labels, thereby avoiding detailed annotations. It achieves this by interpreting discriminator output logits as negative energies, effectively ranking candidates where lower energy is assigned to solutions leading to correct final outcomes implicitly favoring coherent reasoning. On mathematical benchmarks (GSM8k, MATH), EORM significantly improves final answer accuracy (e.g., with Llama 3 8B, achieving 90.7% on GSM8k and 63.7% on MATH). EORM effectively leverages a given pool of candidate solutions to match or exceed the performance of brute force sampling, thereby enhancing LLM reasoning outcome reliability through its streamlined post hoc verification process.
CompAlign: Improving Compositional Text-to-Image Generation with a Complex Benchmark and Fine-Grained Feedback
May 16, 2025State-of-the-art T2I models are capable of generating high-resolution images given textual prompts. However, they still struggle with accurately depicting compositional scenes that specify multiple objects, attributes, and spatial relations. We present CompAlign, a challenging benchmark with an emphasis on assessing the depiction of 3D-spatial relationships, for evaluating and improving models on compositional image generation. CompAlign consists of 900 complex multi-subject image generation prompts that combine numerical and 3D-spatial relationships with varied attribute bindings. Our benchmark is remarkably challenging, incorporating generation tasks with 3+ generation subjects with complex 3D-spatial relationships. Additionally, we propose CompQuest, an interpretable and accurate evaluation framework that decomposes complex prompts into atomic sub-questions, then utilizes a MLLM to provide fine-grained binary feedback on the correctness of each aspect of generation elements in model-generated images. This enables precise quantification of alignment between generated images and compositional prompts. Furthermore, we propose an alignment framework that uses CompQuest's feedback as preference signals to improve diffusion models' compositional image generation abilities. Using adjustable per-image preferences, our method is easily scalable and flexible for different tasks. Evaluation of 9 T2I models reveals that: (1) models remarkable struggle more with compositional tasks with more complex 3D-spatial configurations, and (2) a noticeable performance gap exists between open-source accessible models and closed-source commercial models. Further empirical study on using CompAlign for model alignment yield promising results: post-alignment diffusion models achieve remarkable improvements in compositional accuracy, especially on complex generation tasks, outperforming previous approaches.
Agree to Disagree? A Meta-Evaluation of LLM Misgendering
Apr 23, 2025Numerous methods have been proposed to measure LLM misgendering, including probability-based evaluations (e.g., automatically with templatic sentences) and generation-based evaluations (e.g., with automatic heuristics or human validation). However, it has gone unexamined whether these evaluation methods have convergent validity, that is, whether their results align. Therefore, we conduct a systematic meta-evaluation of these methods across three existing datasets for LLM misgendering. We propose a method to transform each dataset to enable parallel probability- and generation-based evaluation. Then, by automatically evaluating a suite of 6 models from 3 families, we find that these methods can disagree with each other at the instance, dataset, and model levels, conflicting on 20.2% of evaluation instances. Finally, with a human evaluation of 2400 LLM generations, we show that misgendering behaviour is complex and goes far beyond pronouns, which automatic evaluations are not currently designed to capture, suggesting essential disagreement with human evaluations. Based on our findings, we provide recommendations for future evaluations of LLM misgendering. Our results are also more widely relevant, as they call into question broader methodological conventions in LLM evaluation, which often assume that different evaluation methods agree.
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents
Apr 15, 2025Multi-turn interactions with language models (LMs) pose critical safety risks, as harmful intent can be strategically spread across exchanges. Yet, the vast majority of prior work has focused on single-turn safety, while adaptability and diversity remain among the key challenges of multi-turn red-teaming. To address these challenges, we present X-Teaming, a scalable framework that systematically explores how seemingly harmless interactions escalate into harmful outcomes and generates corresponding attack scenarios. X-Teaming employs collaborative agents for planning, attack optimization, and verification, achieving state-of-the-art multi-turn jailbreak effectiveness and diversity with success rates up to 98.1% across representative leading open-weight and closed-source models. In particular, X-Teaming achieves a 96.2% attack success rate against the latest Claude 3.7 Sonnet model, which has been considered nearly immune to single-turn attacks. Building on X-Teaming, we introduce XGuard-Train, an open-source multi-turn safety training dataset that is 20x larger than the previous best resource, comprising 30K interactive jailbreaks, designed to enable robust multi-turn safety alignment for LMs. Our work offers essential tools and insights for mitigating sophisticated conversational attacks, advancing the multi-turn safety of LMs.
On The Landscape of Spoken Language Models: A Comprehensive Survey
Apr 11, 2025



The field of spoken language processing is undergoing a shift from training custom-built, task-specific models toward using and optimizing spoken language models (SLMs) which act as universal speech processing systems. This trend is similar to the progression toward universal language models that has taken place in the field of (text) natural language processing. SLMs include both "pure" language models of speech -- models of the distribution of tokenized speech sequences -- and models that combine speech encoders with text language models, often including both spoken and written input or output. Work in this area is very diverse, with a range of terminology and evaluation settings. This paper aims to contribute an improved understanding of SLMs via a unifying literature survey of recent work in the context of the evolution of the field. Our survey categorizes the work in this area by model architecture, training, and evaluation choices, and describes some key challenges and directions for future work.
When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning
Apr 01, 2025Scaling test-time compute has emerged as a key strategy for enhancing the reasoning capabilities of large language models (LLMs), particularly in tasks like mathematical problem-solving. A traditional approach, Self-Consistency (SC), generates multiple solutions to a problem and selects the most common answer via majority voting. Another common method involves scoring each solution with a reward model (verifier) and choosing the best one. Recent advancements in Generative Reward Models (GenRM) reframe verification as a next-token prediction task, enabling inference-time scaling along a new axis. Specifically, GenRM generates multiple verification chains-of-thought to score each solution. Under a limited inference budget, this introduces a fundamental trade-off: should you spend the budget on scaling solutions via SC or generate fewer solutions and allocate compute to verification via GenRM? To address this, we evaluate GenRM against SC under a fixed inference budget. Interestingly, we find that SC is more compute-efficient than GenRM for most practical inference budgets across diverse models and datasets. For instance, GenRM first matches SC after consuming up to 8x the inference compute and requires significantly more compute to outperform it. Furthermore, we derive inference scaling laws for the GenRM paradigm, revealing that compute-optimal inference favors scaling solution generation more aggressively than scaling the number of verifications. Our work provides practical guidance on optimizing test-time scaling by balancing solution generation and verification. The code is available at https://github.com/nishadsinghi/sc-genrm-scaling.
Self-Routing RAG: Binding Selective Retrieval with Knowledge Verbalization
Apr 01, 2025Selective retrieval improves retrieval-augmented generation (RAG) by reducing distractions from low-quality retrievals and improving efficiency. However, existing approaches under-utilize the inherent knowledge of large language models (LLMs), leading to suboptimal retrieval decisions and degraded generation performance. To bridge this gap, we propose Self-Routing RAG (SR-RAG), a novel framework that binds selective retrieval with knowledge verbalization. SR-RAG enables an LLM to dynamically decide between external retrieval and verbalizing its own parametric knowledge. To this end, we design a multi-task objective that jointly optimizes an LLM on knowledge source selection, knowledge verbalization, and response generation. We further introduce dynamic knowledge source inference via nearest neighbor search to improve the accuracy of knowledge source decision under domain shifts. Fine-tuning three LLMs with SR-RAG significantly improves both their response accuracy and inference latency. Compared to the strongest selective retrieval baseline, SR-RAG reduces retrievals by 29% while improving the performance by 5.1%.
OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement
Mar 21, 2025
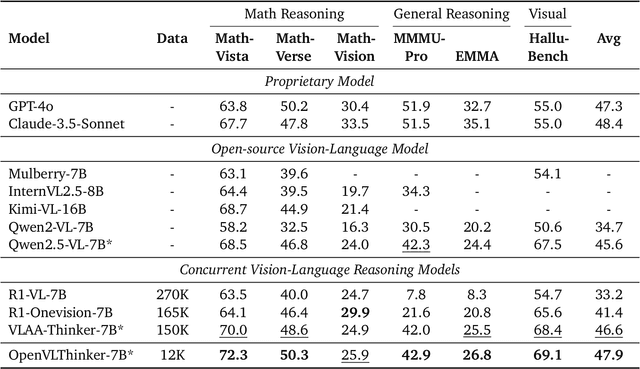
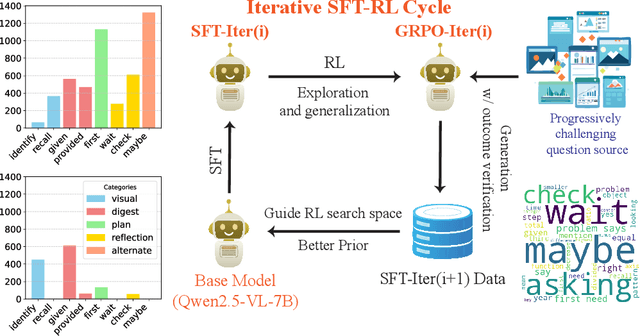
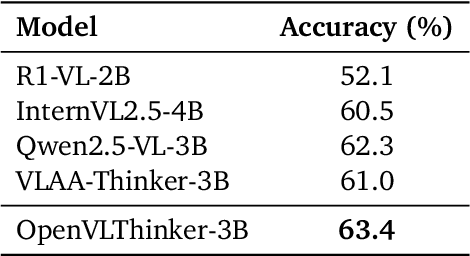
Recent advancements demonstrated by DeepSeek-R1 have shown that complex reasoning abilities in large language models (LLMs), including sophisticated behaviors such as self-verification and self-correction, can be achieved by RL with verifiable rewards and significantly improves model performance on challenging tasks such as AIME. Motivated by these findings, our study investigates whether similar reasoning capabilities can be successfully integrated into large vision-language models (LVLMs) and assesses their impact on challenging multimodal reasoning tasks. We consider an approach that iteratively leverages supervised fine-tuning (SFT) on lightweight training data and Reinforcement Learning (RL) to further improve model generalization. Initially, reasoning capabilities were distilled from pure-text R1 models by generating reasoning steps using high-quality captions of the images sourced from diverse visual datasets. Subsequently, iterative RL training further enhance reasoning skills, with each iteration's RL-improved model generating refined SFT datasets for the next round. This iterative process yielded OpenVLThinker, a LVLM exhibiting consistently improved reasoning performance on challenging benchmarks such as MathVista, MathVerse, and MathVision, demonstrating the potential of our strategy for robust vision-language reasoning. The code, model and data are held at https://github.com/yihedeng9/OpenVLThinker.
Magnet: Multi-turn Tool-use Data Synthesis and Distillation via Graph Translation
Mar 10, 2025



Large language models (LLMs) have exhibited the ability to effectively utilize external tools to address user queries. However, their performance may be limited in complex, multi-turn interactions involving users and multiple tools. To address this, we propose Magnet, a principled framework for synthesizing high-quality training trajectories to enhance the function calling capability of large language model agents in multi-turn conversations with humans. The framework is based on automatic and iterative translations from a function signature path to a sequence of queries and executable function calls. We model the complicated function interactions in multi-turn cases with graph and design novel node operations to build reliable signature paths. Motivated by context distillation, when guiding the generation of positive and negative trajectories using a teacher model, we provide reference function call sequences as positive hints in context and contrastive, incorrect function calls as negative hints. Experiments show that training with the positive trajectories with supervised fine-tuning and preference optimization against negative trajectories, our 14B model, Magnet-14B-mDPO, obtains 68.01 on BFCL-v3 and 73.30 on ToolQuery, surpassing the performance of the teacher model Gemini-1.5-pro-002 by a large margin in function calling.