 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Do Images Come From? Analyzing Captions to Geographically Profile Datasets
Feb 10, 2026Recent studies show that text-to-image models often fail to generate geographically representative images, raising concerns about the representativeness of their training data and motivating the question: which parts of the world do these training examples come from? We geographically profile large-scale multimodal datasets by mapping image-caption pairs to countries based on location information extracted from captions using LLMs. Studying English captions from three widely used datasets (Re-LAION, DataComp1B, and Conceptual Captions) across $20$ common entities (e.g., house, flag), we find that the United States, the United Kingdom, and Canada account for $48.0\%$ of samples, while South American and African countries are severely under-represented with only $1.8\%$ and $3.8\%$ of images, respectively. We observe a strong correlation between a country's GDP and its representation in the data ($ρ= 0.82$). Examining non-English subsets for $4$ languages from the Re-LAION dataset, we find that representation skews heavily toward countries where these languages are predominantly spoken. Additionally, we find that higher representation does not necessarily translate to greater visual or semantic diversity. Finally, analyzing country-specific images generated by Stable Diffusion v1.3 trained on Re-LAION, we show that while generations appear realistic, they are severely limited in their coverage compared to real-world images.
Lost in Simulation: LLM-Simulated Users are Unreliable Proxies for Human Users in Agentic Evaluations
Jan 23, 2026Agentic benchmarks increasingly rely on LLM-simulated users to scalably evaluate agent performance, yet the robustness, validity, and fairness of this approach remain unexamined. Through a user study with participants across the United States, India, Kenya, and Nigeria, we investigate whether LLM-simulated users serve as reliable proxies for real human users in evaluating agents on τ-Bench retail tasks. We find that user simulation lacks robustness, with agent success rates varying up to 9 percentage points across different user LLMs. Furthermore, evaluations using simulated users exhibit systematic miscalibration, underestimating agent performance on challenging tasks and overestimating it on moderately difficult ones. African American Vernacular English (AAVE) speakers experience consistently worse success rates and calibration errors than Standard American English (SAE) speakers, with disparities compounding significantly with age. We also find simulated users to be a differentially effective proxy for different populations, performing worst for AAVE and Indian English speakers. Additionally, simulated users introduce conversational artifacts and surface different failure patterns than human users. These findings demonstrate that current evaluation practices risk misrepresenting agent capabilities across diverse user populations and may obscure real-world deployment challenges.
Agree to Disagree? A Meta-Evaluation of LLM Misgendering
Apr 23, 2025Numerous methods have been proposed to measure LLM misgendering, including probability-based evaluations (e.g., automatically with templatic sentences) and generation-based evaluations (e.g., with automatic heuristics or human validation). However, it has gone unexamined whether these evaluation methods have convergent validity, that is, whether their results align. Therefore, we conduct a systematic meta-evaluation of these methods across three existing datasets for LLM misgendering. We propose a method to transform each dataset to enable parallel probability- and generation-based evaluation. Then, by automatically evaluating a suite of 6 models from 3 families, we find that these methods can disagree with each other at the instance, dataset, and model levels, conflicting on 20.2% of evaluation instances. Finally, with a human evaluation of 2400 LLM generations, we show that misgendering behaviour is complex and goes far beyond pronouns, which automatic evaluations are not currently designed to capture, suggesting essential disagreement with human evaluations. Based on our findings, we provide recommendations for future evaluations of LLM misgendering. Our results are also more widely relevant, as they call into question broader methodological conventions in LLM evaluation, which often assume that different evaluation methods agree.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Who Does the Giant Number Pile Like Best: Analyzing Fairness in Hiring Contexts
Jan 08, 2025



Large language models (LLMs) are increasingly being deployed in high-stakes applications like hiring, yet their potential for unfair decision-making and outcomes remains understudied, particularly in generative settings. In this work, we examine the fairness of LLM-based hiring systems through two real-world tasks: resume summarization and retrieval. By constructing a synthetic resume dataset and curating job postings, we investigate whether model behavior differs across demographic groups and is sensitive to demographic perturbations. Our findings reveal that race-based differences appear in approximately 10% of generated summaries, while gender-based differences occur in only 1%. In the retrieval setting, all evaluated models display non-uniform selection patterns across demographic groups and exhibit high sensitivity to both gender and race-based perturbations. Surprisingly, retrieval models demonstrate comparable sensitivity to non-demographic changes, suggesting that fairness issues may stem, in part, from general brittleness issues. Overall, our results indicate that LLM-based hiring systems, especially at the retrieval stage, can exhibit notable biases that lead to discriminatory outcomes in real-world contexts.
How Many Van Goghs Does It Take to Van Gogh? Finding the Imitation Threshold
Oct 19, 2024Text-to-image models are trained using large datasets collected by scraping image-text pairs from the internet. These datasets often include private, copyrighted, and licensed material. Training models on such datasets enables them to generate images with such content, which might violate copyright laws and individual privacy. This phenomenon is termed imitation -- generation of images with content that has recognizable similarity to its training images. In this work we study the relationship between a concept's frequency in the training dataset and the ability of a model to imitate it. We seek to determine the point at which a model was trained on enough instances to imitate a concept -- the imitation threshold. We posit this question as a new problem: Finding the Imitation Threshold (FIT) and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training multiple models from scratch. We experiment with two domains -- human faces and art styles -- for which we create four datasets, and evaluate three text-to-image models which were trained on two pretraining datasets. Our results reveal that the imitation threshold of these models is in the range of 200-600 images, depending on the domain and the model. The imitation threshold can provide an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws. We release the code and data at \url{https://github.com/vsahil/MIMETIC-2.git} and the project's website is hosted at \url{https://how-many-van-goghs-does-it-take.github.io}.
Are Models Biased on Text without Gender-related Language?
May 01, 2024Gender bias research has been pivotal in revealing undesirable behaviors in large language models, exposing serious gender stereotypes associated with occupations, and emotions. A key observation in prior work is that models reinforce stereotypes as a consequence of the gendered correlations that are present in the training data. In this paper, we focus on bias where the effect from training data is unclear, and instead address the question: Do language models still exhibit gender bias in non-stereotypical settings? To do so, we introduce UnStereoEval (USE), a novel framework tailored for investigating gender bias in stereotype-free scenarios. USE defines a sentence-level score based on pretraining data statistics to determine if the sentence contain minimal word-gender associations. To systematically benchmark the fairness of popular language models in stereotype-free scenarios, we utilize USE to automatically generate benchmarks without any gender-related language. By leveraging USE's sentence-level score, we also repurpose prior gender bias benchmarks (Winobias and Winogender) for non-stereotypical evaluation. Surprisingly, we find low fairness across all 28 tested models. Concretely, models demonstrate fair behavior in only 9%-41% of stereotype-free sentences, suggesting that bias does not solely stem from the presence of gender-related words. These results raise important questions about where underlying model biases come from and highlight the need for more systematic and comprehensive bias evaluation. We release the full dataset and code at https://ucinlp.github.io/unstereo-eval.
The Bias Amplification Paradox in Text-to-Image Generation
Aug 01, 2023



Bias amplification is a phenomenon in which models increase imbalances present in the training data. In this paper, we study bias amplification in the text-to-image domain using Stable Diffusion by comparing gender ratios in training vs. generated images. We find that the model appears to amplify gender-occupation biases found in the training data (LAION). However, we discover that amplification can largely be attributed to discrepancies between training captions and model prompts. For example, an inherent difference is that captions from the training data often contain explicit gender information while the prompts we use do not, which leads to a distribution shift and consequently impacts bias measures. Once we account for various distributional differences between texts used for training and generation, we observe that amplification decreases considerably. Our findings illustrate the challenges of comparing biases in models and the data they are trained on, and highlight confounding factors that contribute to bias amplification.
Quantifying Social Biases Using Templates is Unreliable
Oct 09, 2022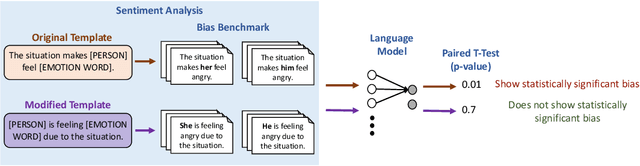

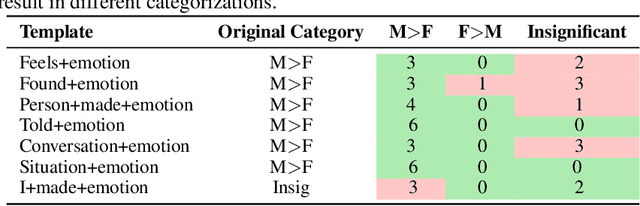

Recently, there has been an increase in efforts to understand how large language models (LLMs) propagate and amplify social biases. Several works have utilized templates for fairness evaluation, which allow researchers to quantify social biases in the absence of test sets with protected attribute labels. While template evaluation can be a convenient and helpful diagnostic tool to understand model deficiencies, it often uses a simplistic and limited set of templates. In this paper, we study whether bias measurements are sensitive to the choice of templates used for benchmarking. Specifically, we investigate the instability of bias measurements by manually modifying templates proposed in previous works in a semantically-preserving manner and measuring bias across these modifications. We find that bias values and resulting conclusions vary considerably across template modifications on four tasks, ranging from an 81% reduction (NLI) to a 162% increase (MLM) in (task-specific) bias measurements. Our results indicate that quantifying fairness in LLMs, as done in current practice, can be brittle and needs to be approached with more care and caution.
Fonts-2-Handwriting: A Seed-Augment-Train framework for universal digit classification
May 16, 2019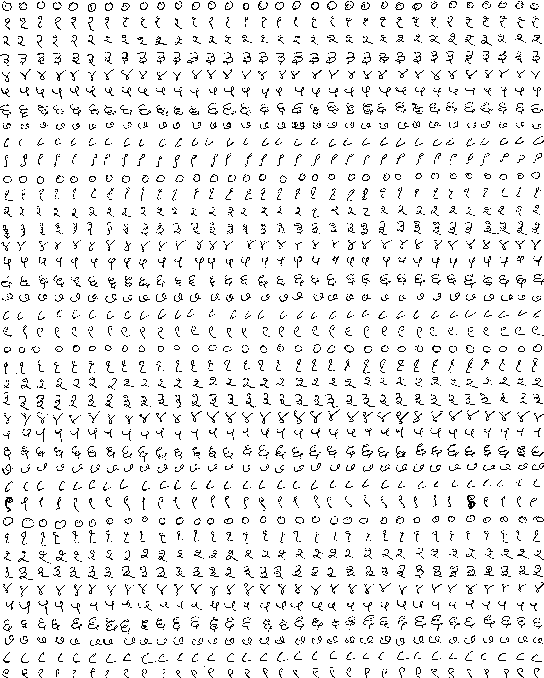

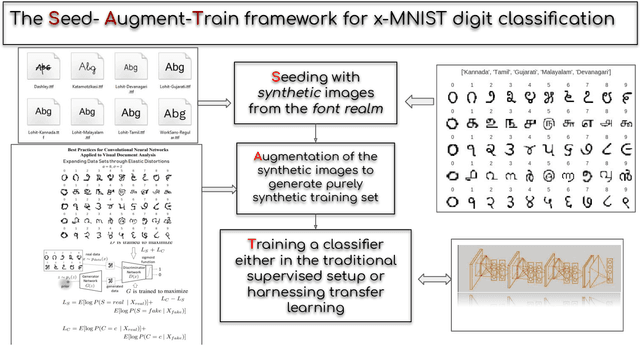

In this paper, we propose a Seed-Augment-Train/Transfer (SAT) framework that contains a synthetic seed image dataset generation procedure for languages with different numeral systems using freely available open font file datasets. This seed dataset of images is then augmented to create a purely synthetic training dataset, which is in turn used to train a deep neural network and test on held-out real world handwritten digits dataset spanning five Indic scripts, Kannada, Tamil, Gujarati, Malayalam, and Devanagari. We showcase the efficacy of this approach both qualitatively, by training a Boundary-seeking GAN (BGAN) that generates realistic digit images in the five languages, and also quantitatively by testing a CNN trained on the synthetic data on the real-world datasets. This establishes not only an interesting nexus between the font-datasets-world and transfer learning but also provides a recipe for universal-digit classification in any script.