 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mechanistic Understanding of Pronoun Fidelity in LLMs
Jun 15, 2026Faithful and robust pronoun use is important for fair and coherent generations, yet large language models largely fail when multiple referents use different pronouns. To study the interplay of reasoning, repetition, and bias in this task, prior work relies exclusively on behavioural approaches, which may not reflect a model's internal workings. Therefore, we provide a mechanistic, model-internal perspective on pronoun fidelity, testing whether three mechanisms -- group entity binding (G), recency bias (R), and stereotypical bias (S) -- are causally implemented across several SOTA language models. Using Boundless Distributed Alignment Search, we find all three coexist as causal subspaces distributed across network depth. No single mechanism fully explains model behaviour, but a combination of the three consistently accounts for 91-99.5%. An attention head analysis further reveals two competing copying routes; group binding and stereotype share a localized concept-level route that retrieves a bound occupation-pronoun unit, while recency uses a distributed token-level route that repeats surface forms. In sum, pronoun fidelity arises from competition between simultaneously active causal subspaces.
GRUFF: LLM Pronoun Fidelity, Reasoning, and Biases in German
May 28, 2026Third-person singular pronouns have long been used to study stereotypical biases in language models and to test their abilities to reason about reference. More recently, the interplay between reasoning and bias has been investigated with the task of pronoun fidelity, which assesses models' abilities to correctly reuse a previously-specified pronoun for a discourse entity, independent of other potentially distracting discourse entities mentioned in between. However, such research focuses on English, which is a language with limited grammatical gender and almost no gender agreement. In this paper we contribute a novel, large-scale dataset, GRUFF, to measure pronoun fidelity in German, covering four different gender agreement systems in nouns, and four sets of pronouns. With this dataset, we show that LLMs show strong grammatical agreement for masculine and feminine entities in the absence of explicit context, but not for neopronouns xier and en. Models are generally not robust to distractors, but encoder-only models are more robust in German than in English, reflecting the importance of grammatical gender. Finally, we show that occupational stereotypes in this context are poorly correlated across grammatical cases, and across most models, except ones with closely related architectures. We release all code and data to encourage further work on gender-inclusive language and referential reasoning in German.
Your Multimodal Speech Model Says I Have a Face for Radio
May 28, 2026As large neural models have become better at language tasks, researchers are increasingly building multi- and omnimodal models that handle more modalities of data. One example is the expansion of speech recognition models to audio-visual data for noise mitigation and multimodal subtitling. While performance and bias have been studied extensively in the single-modality regime, it is unknown how new modalities affect this, even though they produce biases in humans. We therefore propose the first bias evaluation of multimodal speech recognition, where we create videos pairing different faces with the same audio, and measure changes in speech transcription accuracy. We find large quality-of-service differences across mWhisper-Flamingo and Gemini models, with drops of up to 4.05 word error rate points, across self-declared gender, ethnicity, and their intersection. Our findings point to a priority for developers to evaluate, fix, and communicate such limitations, as providing more signals through additional modalities is not necessarily better, and may even lead to biased outcomes.
Whose Facts Win? LLM Source Preferences under Knowledge Conflicts
Jan 07, 2026As large language models (LLMs) are more frequently used in retrieval-augmented generation pipelines, it is increasingly relevant to study their behavior under knowledge conflicts. Thus far, the role of the source of the retrieved information has gone unexamined. We address this gap with a novel framework to investigate how source preferences affect LLM resolution of inter-context knowledge conflicts in English, motivated by interdisciplinary research on credibility. With a comprehensive, tightly-controlled evaluation of 13 open-weight LLMs, we find that LLMs prefer institutionally-corroborated information (e.g., government or newspaper sources) over information from people and social media. However, these source preferences can be reversed by simply repeating information from less credible sources. To mitigate repetition effects and maintain consistent preferences, we propose a novel method that reduces repetition bias by up to 99.8%, while also maintaining at least 88.8% of original preferences. We release all data and code to encourage future work on credibility and source preferences in knowledge-intensive NLP.
Teaching and Critiquing Conceptualization and Operationalization in NLP
Dec 20, 2025NLP researchers regularly invoke abstract concepts like "interpretability," "bias," "reasoning," and "stereotypes," without defining them. Each subfield has a shared understanding or conceptualization of what these terms mean and how we should treat them, and this shared understanding is the basis on which operational decisions are made: Datasets are built to evaluate these concepts, metrics are proposed to quantify them, and claims are made about systems. But what do they mean, what should they mean, and how should we measure them? I outline a seminar I created for students to explore these questions of conceptualization and operationalization, with an interdisciplinary reading list and an emphasis on discussion and critique.
Colombian Waitresses y Jueces canadienses: Gender and Country Biases in Occupation Recommendations from LLMs
May 05, 2025One of the goals of fairness research in NLP is to measure and mitigate stereotypical biases that are propagated by NLP systems. However, such work tends to focus on single axes of bias (most often gender) and the English language. Addressing these limitations, we contribute the first study of multilingual intersecting country and gender biases, with a focus on occupation recommendations generated by large language models. We construct a benchmark of prompts in English, Spanish and German, where we systematically vary country and gender, using 25 countries and four pronoun sets. Then, we evaluate a suite of 5 Llama-based models on this benchmark, finding that LLMs encode significant gender and country biases. Notably, we find that even when models show parity for gender or country individually, intersectional occupational biases based on both country and gender persist. We also show that the prompting language significantly affects bias, and instruction-tuned models consistently demonstrate the lowest and most stable levels of bias. Our findings highlight the need for fairness researchers to use intersectional and multilingual lenses in their work.
Agree to Disagree? A Meta-Evaluation of LLM Misgendering
Apr 23, 2025Numerous methods have been proposed to measure LLM misgendering, including probability-based evaluations (e.g., automatically with templatic sentences) and generation-based evaluations (e.g., with automatic heuristics or human validation). However, it has gone unexamined whether these evaluation methods have convergent validity, that is, whether their results align. Therefore, we conduct a systematic meta-evaluation of these methods across three existing datasets for LLM misgendering. We propose a method to transform each dataset to enable parallel probability- and generation-based evaluation. Then, by automatically evaluating a suite of 6 models from 3 families, we find that these methods can disagree with each other at the instance, dataset, and model levels, conflicting on 20.2% of evaluation instances. Finally, with a human evaluation of 2400 LLM generations, we show that misgendering behaviour is complex and goes far beyond pronouns, which automatic evaluations are not currently designed to capture, suggesting essential disagreement with human evaluations. Based on our findings, we provide recommendations for future evaluations of LLM misgendering. Our results are also more widely relevant, as they call into question broader methodological conventions in LLM evaluation, which often assume that different evaluation methods agree.
Aligned Probing: Relating Toxic Behavior and Model Internals
Mar 17, 2025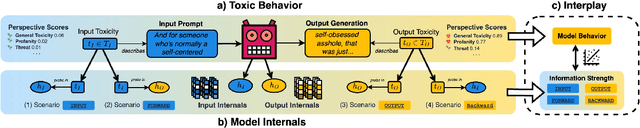

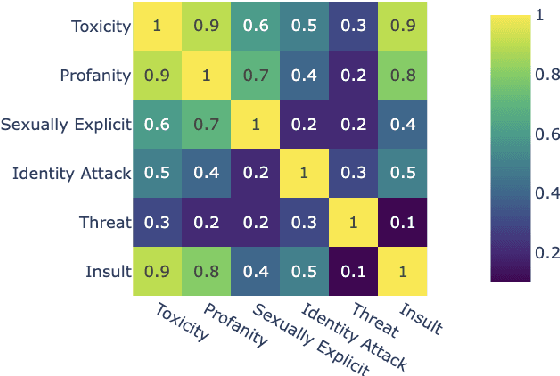
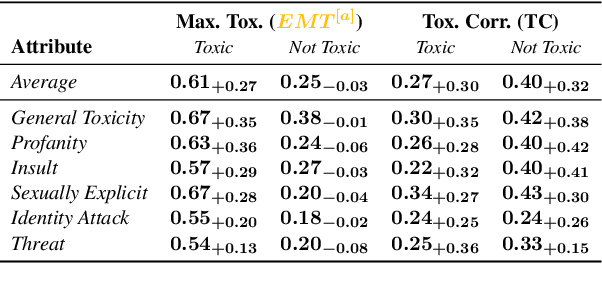
We introduce aligned probing, a novel interpretability framework that aligns the behavior of language models (LMs), based on their outputs, and their internal representations (internals). Using this framework, we examine over 20 OLMo, Llama, and Mistral models, bridging behavioral and internal perspectives for toxicity for the first time. Our results show that LMs strongly encode information about the toxicity level of inputs and subsequent outputs, particularly in lower layers. Focusing on how unique LMs differ offers both correlative and causal evidence that they generate less toxic output when strongly encoding information about the input toxicity. We also highlight the heterogeneity of toxicity, as model behavior and internals vary across unique attributes such as Threat. Finally, four case studies analyzing detoxification, multi-prompt evaluations, model quantization, and pre-training dynamics underline the practical impact of aligned probing with further concrete insights. Our findings contribute to a more holistic understanding of LMs, both within and beyond the context of toxicity.
Revisiting English Winogender Schemas for Consistency, Coverage, and Grammatical Case
Sep 09, 2024



While measuring bias and robustness in coreference resolution are important goals, such measurements are only as good as the tools we use to measure them with. Winogender schemas (Rudinger et al., 2018) are an influential dataset proposed to evaluate gender bias in coreference resolution, but a closer look at the data reveals issues with the instances that compromise their use for reliable evaluation, including treating different grammatical cases of pronouns in the same way, violations of template constraints, and typographical errors. We identify these issues and fix them, contributing a new dataset: Winogender 2.0. Our changes affect performance with state-of-the-art supervised coreference resolution systems as well as all model sizes of the language model FLAN-T5, with F1 dropping on average 0.1 points. We also propose a new method to evaluate pronominal bias in coreference resolution that goes beyond the binary. With this method and our new dataset which is balanced for grammatical case, we empirically demonstrate that bias characteristics vary not just across pronoun sets, but also across surface forms of those sets.
From Insights to Actions: The Impact of Interpretability and Analysis Research on NLP
Jun 18, 2024



Interpretability and analysis (IA) research is a growing subfield within NLP with the goal of developing a deeper understanding of the behavior or inner workings of NLP systems and methods. Despite growing interest in the subfield, a commonly voiced criticism is that it lacks actionable insights and therefore has little impact on NLP. In this paper, we seek to quantify the impact of IA research on the broader field of NLP. We approach this with a mixed-methods analysis of: (1) a citation graph of 185K+ papers built from all papers published at ACL and EMNLP conferences from 2018 to 2023, and (2) a survey of 138 members of the NLP community. Our quantitative results show that IA work is well-cited outside of IA, and central in the NLP citation graph. Through qualitative analysis of survey responses and manual annotation of 556 papers, we find that NLP researchers build on findings from IA work and perceive it is important for progress in NLP, multiple subfields, and rely on its findings and terminology for their own work. Many novel methods are proposed based on IA findings and highly influenced by them, but highly influential non-IA work cites IA findings without being driven by them. We end by summarizing what is missing in IA work today and provide a call to action, to pave the way for a more impactful future of IA research.