 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaled-Time-Attention Robust Edge Network
Jul 09, 2021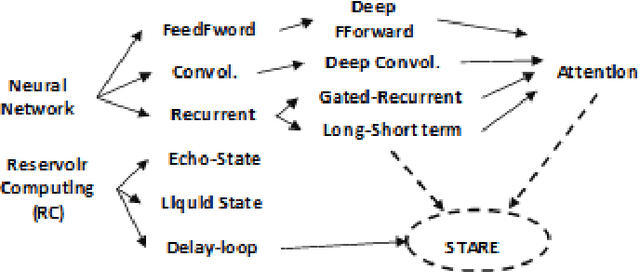
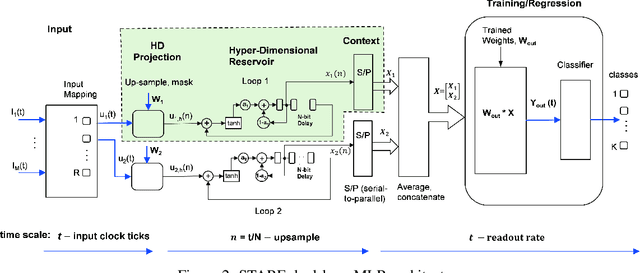
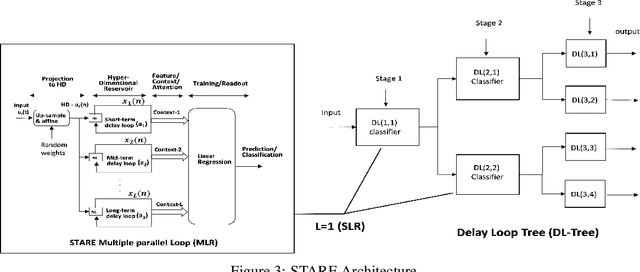
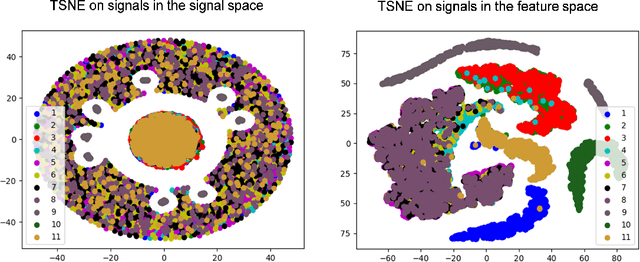
This paper describes a systematic approach towards building a new family of neural networks based on a delay-loop version of a reservoir neural network. The resulting architecture, called Scaled-Time-Attention Robust Edge (STARE) network, exploits hyper dimensional space and non-multiply-and-add computation to achieve a simpler architecture, which has shallow layers, is simple to train, and is better suited for Edge applications, such as Internet of Things (IoT), over traditional deep neural networks. STARE incorporates new AI concepts such as Attention and Context, and is best suited for temporal feature extraction and classification. We demonstrate that STARE is applicable to a variety of applications with improved performance and lower implementation complexity. In particular, we showed a novel way of applying a dual-loop configuration to detection and identification of drone vs bird in a counter Unmanned Air Systems (UAS) detection application by exploiting both spatial (video frame) and temporal (trajectory) information. We also demonstrated that the STARE performance approaches that of a State-of-the-Art deep neural network in classifying RF modulations, and outperforms Long Short-term Memory (LSTM) in a special case of Mackey Glass time series prediction. To demonstrate hardware efficiency, we designed and developed an FPGA implementation of the STARE algorithm to demonstrate its low-power and high-throughput operations. In addition, we illustrate an efficient structure for integrating a massively parallel implementation of the STARE algorithm for ASIC implementation.
Reservoir-Based Distributed Machine Learning for Edge Operation
Apr 01, 2021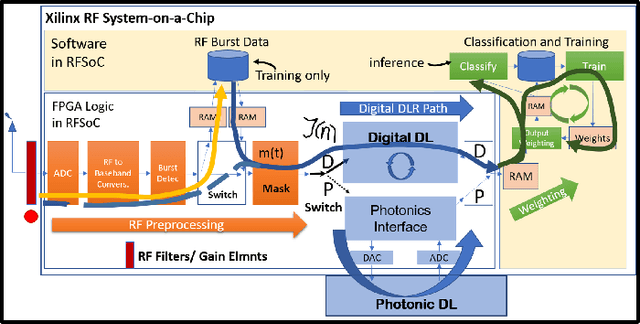
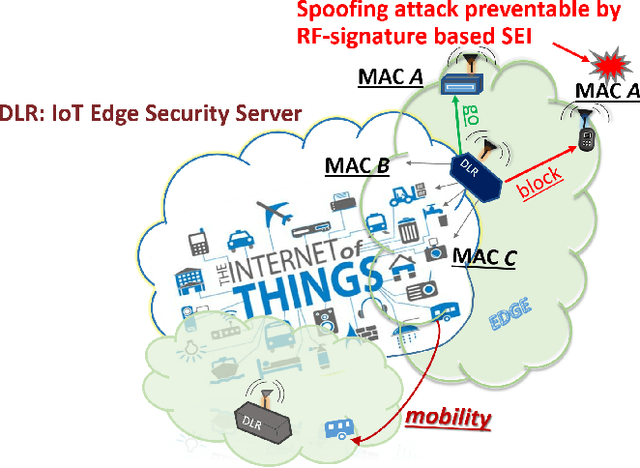
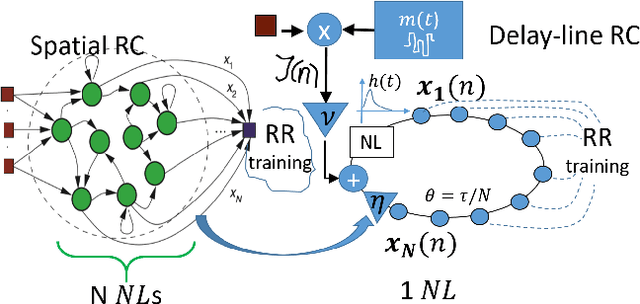
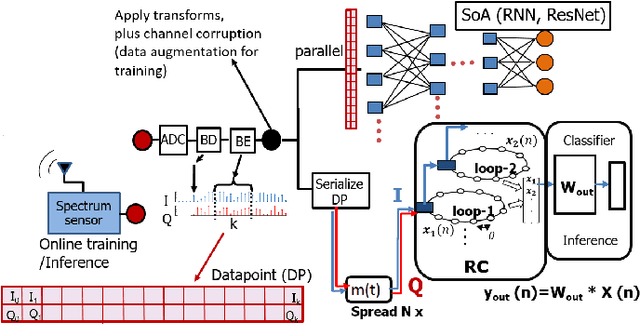
We introduce a novel design for in-situ training of machine learning algorithms built into smart sensors, and illustrate distributed training scenarios using radio frequency (RF) spectrum sensors. Current RF sensors at the Edge lack the computational resources to support practical, in-situ training for intelligent signal classification. We propose a solution using Deepdelay Loop Reservoir Computing (DLR), a processing architecture that supports machine learning algorithms on resource-constrained edge-devices by leveraging delayloop reservoir computing in combination with innovative hardware. DLR delivers reductions in form factor, hardware complexity and latency, compared to the State-ofthe- Art (SoA) neural nets. We demonstrate DLR for two applications: RF Specific Emitter Identification (SEI) and wireless protocol recognition. DLR enables mobile edge platforms to authenticate and then track emitters with fast SEI retraining. Once delay loops separate the data classes, traditionally complex, power-hungry classification models are no longer needed for the learning process. Yet, even with simple classifiers such as Ridge Regression (RR), the complexity grows at least quadratically with the input size. DLR with a RR classifier exceeds the SoA accuracy, while further reducing power consumption by leveraging the architecture of parallel (split) loops. To authenticate mobile devices across large regions, DLR can be trained in a distributed fashion with very little additional processing and a small communication cost, all while maintaining accuracy. We illustrate how to merge locally trained DLR classifiers in use cases of interest.
Deep Delay Loop Reservoir Computing for Specific Emitter Identification
Oct 13, 2020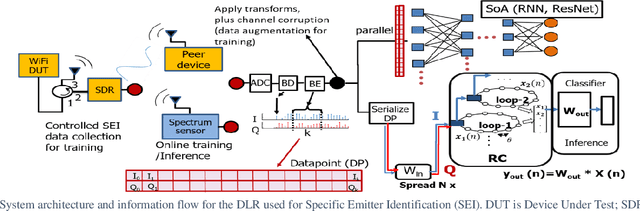
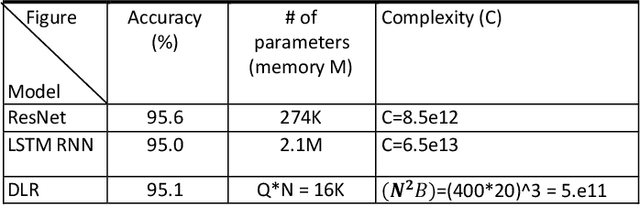
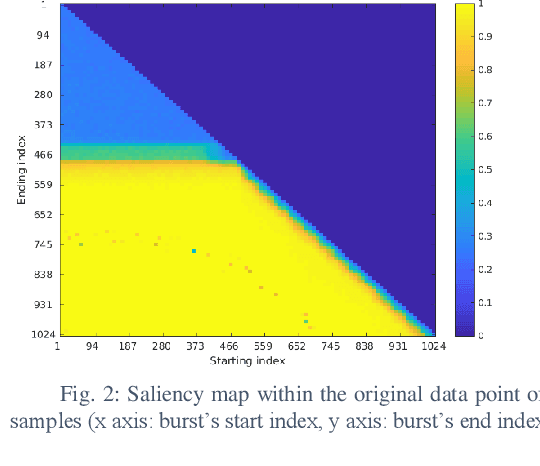
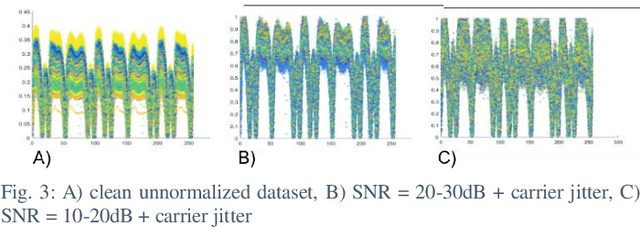
Current AI systems at the tactical edge lack the computational resources to support in-situ training and inference for situational awareness, and it is not always practical to leverage backhaul resources due to security, bandwidth, and mission latency requirements. We propose a solution through Deep delay Loop Reservoir Computing (DLR), a processing architecture supporting general machine learning algorithms on compact mobile devices by leveraging delay-loop (DL) reservoir computing in combination with innovative photonic hardware exploiting the inherent speed, and spatial, temporal and wavelength-based processing diversity of signals in the optical domain. DLR delivers reductions in form factor, hardware complexity, power consumption and latency, compared to State-of-the-Art . DLR can be implemented with a single photonic DL and a few electro-optical components. In certain cases multiple DL layers increase learning capacity of the DLR with no added latency. We demonstrate the advantages of DLR on the application of RF Specific Emitter Identification.