 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scenario-Based Platform for Testing Autonomous Vehicle Behavior Prediction Models in Simulation
Nov 14, 2021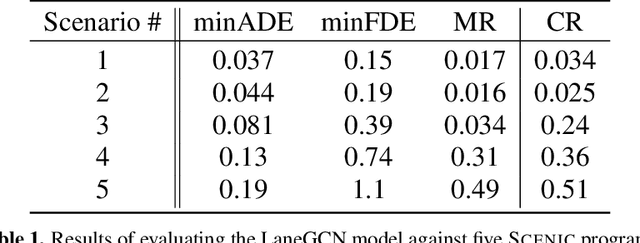

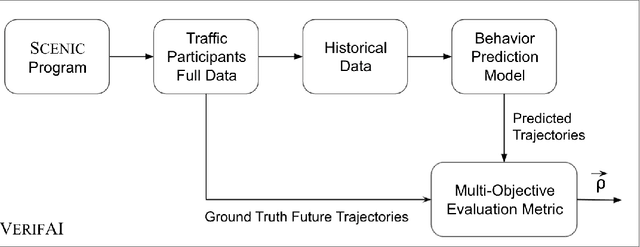
Behavior prediction remains one of the most challenging tasks in the autonomous vehicle (AV) software stack. Forecasting the future trajectories of nearby agents plays a critical role in ensuring road safety, as it equips AVs with the necessary information to plan safe routes of travel. However, these prediction models are data-driven and trained on data collected in real life that may not represent the full range of scenarios an AV can encounter. Hence, it is important that these prediction models are extensively tested in various test scenarios involving interactive behaviors prior to deployment. To support this need, we present a simulation-based testing platform which supports (1) intuitive scenario modeling with a probabilistic programming language called Scenic, (2) specifying a multi-objective evaluation metric with a partial priority ordering, (3) falsification of the provided metric, and (4) parallelization of simulations for scalable testing. As a part of the platform, we provide a library of 25 Scenic programs that model challenging test scenarios involving interactive traffic participant behaviors. We demonstrate the effectiveness and the scalability of our platform by testing a trained behavior prediction model and searching for failure scenarios.
Addressing the IEEE AV Test Challenge with Scenic and VerifAI
Aug 20, 2021

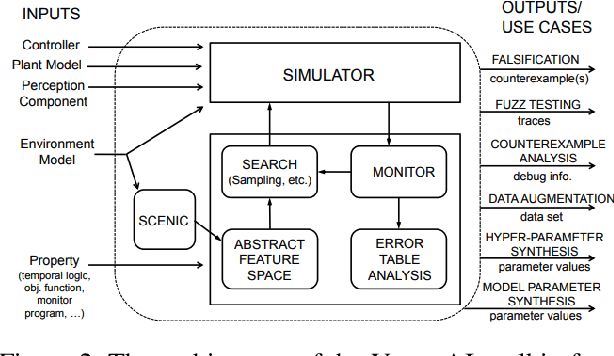
This paper summarizes our formal approach to testing autonomous vehicles (AVs) in simulation for the IEEE AV Test Challenge. We demonstrate a systematic testing framework leveraging our previous work on formally-driven simulation for intelligent cyber-physical systems. First, to model and generate interactive scenarios involving multiple agents, we used Scenic, a probabilistic programming language for specifying scenarios. A Scenic program defines an abstract scenario as a distribution over configurations of physical objects and their behaviors over time. Sampling from an abstract scenario yields many different concrete scenarios which can be run as test cases for the AV. Starting from a Scenic program encoding an abstract driving scenario, we can use the VerifAI toolkit to search within the scenario for failure cases with respect to multiple AV evaluation metrics. We demonstrate the effectiveness of our testing framework by identifying concrete failure scenarios for an open-source autopilot, Apollo, starting from a variety of realistic traffic scenarios.
Parallel and Multi-Objective Falsification with Scenic and VerifAI
Jul 09, 2021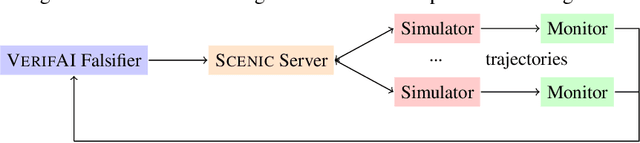

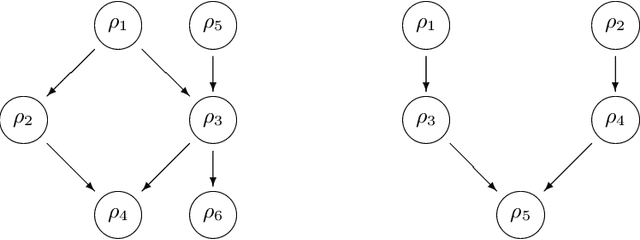
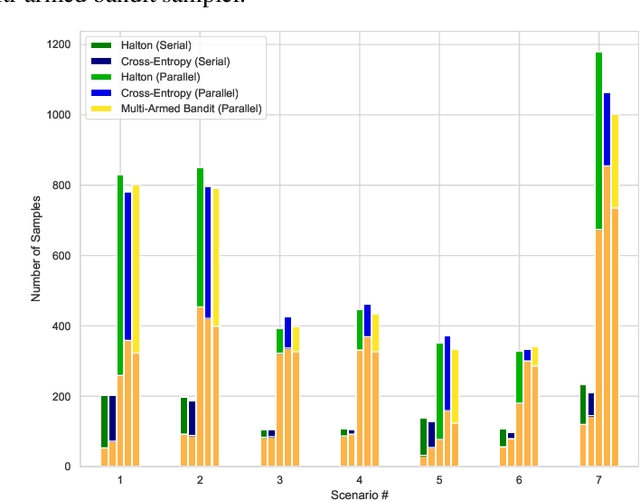
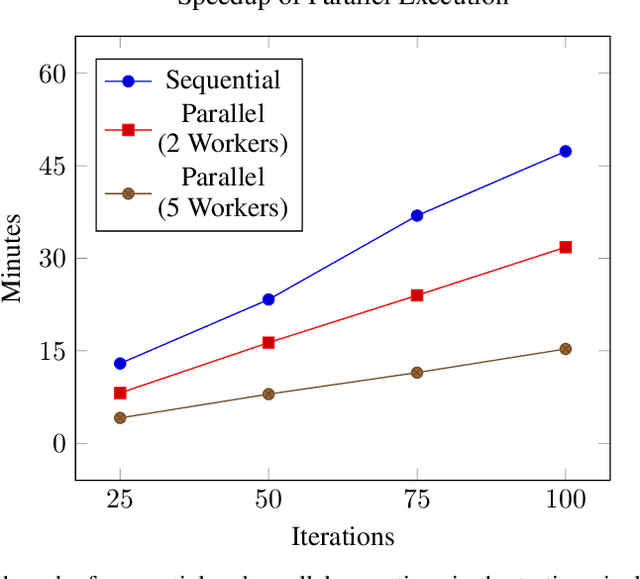
Falsification has emerged as an important tool for simulation-based verification of autonomous systems. In this paper, we present extensions to the Scenic scenario specification language and VerifAI toolkit that improve the scalability of sampling-based falsification methods by using parallelism and extend falsification to multi-objective specifications. We first present a parallelized framework that is interfaced with both the simulation and sampling capabilities of Scenic and the falsification capabilities of VerifAI, reducing the execution time bottleneck inherently present in simulation-based testing. We then present an extension of VerifAI's falsification algorithms to support multi-objective optimization during sampling, using the concept of rulebooks to specify a preference ordering over multiple metrics that can be used to guide the counterexample search process. Lastly, we evaluate the benefits of these extensions with a comprehensive set of benchmarks written in the Scenic language.