 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling Towards Fast Graph Representation Learning
Oct 21, 2018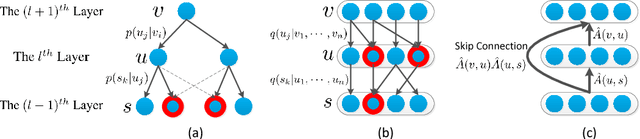
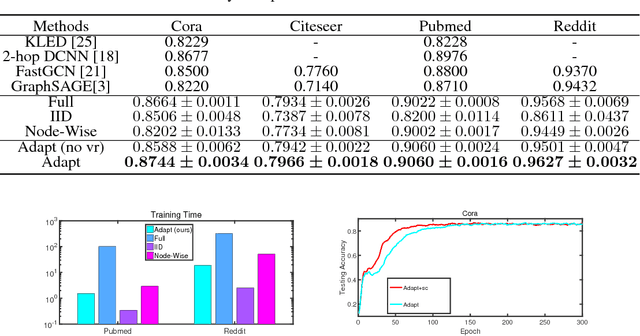
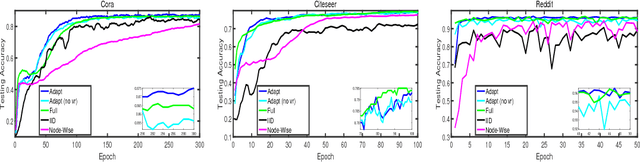

Graph Convolutional Networks (GCNs) have become a crucial tool on learning representations of graph vertices. The main challenge of adapting GCNs on large-scale graphs is the scalability issue that it incurs heavy cost both in computation and memory due to the uncontrollable neighborhood expansion across layers. In this paper, we accelerate the training of GCNs through developing an adaptive layer-wise sampling method. By constructing the network layer by layer in a top-down passway, we sample the lower layer conditioned on the top one, where the sampled neighborhoods are shared by different parent nodes and the over expansion is avoided owing to the fixed-size sampling. More importantly, the proposed sampler is adaptive and applicable for explicit variance reduction, which in turn enhances the training of our method. Furthermore, we propose a novel and economical approach to promote the message passing over distant nodes by applying skip connections. Intensive experiments on several benchmarks verify the effectiveness of our method regarding the classification accuracy while enjoying faster convergence speed.
Hyperparameter Learning via Distributional Transfer
Oct 15, 2018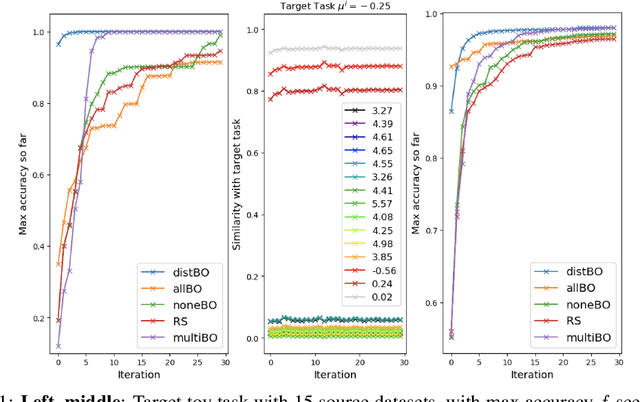
Bayesian optimisation is a popular technique for hyperparameter learning but typically requires initial 'exploration' even in cases where potentially similar prior tasks have been solved. We propose to transfer information across tasks using kernel embeddings of distributions of training datasets used in those tasks. The resulting method has a faster convergence compared to existing baselines, in some cases requiring only a few evaluations of the target objective.
Dual Reconstruction Nets for Image Super-Resolution with Gradient Sensitive Loss
Sep 19, 2018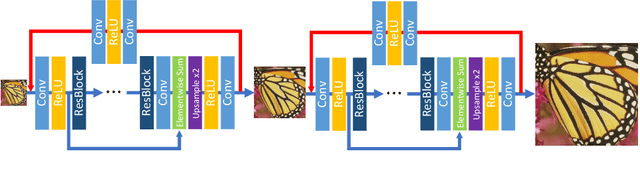
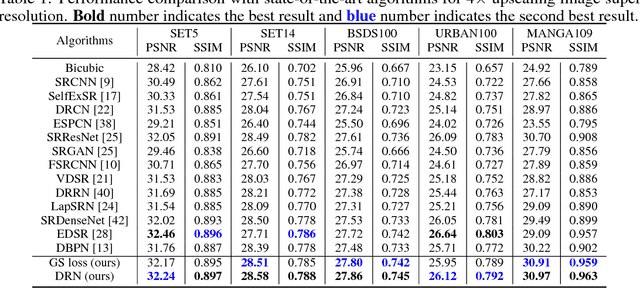
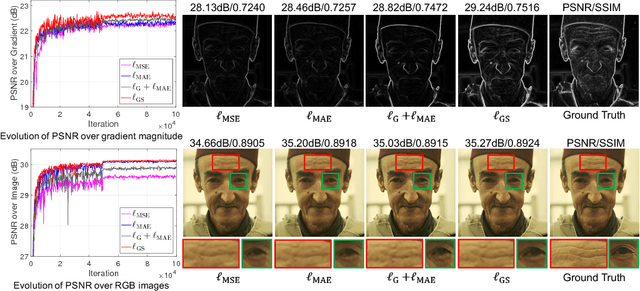
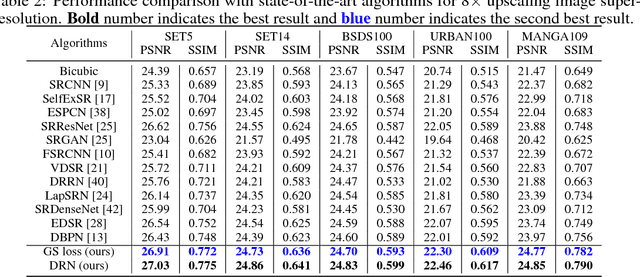
Deep neural networks have exhibited promising performance in image super-resolution (SR) due to the power in learning the non-linear mapping from low-resolution (LR) images to high-resolution (HR) images. However, most deep learning methods employ feed-forward architectures, and thus the dependencies between LR and HR images are not fully exploited, leading to limited learning performance. Moreover, most deep learning based SR methods apply the pixel-wise reconstruction error as the loss, which, however, may fail to capture high-frequency information and produce perceptually unsatisfying results, whilst the recent perceptual loss relies on some pre-trained deep model and they may not generalize well. In this paper, we introduce a mask to separate the image into low- and high-frequency parts based on image gradient magnitude, and then devise a gradient sensitive loss to well capture the structures in the image without sacrificing the recovery of low-frequency content. Moreover, by investigating the duality in SR, we develop a dual reconstruction network (DRN) to improve the SR performance. We provide theoretical analysis on the generalization performance of our method and demonstrate its effectiveness and superiority with thorough experiments.
Controllable Image-to-Video Translation: A Case Study on Facial Expression Generation
Aug 09, 2018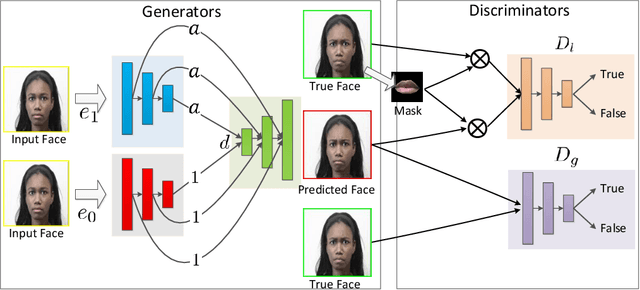


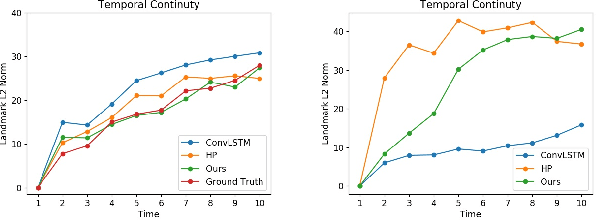
The recent advances in deep learning have made it possible to generate photo-realistic images by using neural networks and even to extrapolate video frames from an input video clip. In this paper, for the sake of both furthering this exploration and our own interest in a realistic application, we study image-to-video translation and particularly focus on the videos of facial expressions. This problem challenges the deep neural networks by another temporal dimension comparing to the image-to-image translation. Moreover, its single input image fails most existing video generation methods that rely on recurrent models. We propose a user-controllable approach so as to generate video clips of various lengths from a single face image. The lengths and types of the expressions are controlled by users. To this end, we design a novel neural network architecture that can incorporate the user input into its skip connections and propose several improvements to the adversarial training method for the neural network. Experiments and user studies verify the effectiveness of our approach. Especially, we would like to highlight that even for the face images in the wild (downloaded from the Web and the authors' own photos), our model can generate high-quality facial expression videos of which about 50\% are labeled as real by Amazon Mechanical Turk workers.
Weakly Supervised Deep Learning for Thoracic Disease Classification and Localization on Chest X-rays
Jul 16, 2018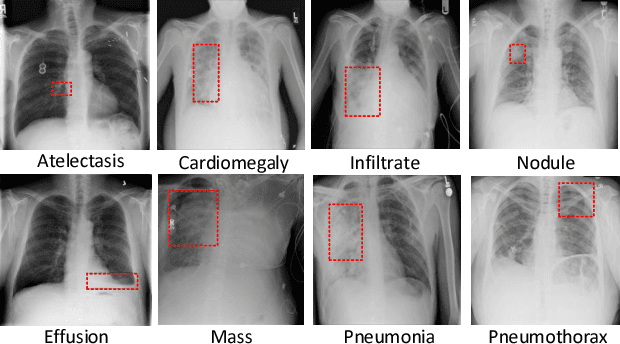
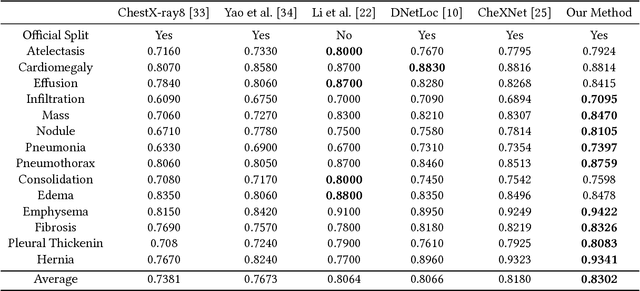
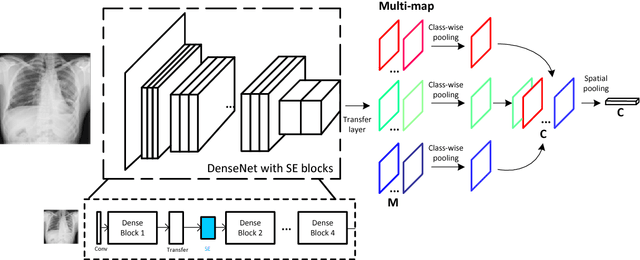
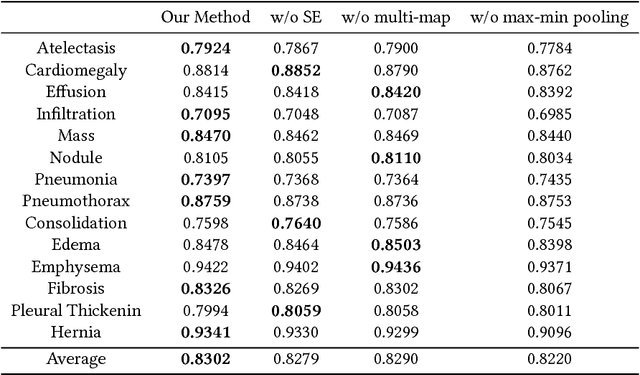
Chest X-rays is one of the most commonly available and affordable radiological examinations in clinical practice. While detecting thoracic diseases on chest X-rays is still a challenging task for machine intelligence, due to 1) the highly varied appearance of lesion areas on X-rays from patients of different thoracic disease and 2) the shortage of accurate pixel-level annotations by radiologists for model training. Existing machine learning methods are unable to deal with the challenge that thoracic diseases usually happen in localized disease-specific areas. In this article, we propose a weakly supervised deep learning framework equipped with squeeze-and-excitation blocks, multi-map transfer, and max-min pooling for classifying thoracic diseases as well as localizing suspicious lesion regions. The comprehensive experiments and discussions are performed on the ChestX-ray14 dataset. Both numerical and visual results have demonstrated the effectiveness of the proposed model and its better performance against the state-of-the-art pipelines.
On the Acceleration of L-BFGS with Second-Order Information and Stochastic Batches
Jul 14, 2018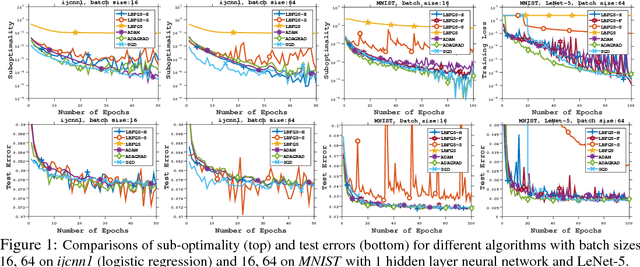
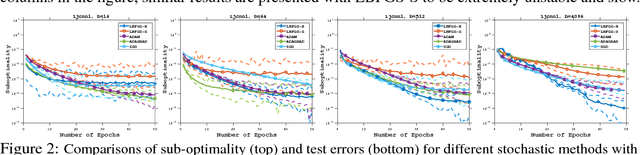
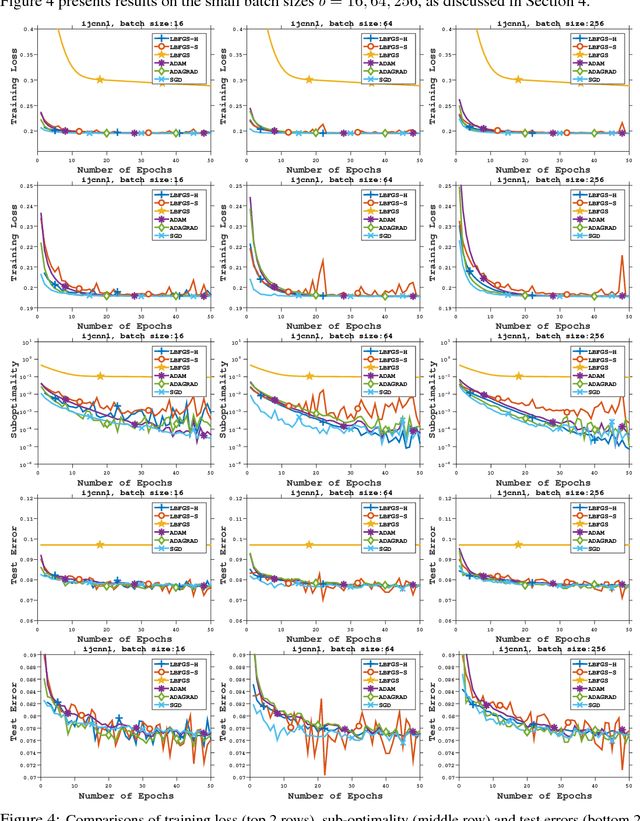
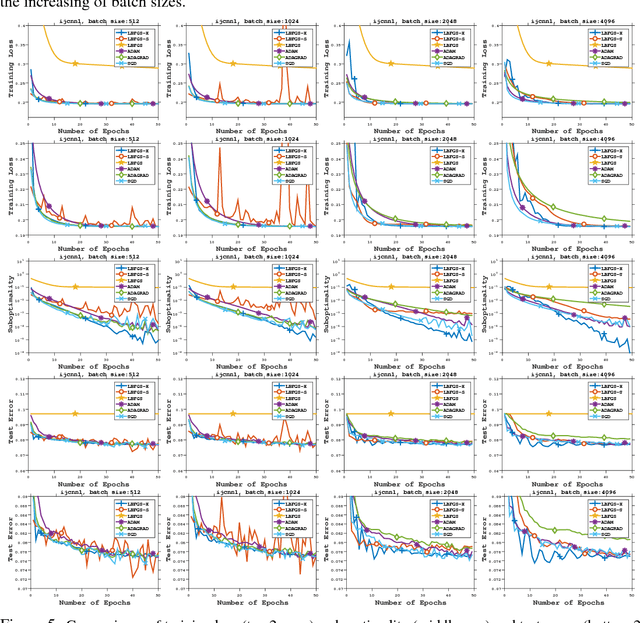
This paper proposes a framework of L-BFGS based on the (approximate) second-order information with stochastic batches, as a novel approach to the finite-sum minimization problems. Different from the classical L-BFGS where stochastic batches lead to instability, we use a smooth estimate for the evaluations of the gradient differences while achieving acceleration by well-scaling the initial Hessians. We provide theoretical analyses for both convex and nonconvex cases. In addition, we demonstrate that within the popular applications of least-square and cross-entropy losses, the algorithm admits a simple implementation in the distributed environment. Numerical experiments support the efficiency of our algorithms.
Error Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization
Jun 21, 2018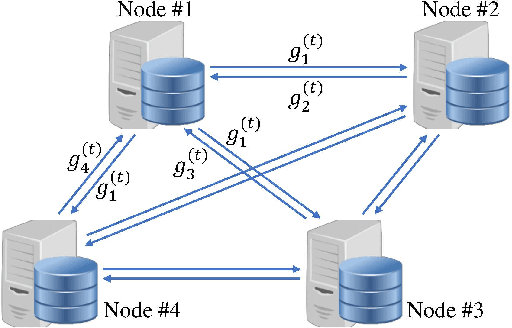
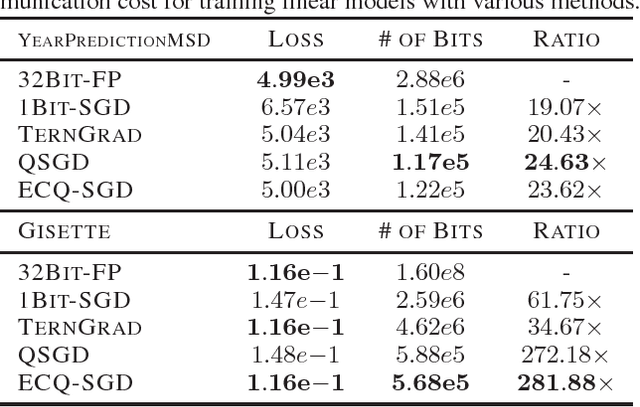
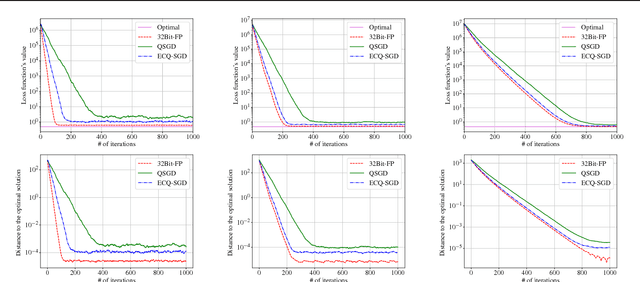
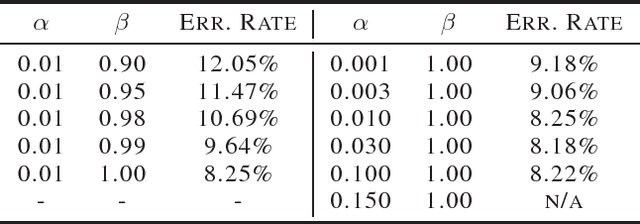
Large-scale distributed optimization is of great importance in various applications. For data-parallel based distributed learning, the inter-node gradient communication often becomes the performance bottleneck. In this paper, we propose the error compensated quantized stochastic gradient descent algorithm to improve the training efficiency. Local gradients are quantized to reduce the communication overhead, and accumulated quantization error is utilized to speed up the convergence. Furthermore, we present theoretical analysis on the convergence behaviour, and demonstrate its advantage over competitors. Extensive experiments indicate that our algorithm can compress gradients by a factor of up to two magnitudes without performance degradation.
Nonparametric Topic Modeling with Neural Inference
Jun 18, 2018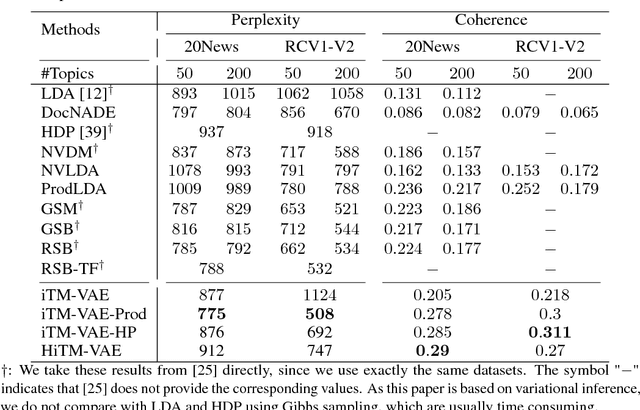

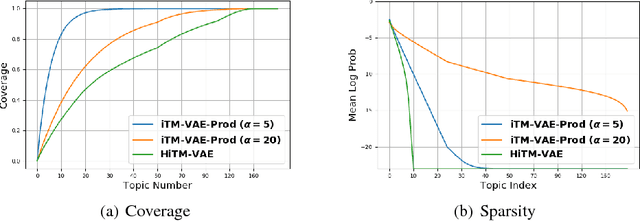
This work focuses on combining nonparametric topic models with Auto-Encoding Variational Bayes (AEVB). Specifically, we first propose iTM-VAE, where the topics are treated as trainable parameters and the document-specific topic proportions are obtained by a stick-breaking construction. The inference of iTM-VAE is modeled by neural networks such that it can be computed in a simple feed-forward manner. We also describe how to introduce a hyper-prior into iTM-VAE so as to model the uncertainty of the prior parameter. Actually, the hyper-prior technique is quite general and we show that it can be applied to other AEVB based models to alleviate the {\it collapse-to-prior} problem elegantly. Moreover, we also propose HiTM-VAE, where the document-specific topic distributions are generated in a hierarchical manner. HiTM-VAE is even more flexible and can generate topic distributions with better variability. Experimental results on 20News and Reuters RCV1-V2 datasets show that the proposed models outperform the state-of-the-art baselines significantly. The advantages of the hyper-prior technique and the hierarchical model construction are also confirmed by experiments.
Adversarial Learning with Local Coordinate Coding
Jun 14, 2018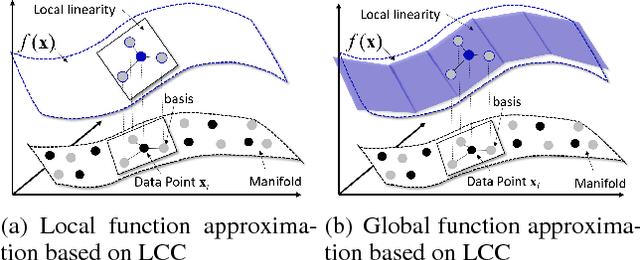
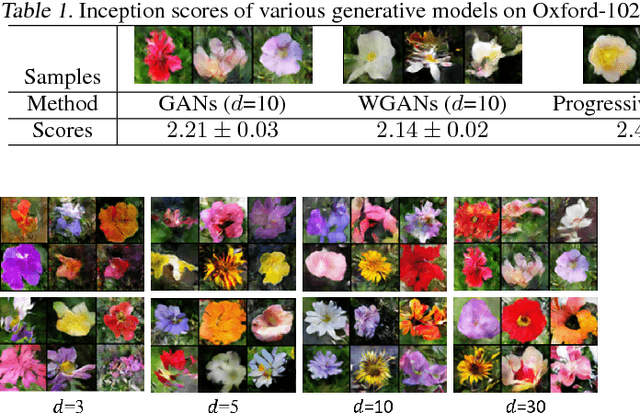
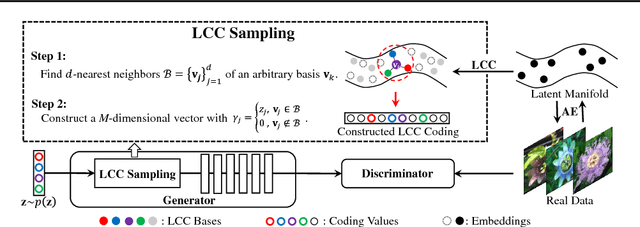
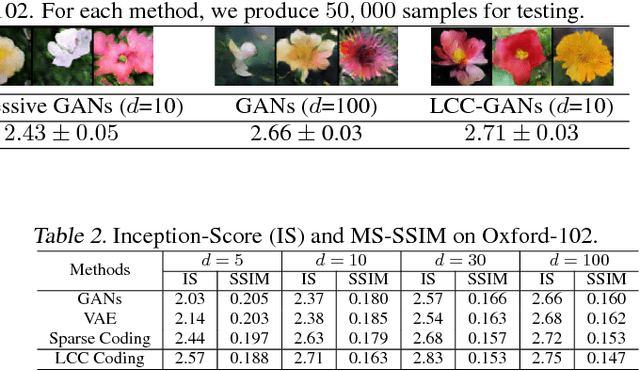
Generative adversarial networks (GANs) aim to generate realistic data from some prior distribution (e.g., Gaussian noises). However, such prior distribution is often independent of real data and thus may lose semantic information (e.g., geometric structure or content in images) of data. In practice, the semantic information might be represented by some latent distribution learned from data, which, however, is hard to be used for sampling in GANs. In this paper, rather than sampling from the pre-defined prior distribution, we propose a Local Coordinate Coding (LCC) based sampling method to improve GANs. We derive a generalization bound for LCC based GANs and prove that a small dimensional input is sufficient to achieve good generalization. Extensive experiments on various real-world datasets demonstrate the effectiveness of the proposed method.
Adaptive Cost-sensitive Online Classification
Apr 06, 2018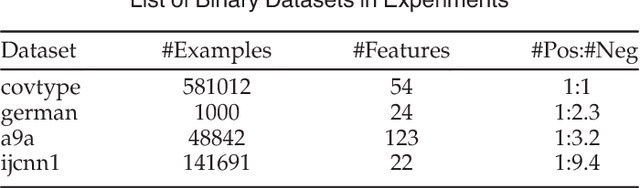
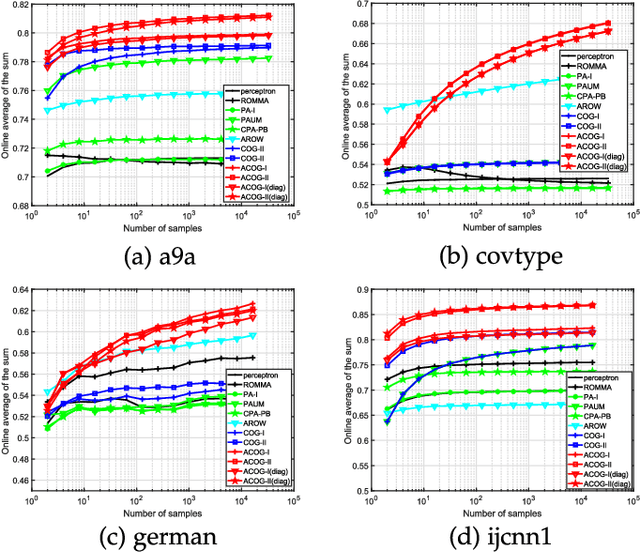
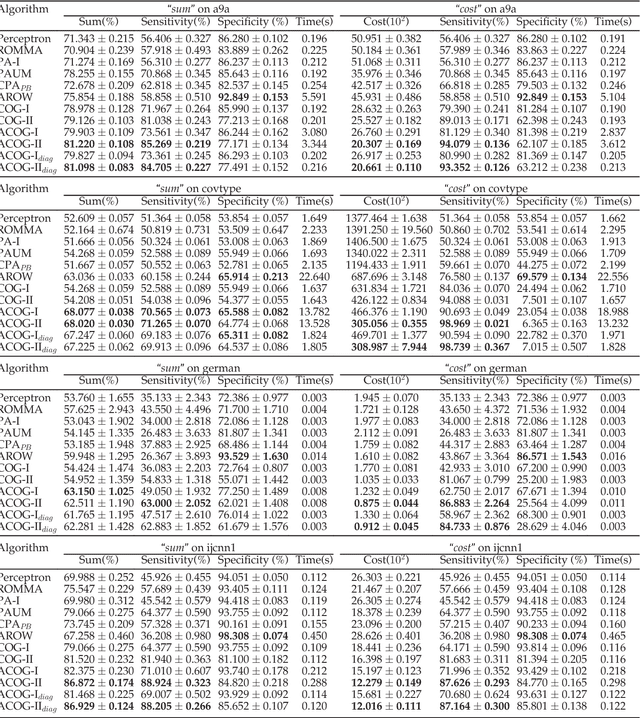
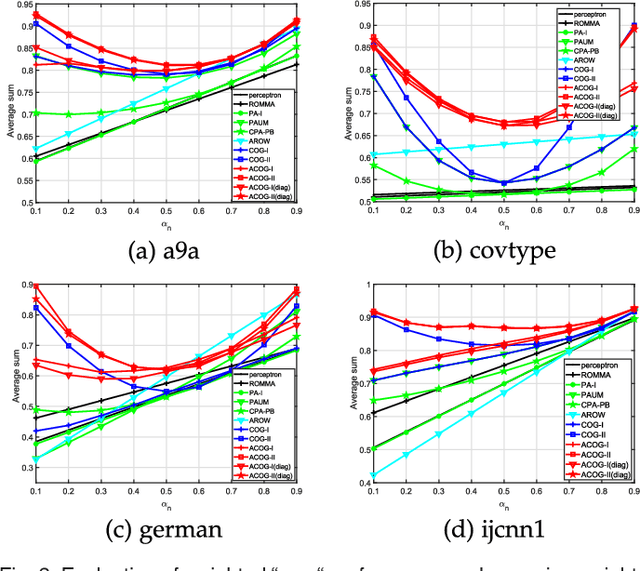
Cost-Sensitive Online Classification has drawn extensive attention in recent years, where the main approach is to directly online optimize two well-known cost-sensitive metrics: (i) weighted sum of sensitivity and specificity; (ii) weighted misclassification cost. However, previous existing methods only considered first-order information of data stream. It is insufficient in practice, since many recent studies have proved that incorporating second-order information enhances the prediction performance of classification models. Thus, we propose a family of cost-sensitive online classification algorithms with adaptive regularization in this paper. We theoretically analyze the proposed algorithms and empirically validate their effectiveness and properties in extensive experiments. Then, for better trade off between the performance and efficiency, we further introduce the sketching technique into our algorithms, which significantly accelerates the computational speed with quite slight performance loss. Finally, we apply our algorithms to tackle several online anomaly detection tasks from real world. Promising results prove that the proposed algorithms are effective and efficient in solving cost-sensitive online classification problems in various real-world domains.