 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiShade: Activating Overshadowed Knowledge to Guide Multi-Hop Reasoning in Large Language Models
Jan 12, 2026In multi-hop reasoning, multi-round retrieval-augmented generation (RAG) methods typically rely on LLM-generated content as the retrieval query. However, these approaches are inherently vulnerable to knowledge overshadowing - a phenomenon where critical information is overshadowed during generation. As a result, the LLM-generated content may be incomplete or inaccurate, leading to irrelevant retrieval and causing error accumulation during the iteration process. To address this challenge, we propose ActiShade, which detects and activates overshadowed knowledge to guide large language models (LLMs) in multi-hop reasoning. Specifically, ActiShade iteratively detects the overshadowed keyphrase in the given query, retrieves documents relevant to both the query and the overshadowed keyphrase, and generates a new query based on the retrieved documents to guide the next-round iteration. By supplementing the overshadowed knowledge during the formulation of next-round queries while minimizing the introduction of irrelevant noise, ActiShade reduces the error accumulation caused by knowledge overshadowing. Extensive experiments show that ActiShade outperforms existing methods across multiple datasets and LLMs.
Curator: Efficient Vector Search with Low-Selectivity Filters
Jan 07, 2026Embedding-based dense retrieval has become the cornerstone of many critical applications, where approximate nearest neighbor search (ANNS) queries are often combined with filters on labels such as dates and price ranges. Graph-based indexes achieve state-of-the-art performance on unfiltered ANNS but encounter connectivity breakdown on low-selectivity filtered queries, where qualifying vectors become sparse and the graph structure among them fragments. Recent research proposes specialized graph indexes that address this issue by expanding graph degree, which incurs prohibitively high construction costs. Given these inherent limitations of graph-based methods, we argue for a dual-index architecture and present Curator, a partition-based index that complements existing graph-based approaches for low-selectivity filtered ANNS. Curator builds specialized indexes for different labels within a shared clustering tree, where each index adapts to the distribution of its qualifying vectors to ensure efficient search while sharing structure to minimize memory overhead. The system also supports incremental updates and handles arbitrary complex predicates beyond single-label filters by efficiently constructing temporary indexes on the fly. Our evaluation demonstrates that integrating Curator with state-of-the-art graph indexes reduces low-selectivity query latency by up to 20.9x compared to pre-filtering fallback, while increasing construction time and memory footprint by only 5.5% and 4.3%, respectively.
cuPilot: A Strategy-Coordinated Multi-agent Framework for CUDA Kernel Evolution
Dec 23, 2025Optimizing CUDA kernels is a challenging and labor-intensive task, given the need for hardware-software co-design expertise and the proprietary nature of high-performance kernel libraries. While recent large language models (LLMs) combined with evolutionary algorithms show promise in automatic kernel optimization, existing approaches often fall short in performance due to their suboptimal agent designs and mismatched evolution representations. This work identifies these mismatches and proposes cuPilot, a strategy-coordinated multi-agent framework that introduces strategy as an intermediate semantic representation for kernel evolution. Key contributions include a strategy-coordinated evolution algorithm, roofline-guided prompting, and strategy-level population initialization. Experimental results show that the generated kernels by cuPilot achieve an average speed up of 3.09$\times$ over PyTorch on a benchmark of 100 kernels. On the GEMM tasks, cuPilot showcases sophisticated optimizations and achieves high utilization of critical hardware units. The generated kernels are open-sourced at https://github.com/champloo2878/cuPilot-Kernels.git.
Efficient Agent: Optimizing Planning Capability for Multimodal Retrieval Augmented Generation
Aug 12, 2025Multimodal Retrieval-Augmented Generation (mRAG) has emerged as a promising solution to address the temporal limitations of Multimodal Large Language Models (MLLMs) in real-world scenarios like news analysis and trending topics. However, existing approaches often suffer from rigid retrieval strategies and under-utilization of visual information. To bridge this gap, we propose E-Agent, an agent framework featuring two key innovations: a mRAG planner trained to dynamically orchestrate multimodal tools based on contextual reasoning, and a task executor employing tool-aware execution sequencing to implement optimized mRAG workflows. E-Agent adopts a one-time mRAG planning strategy that enables efficient information retrieval while minimizing redundant tool invocations. To rigorously assess the planning capabilities of mRAG systems, we introduce the Real-World mRAG Planning (RemPlan) benchmark. This novel benchmark contains both retrieval-dependent and retrieval-independent question types, systematically annotated with essential retrieval tools required for each instance. The benchmark's explicit mRAG planning annotations and diverse question design enhance its practical relevance by simulating real-world scenarios requiring dynamic mRAG decisions. Experiments across RemPlan and three established benchmarks demonstrate E-Agent's superiority: 13% accuracy gain over state-of-the-art mRAG methods while reducing redundant searches by 37%.
LLM-based Multi-Agent Copilot for Quantum Sensor
Aug 07, 2025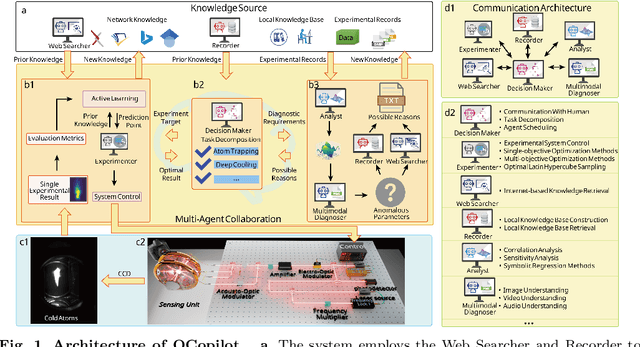
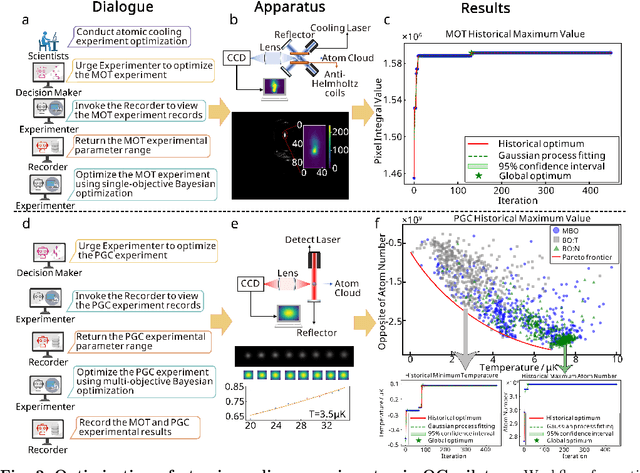
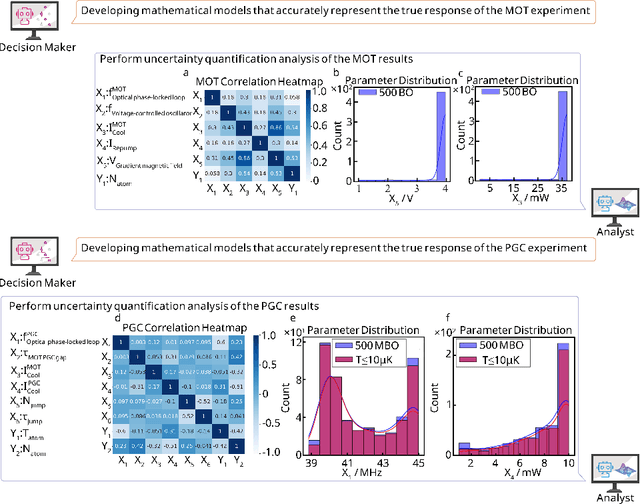
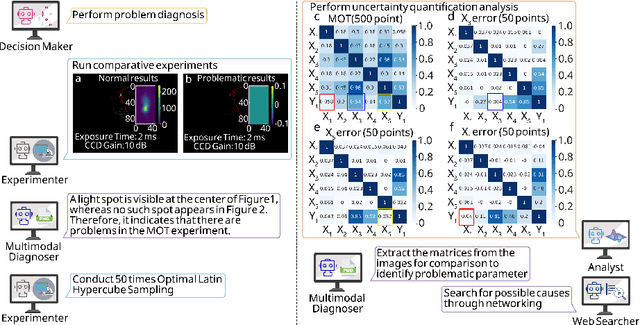
Large language models (LLM) exhibit broad utility but face limitations in quantum sensor development, stemming from interdisciplinary knowledge barriers and involving complex optimization processes. Here we present QCopilot, an LLM-based multi-agent framework integrating external knowledge access, active learning, and uncertainty quantification for quantum sensor design and diagnosis. Comprising commercial LLMs with few-shot prompt engineering and vector knowledge base, QCopilot employs specialized agents to adaptively select optimization methods, automate modeling analysis, and independently perform problem diagnosis. Applying QCopilot to atom cooling experiments, we generated 10${}^{\rm{8}}$ sub-$\rm{\mu}$K atoms without any human intervention within a few hours, representing $\sim$100$\times$ speedup over manual experimentation. Notably, by continuously accumulating prior knowledge and enabling dynamic modeling, QCopilot can autonomously identify anomalous parameters in multi-parameter experimental settings. Our work reduces barriers to large-scale quantum sensor deployment and readily extends to other quantum information systems.
SALM: Spatial Audio Language Model with Structured Embeddings for Understanding and Editing
Jul 22, 2025Spatial audio understanding is essential for accurately perceiving and interpreting acoustic environments. However, existing audio-language models struggle with processing spatial audio and perceiving spatial acoustic scenes. We introduce the Spatial Audio Language Model (SALM), a novel framework that bridges spatial audio and language via multi-modal contrastive learning. SALM consists of a text encoder and a dual-branch audio encoder, decomposing spatial sound into semantic and spatial components through structured audio embeddings. Key features of SALM include seamless alignment of spatial and text representations, separate and joint extraction of spatial and semantic information, zero-shot direction classification and robust support for spatial audio editing. Experimental results demonstrate that SALM effectively captures and aligns cross-modal representations. Furthermore, it supports advanced editing capabilities, such as altering directional audio using text-based embeddings.
Dual-view Spatio-Temporal Feature Fusion with CNN-Transformer Hybrid Network for Chinese Isolated Sign Language Recognition
Jun 08, 2025Due to the emergence of many sign language datasets, isolated sign language recognition (ISLR) has made significant progress in recent years. In addition, the development of various advanced deep neural networks is another reason for this breakthrough. However, challenges remain in applying the technique in the real world. First, existing sign language datasets do not cover the whole sign vocabulary. Second, most of the sign language datasets provide only single view RGB videos, which makes it difficult to handle hand occlusions when performing ISLR. To fill this gap, this paper presents a dual-view sign language dataset for ISLR named NationalCSL-DP, which fully covers the Chinese national sign language vocabulary. The dataset consists of 134140 sign videos recorded by ten signers with respect to two vertical views, namely, the front side and the left side. Furthermore, a CNN transformer network is also proposed as a strong baseline and an extremely simple but effective fusion strategy for prediction. Extensive experiments were conducted to prove the effectiveness of the datasets as well as the baseline. The results show that the proposed fusion strategy can significantly increase the performance of the ISLR, but it is not easy for the sequence-to-sequence model, regardless of whether the early-fusion or late-fusion strategy is applied, to learn the complementary features from the sign videos of two vertical views.
Stereographic Multi-Try Metropolis Algorithms for Heavy-tailed Sampling
May 18, 2025Markov chain Monte Carlo (MCMC) methods for sampling from heavy-tailed distributions present unique challenges, particularly in high dimensions. Multi-proposal MCMC algorithms have recently gained attention for their potential to improve performance, especially through parallel implementation on modern hardware. This paper introduces a novel family of gradient-free MCMC algorithms that combine the multi-try Metropolis (MTM) with stereographic MCMC framework, specifically designed for efficient sampling from heavy-tailed targets. The proposed stereographic multi-try Metropolis (SMTM) algorithm not only outperforms traditional Euclidean MTM and existing stereographic random-walk Metropolis methods, but also avoids the pathological convergence behavior often observed in MTM and demonstrates strong robustness to tuning. These properties are supported by scaling analysis and extensive simulation studies.
Review-Instruct: A Review-Driven Multi-Turn Conversations Generation Method for Large Language Models
May 16, 2025



The effectiveness of large language models (LLMs) in conversational AI is hindered by their reliance on single-turn supervised fine-tuning (SFT) data, which limits contextual coherence in multi-turn dialogues. Existing methods for generating multi-turn dialogue data struggle to ensure both diversity and quality in instructions. To address this, we propose Review-Instruct, a novel framework that synthesizes multi-turn conversations through an iterative "Ask-Respond-Review" process involving three agent roles: a Candidate, multiple Reviewers, and a Chairman. The framework iteratively refines instructions by incorporating Reviewer feedback, enhancing dialogue diversity and difficulty. We construct a multi-turn dataset using the Alpaca dataset and fine-tune the LLaMA2-13B model. Evaluations on MT-Bench, MMLU-Pro, and Auto-Arena demonstrate significant improvements, achieving absolute gains of 2.9\% on MMLU-Pro and 2\% on MT-Bench compared to prior state-of-the-art models based on LLaMA2-13B. Ablation studies confirm the critical role of the Review stage and the use of multiple Reviewers in boosting instruction diversity and difficulty. Our work highlights the potential of review-driven, multi-agent frameworks for generating high-quality conversational data at scale.
Enhanced Data-driven Topology Design Methodology with Multi-level Mesh and Correlation-based Mutation for Stress-related Multi-objective Optimization
Apr 21, 2025Topology optimization (TO) serves as a widely applied structural design approach to tackle various engineering problems. Nevertheless, sensitivity-based TO methods usually struggle with solving strongly nonlinear optimization problems. By leveraging high capacity of deep generative model, which is an influential machine learning technique, the sensitivity-free data-driven topology design (DDTD) methodology is regarded as an effective means of overcoming these issues. The DDTD methodology depends on initial dataset with a certain regularity, making its results highly sensitive to initial dataset quality. This limits its effectiveness and generalizability, especially for optimization problems without priori information. In this research, we proposed a multi-level mesh DDTD-based method with correlation-based mutation module to escape from the limitation of the quality of the initial dataset on the results and enhance computational efficiency. The core is to employ a correlation-based mutation module to assign new geometric features with physical meaning to the generated data, while utilizing a multi-level mesh strategy to progressively enhance the refinement of the structural representation, thus avoiding the maintenance of a high degree-of-freedom (DOF) representation throughout the iterative process. The proposed multi-level mesh DDTD-based method can be driven by a low quality initial dataset without the need for time-consuming construction of a specific dataset, thus significantly increasing generality and reducing application difficulty, while further lowering computational cost of DDTD methodology. Various comparison experiments with the traditional sensitivity-based TO methods on stress-related strongly nonlinear problems demonstrate the generality and effectiveness of the proposed method.