 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL-2.0 Technical Report
Jun 09, 2026We introduce Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts (MoE) multimodal foundation model designed to advance long-video understanding and agentic intelligence. To address the challenges of ultra-long contexts, information redundancy, and prohibitive computational costs inherent in hour-level videos, Keye-VL-2.0 is the first to adapt DeepSeek Sparse Attention (DSA) to GQA-based multimodal architectures, enabling lossless 256K context processing while capturing critical frames and long-range temporal dependencies. This architecture is underpinned by a highly optimized training and inference infrastructure, including scalable video I/O, heterogeneous ViT-LM parallelism, and custom DSA kernels that significantly maximize throughput and minimize computational overhead. Furthermore, to overcome the algorithmic dilemma of catastrophic forgetting during multi-task alignment, we introduce Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) paired with Context-RL and Video-RL. By distilling dense token-level teacher feedback from on-policy rollouts back into the MoE backbone, which activates only 3B parameters, Keye-VL-2.0 natively empowers advanced agent collaboration across Code, Tool, and Search scenarios with multimodal self-correction. Extensive evaluations across video understanding, temporal grounding, reasoning, STEM, and agent benchmarks demonstrate that Keye-VL-2.0-30B-A3B achieves state-of-the-art performance among models of similar scale, particularly excelling in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench. We release our model checkpoints to accelerate community progress toward scalable and robust multimodal agentic applications.
Ultra Flash: Scaling Real-Time Streaming Video Generation to High Resolutions
Jun 08, 2026While recent autoregressive video diffusion models achieve remarkable streaming quality, they remain confined to low resolutions (e.g., 480P), leaving efficient, scalable, real-time high-resolution video generation a fundamental open challenge. To bridge this gap, we present Ultra Flash, a cascaded streaming framework capable of real-time high-resolution video generation. Ultra Flash achieves ~30 FPS at 1K resolution and ~18 FPS at 2K resolution on a single GPU through three key contributions: (1) an architecture-preserving T2V-to-TV2V super-resolution training paradigm coupled with an AIGC-oriented data degradation pipeline that effectively preserves the generative capability of the base model, enabling enhanced high-resolution detail when cascaded after mainstream low-resolution generative models; (2) a causal streaming latent upsampler paired with a high-resolution decoder, which enhances spatiotemporal coherence while enabling efficient latent spatial scaling and precise high-resolution decoding with negligible computational overhead; and (3) a cascade high-resolution streaming video generation optimization scheme that first performs hybrid-reward-enhanced sparse causalization and single-step distillation of the super-resolution model, then introduces cascaded streaming self-forcing preference optimization with dynamic cache management, jointly enhancing overall coherence, improving quality, and enabling real-time high-resolution streaming video generation. Extensive experiments demonstrate that Ultra Flash reliably produces ultra-high-resolution streaming video while maintaining state-of-the-art visual quality and superior efficiency.
CLARITY: A Framework and Benchmark for Conversational Language Ambiguity and Unanswerability in Interactive NL2SQL Systems
Apr 24, 2026NL2SQL systems deployed in industry settings often encounter ambiguous or unanswerable queries, particularly in interactive scenarios with incomplete user clarification. Existing benchmarks typically assume a single source of ambiguity and rely on user interaction for resolution, overlooking realistic failure modes. We introduce Clarity, a framework for automatically generating an NL2SQL benchmark with multi-faceted ambiguities and diverse user behaviors across both single- and multi-turn settings. Using a constraint-driven pipeline, Clarity transforms executable SQL into ambiguous queries, augmented with grounded conversational continuations and schema-level metadata. Empirical evaluation on Spider and BIRD shows that leading NL2SQL systems, including those based on strong LLMs, suffer significant performance degradation under multi-faceted ambiguity. While these systems often detect ambiguity, they struggle to accurately localize and resolve the underlying schema-level sources. Our results highlight the need for more robust ambiguity detection and resolution in industry-grade NL2SQL systems.
MAR-GRPO: Stabilized GRPO for AR-diffusion Hybrid Image Generation
Apr 08, 2026Reinforcement learning (RL) has been successfully applied to autoregressive (AR) and diffusion models. However, extending RL to hybrid AR-diffusion frameworks remains challenging due to interleaved inference and noisy log-probability estimation. In this work, we study masked autoregressive models (MAR) and show that the diffusion head plays a critical role in training dynamics, often introducing noisy gradients that lead to instability and early performance saturation. To address this issue, we propose a stabilized RL framework for MAR. We introduce multi-trajectory expectation (MTE), which estimates the optimization direction by averaging over multiple diffusion trajectories, thereby reducing diffusion-induced gradient noise. To avoid over-smoothing, we further estimate token-wise uncertainty from multiple trajectories and apply multi-trajectory optimization only to the top-k% uncertain tokens. In addition, we introduce a consistency-aware token selection strategy that filters out AR tokens that are less aligned with the final generated content. Extensive experiments across multiple benchmarks demonstrate that our method consistently improves visual quality, training stability, and spatial structure understanding over baseline GRPO and pre-RL models. Code is available at: https://github.com/AMAP-ML/mar-grpo.
Drift-AR: Single-Step Visual Autoregressive Generation via Anti-Symmetric Drifting
Mar 30, 2026Autoregressive (AR)-Diffusion hybrid paradigms combine AR's structured semantic modeling with diffusion's high-fidelity synthesis, yet suffer from a dual speed bottleneck: the sequential AR stage and the iterative multi-step denoising of the diffusion vision decode stage. Existing methods address each in isolation without a unified principle design. We observe that the per-position \emph{prediction entropy} of continuous-space AR models naturally encodes spatially varying generation uncertainty, which simultaneously governing draft prediction quality in the AR stage and reflecting the corrective effort required by vision decoding stage, which is not fully explored before. Since entropy is inherently tied to both bottlenecks, it serves as a natural unifying signal for joint acceleration. In this work, we propose \textbf{Drift-AR}, which leverages entropy signal to accelerate both stages: 1) for AR acceleration, we introduce Entropy-Informed Speculative Decoding that align draft--target entropy distributions via a causal-normalized entropy loss, resolving the entropy mismatch that causes excessive draft rejection; 2) for visual decoder acceleration, we reinterpret entropy as the \emph{physical variance} of the initial state for an anti-symmetric drifting field -- high-entropy positions activate stronger drift toward the data manifold while low-entropy positions yield vanishing drift -- enabling single-step (1-NFE) decoding without iterative denoising or distillation. Moreover, both stages share the same entropy signal, which is computed once with no extra cost. Experiments on MAR, TransDiff, and NextStep-1 demonstrate 3.8--5.5$\times$ speedup with genuine 1-NFE decoding, matching or surpassing original quality. Code will be available at https://github.com/aSleepyTree/Drift-AR.
FIRE: A Comprehensive Benchmark for Financial Intelligence and Reasoning Evaluation
Feb 25, 2026We introduce FIRE, a comprehensive benchmark designed to evaluate both the theoretical financial knowledge of LLMs and their ability to handle practical business scenarios. For theoretical assessment, we curate a diverse set of examination questions drawn from widely recognized financial qualification exams, enabling evaluation of LLMs deep understanding and application of financial knowledge. In addition, to assess the practical value of LLMs in real-world financial tasks, we propose a systematic evaluation matrix that categorizes complex financial domains and ensures coverage of essential subdomains and business activities. Based on this evaluation matrix, we collect 3,000 financial scenario questions, consisting of closed-form decision questions with reference answers and open-ended questions evaluated by predefined rubrics. We conduct comprehensive evaluations of state-of-the-art LLMs on the FIRE benchmark, including XuanYuan 4.0, our latest financial-domain model, as a strong in-domain baseline. These results enable a systematic analysis of the capability boundaries of current LLMs in financial applications. We publicly release the benchmark questions and evaluation code to facilitate future research.
MaskFocus: Focusing Policy Optimization on Critical Steps for Masked Image Generation
Dec 21, 2025Reinforcement learning (RL) has demonstrated significant potential for post-training language models and autoregressive visual generative models, but adapting RL to masked generative models remains challenging. The core factor is that policy optimization requires accounting for the probability likelihood of each step due to its multi-step and iterative refinement process. This reliance on entire sampling trajectories introduces high computational cost, whereas natively optimizing random steps often yields suboptimal results. In this paper, we present MaskFocus, a novel RL framework that achieves effective policy optimization for masked generative models by focusing on critical steps. Specifically, we determine the step-level information gain by measuring the similarity between the intermediate images at each sampling step and the final generated image. Crucially, we leverage this to identify the most critical and valuable steps and execute focused policy optimization on them. Furthermore, we design a dynamic routing sampling mechanism based on entropy to encourage the model to explore more valuable masking strategies for samples with low entropy. Extensive experiments on multiple Text-to-Image benchmarks validate the effectiveness of our method.
Fast-ARDiff: An Entropy-informed Acceleration Framework for Continuous Space Autoregressive Generation
Dec 09, 2025



Autoregressive(AR)-diffusion hybrid paradigms combine AR's structured modeling with diffusion's photorealistic synthesis, yet suffer from high latency due to sequential AR generation and iterative denoising. In this work, we tackle this bottleneck and propose a unified AR-diffusion framework Fast-ARDiff that jointly optimizes both components, accelerating AR speculative decoding while simultaneously facilitating faster diffusion decoding. Specifically: (1) The entropy-informed speculative strategy encourages draft model to produce higher-entropy representations aligned with target model's entropy characteristics, mitigating entropy mismatch and high rejection rates caused by draft overconfidence. (2) For diffusion decoding, rather than treating it as an independent module, we integrate it into the same end-to-end framework using a dynamic scheduler that prioritizes AR optimization to guide the diffusion part in further steps. The diffusion part is optimized through a joint distillation framework combining trajectory and distribution matching, ensuring stable training and high-quality synthesis with extremely few steps. During inference, shallow feature entropy from AR module is used to pre-filter low-entropy drafts, avoiding redundant computation and improving latency. Fast-ARDiff achieves state-of-the-art acceleration across diverse models: on ImageNet 256$\times$256, TransDiff attains 4.3$\times$ lossless speedup, and NextStep-1 achieves 3$\times$ acceleration on text-conditioned generation. Code will be available at https://github.com/aSleepyTree/Fast-ARDiff.
Group Critical-token Policy Optimization for Autoregressive Image Generation
Sep 26, 2025Recent studies have extended Reinforcement Learning with Verifiable Rewards (RLVR) to autoregressive (AR) visual generation and achieved promising progress. However, existing methods typically apply uniform optimization across all image tokens, while the varying contributions of different image tokens for RLVR's training remain unexplored. In fact, the key obstacle lies in how to identify more critical image tokens during AR generation and implement effective token-wise optimization for them. To tackle this challenge, we propose $\textbf{G}$roup $\textbf{C}$ritical-token $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{GCPO}$), which facilitates effective policy optimization on critical tokens. We identify the critical tokens in RLVR-based AR generation from three perspectives, specifically: $\textbf{(1)}$ Causal dependency: early tokens fundamentally determine the later tokens and final image effect due to unidirectional dependency; $\textbf{(2)}$ Entropy-induced spatial structure: tokens with high entropy gradients correspond to image structure and bridges distinct visual regions; $\textbf{(3)}$ RLVR-focused token diversity: tokens with low visual similarity across a group of sampled images contribute to richer token-level diversity. For these identified critical tokens, we further introduce a dynamic token-wise advantage weight to encourage exploration, based on confidence divergence between the policy model and reference model. By leveraging 30\% of the image tokens, GCPO achieves better performance than GRPO with full tokens. Extensive experiments on multiple text-to-image benchmarks for both AR models and unified multimodal models demonstrate the effectiveness of GCPO for AR visual generation.
LLM-based Multi-Agent Copilot for Quantum Sensor
Aug 07, 2025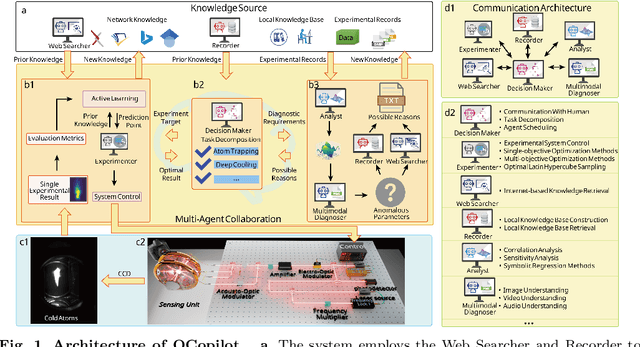
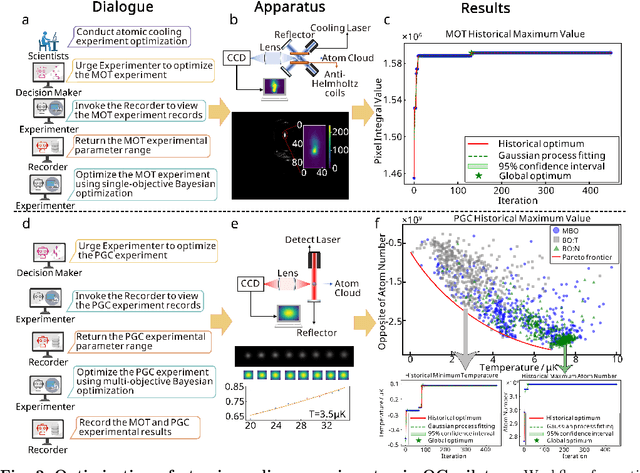
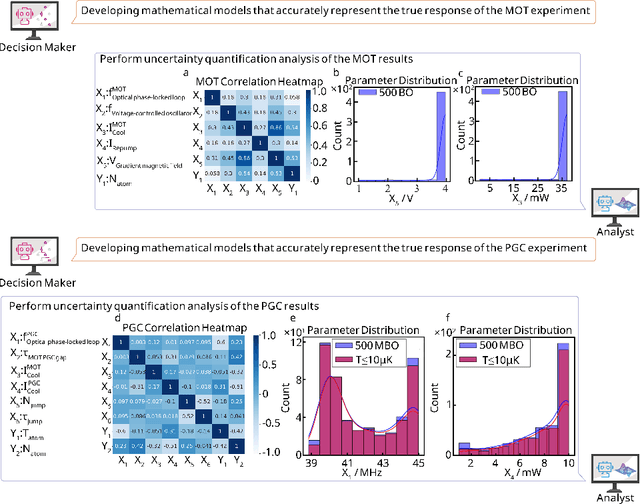
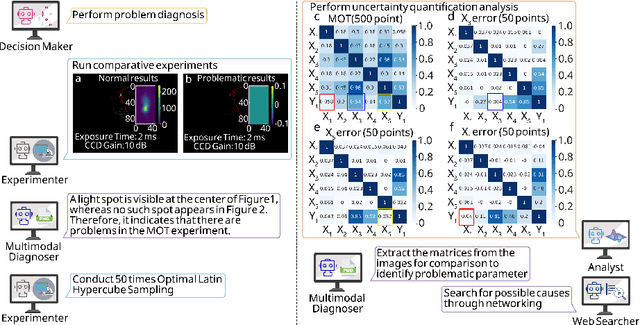
Large language models (LLM) exhibit broad utility but face limitations in quantum sensor development, stemming from interdisciplinary knowledge barriers and involving complex optimization processes. Here we present QCopilot, an LLM-based multi-agent framework integrating external knowledge access, active learning, and uncertainty quantification for quantum sensor design and diagnosis. Comprising commercial LLMs with few-shot prompt engineering and vector knowledge base, QCopilot employs specialized agents to adaptively select optimization methods, automate modeling analysis, and independently perform problem diagnosis. Applying QCopilot to atom cooling experiments, we generated 10${}^{\rm{8}}$ sub-$\rm{\mu}$K atoms without any human intervention within a few hours, representing $\sim$100$\times$ speedup over manual experimentation. Notably, by continuously accumulating prior knowledge and enabling dynamic modeling, QCopilot can autonomously identify anomalous parameters in multi-parameter experimental settings. Our work reduces barriers to large-scale quantum sensor deployment and readily extends to other quantum information systems.