 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Trained Models: Past, Present and Future
Jun 15, 2021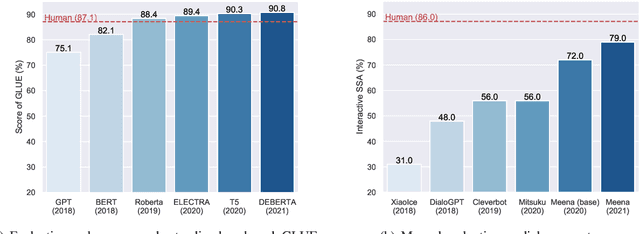
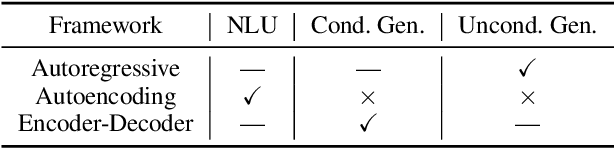
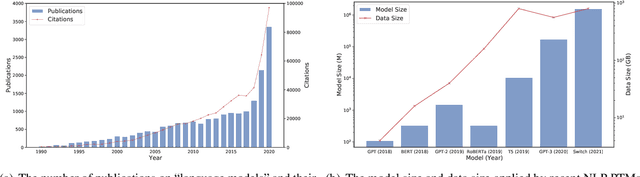
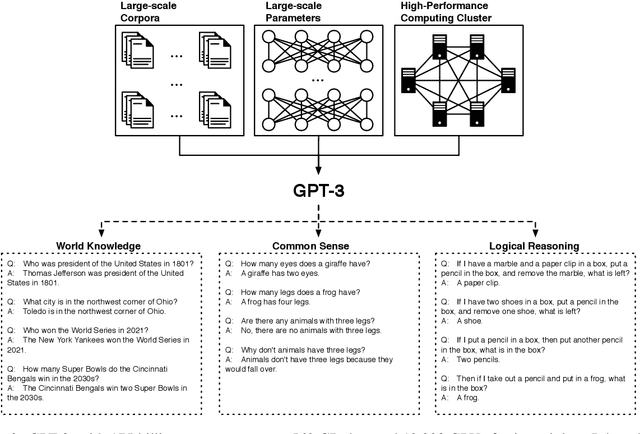
Large-scale pre-trained models (PTMs) such as BERT and GPT have recently achieved great success and become a milestone in the field of artificial intelligence (AI). Owing to sophisticated pre-training objectives and huge model parameters, large-scale PTMs can effectively capture knowledge from massive labeled and unlabeled data. By storing knowledge into huge parameters and fine-tuning on specific tasks, the rich knowledge implicitly encoded in huge parameters can benefit a variety of downstream tasks, which has been extensively demonstrated via experimental verification and empirical analysis. It is now the consensus of the AI community to adopt PTMs as backbone for downstream tasks rather than learning models from scratch. In this paper, we take a deep look into the history of pre-training, especially its special relation with transfer learning and self-supervised learning, to reveal the crucial position of PTMs in the AI development spectrum. Further, we comprehensively review the latest breakthroughs of PTMs. These breakthroughs are driven by the surge of computational power and the increasing availability of data, towards four important directions: designing effective architectures, utilizing rich contexts, improving computational efficiency, and conducting interpretation and theoretical analysis. Finally, we discuss a series of open problems and research directions of PTMs, and hope our view can inspire and advance the future study of PTMs.
Understanding Softmax Confidence and Uncertainty
Jun 09, 2021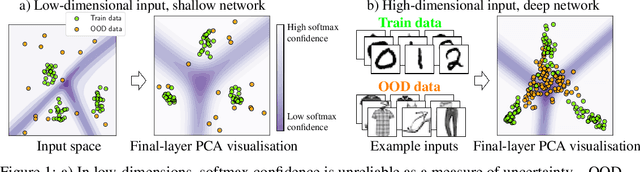
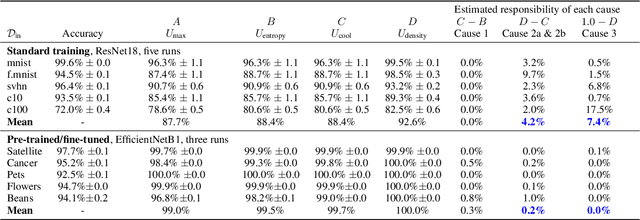
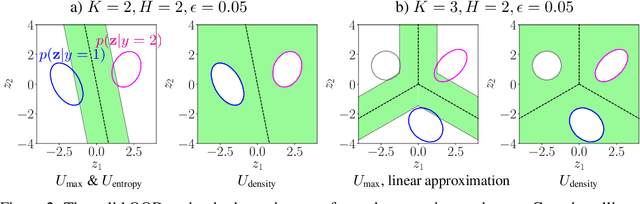
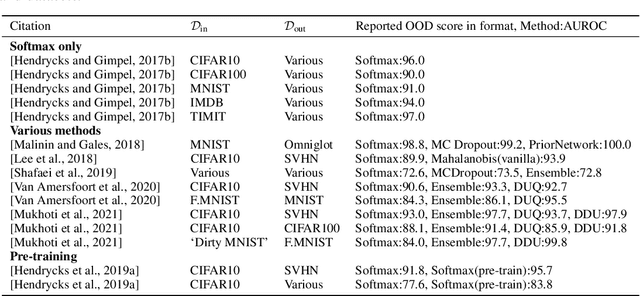
It is often remarked that neural networks fail to increase their uncertainty when predicting on data far from the training distribution. Yet naively using softmax confidence as a proxy for uncertainty achieves modest success in tasks exclusively testing for this, e.g., out-of-distribution (OOD) detection. This paper investigates this contradiction, identifying two implicit biases that do encourage softmax confidence to correlate with epistemic uncertainty: 1) Approximately optimal decision boundary structure, and 2) Filtering effects of deep networks. It describes why low-dimensional intuitions about softmax confidence are misleading. Diagnostic experiments quantify reasons softmax confidence can fail, finding that extrapolations are less to blame than overlap between training and OOD data in final-layer representations. Pre-trained/fine-tuned networks reduce this overlap.
Nonlinear Hawkes Processes in Time-Varying System
Jun 09, 2021
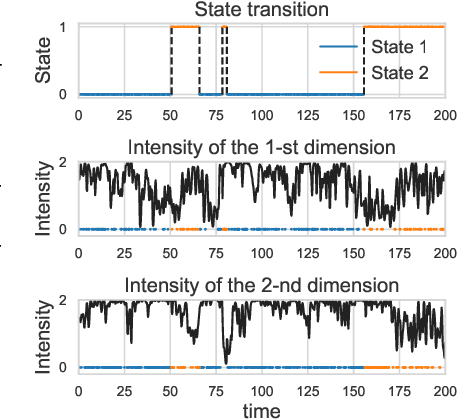
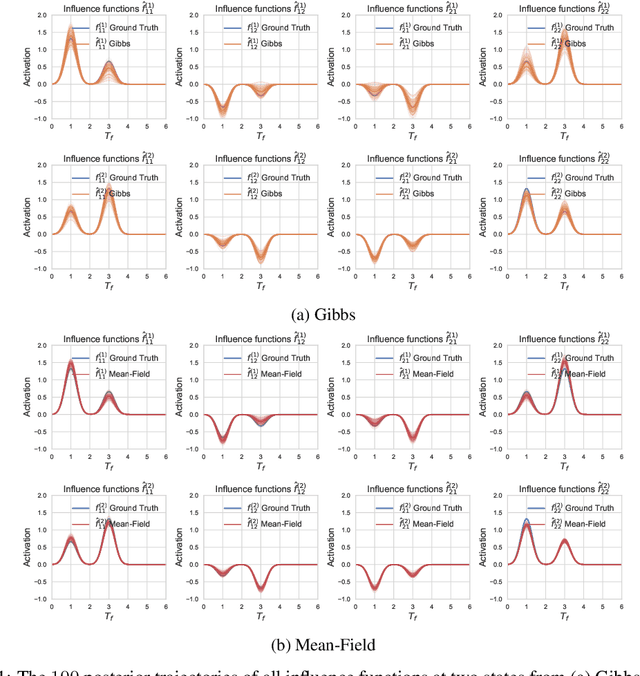
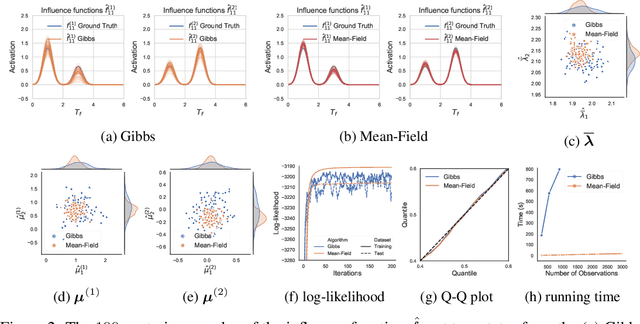
Hawkes processes are a class of point processes that have the ability to model the self- and mutual-exciting phenomena. Although the classic Hawkes processes cover a wide range of applications, their expressive ability is limited due to three key hypotheses: parametric, linear and homogeneous. Recent work has attempted to address these limitations separately. This work aims to overcome all three assumptions simultaneously by proposing the flexible state-switching Hawkes processes: a flexible, nonlinear and nonhomogeneous variant where a state process is incorporated to interact with the point processes. The proposed model empowers Hawkes processes to be applied to time-varying systems. For inference, we utilize the latent variable augmentation technique to design two efficient Bayesian inference algorithms: Gibbs sampler and mean-field variational inference, with analytical iterative updates to estimate the posterior. In experiments, our model achieves superior performance compared to the state-of-the-art competitors.
Stability and Generalization of Bilevel Programming in Hyperparameter Optimization
Jun 08, 2021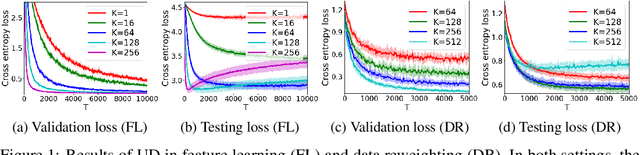
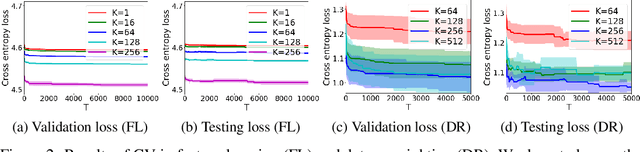
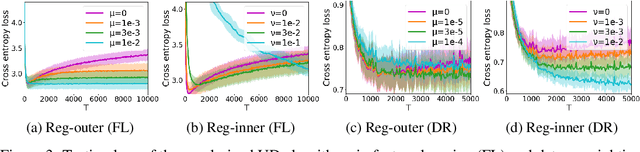
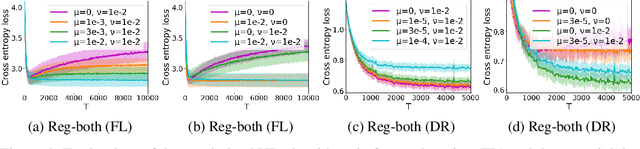
Recently, the (gradient-based) bilevel programming framework is widely used in hyperparameter optimization and has achieved excellent performance empirically. Previous theoretical work mainly focuses on its optimization properties, while leaving the analysis on generalization largely open. This paper attempts to address the issue by presenting an expectation bound w.r.t. the validation set based on uniform stability. Our results can explain some mysterious behaviours of the bilevel programming in practice, for instance, overfitting to the validation set. We also present an expectation bound for the classical cross-validation algorithm. Our results suggest that gradient-based algorithms can be better than cross-validation under certain conditions in a theoretical perspective. Furthermore, we prove that regularization terms in both the outer and inner levels can relieve the overfitting problem in gradient-based algorithms. In experiments on feature learning and data reweighting for noisy labels, we corroborate our theoretical findings.
Exploring Memorization in Adversarial Training
Jun 03, 2021
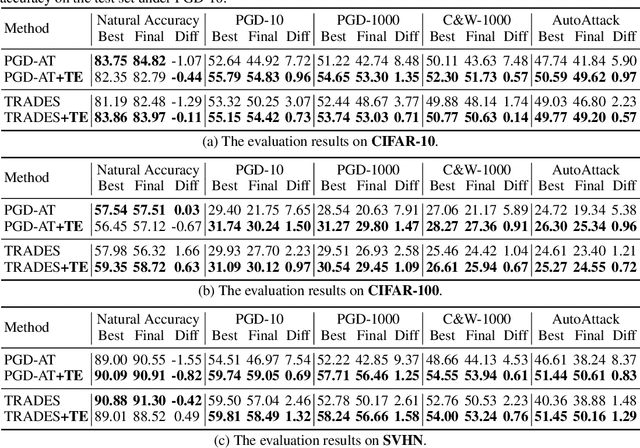
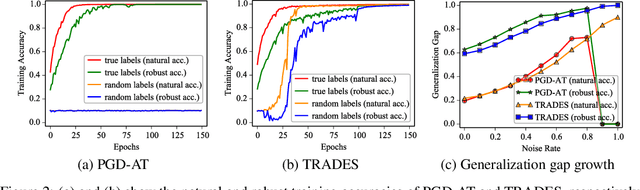
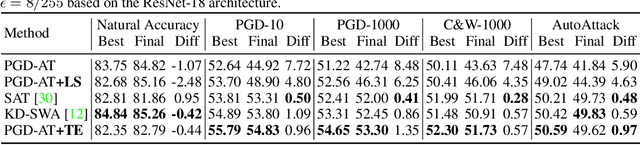
It is well known that deep learning models have a propensity for fitting the entire training set even with random labels, which requires memorization of every training sample. In this paper, we investigate the memorization effect in adversarial training (AT) for promoting a deeper understanding of capacity, convergence, generalization, and especially robust overfitting of adversarially trained classifiers. We first demonstrate that deep networks have sufficient capacity to memorize adversarial examples of training data with completely random labels, but not all AT algorithms can converge under the extreme circumstance. Our study of AT with random labels motivates further analyses on the convergence and generalization of AT. We find that some AT methods suffer from a gradient instability issue, and the recently suggested complexity measures cannot explain robust generalization by considering models trained on random labels. Furthermore, we identify a significant drawback of memorization in AT that it could result in robust overfitting. We then propose a new mitigation algorithm motivated by detailed memorization analyses. Extensive experiments on various datasets validate the effectiveness of the proposed method.
KO-PDE: Kernel Optimized Discovery of Partial Differential Equations with Varying Coefficients
Jun 02, 2021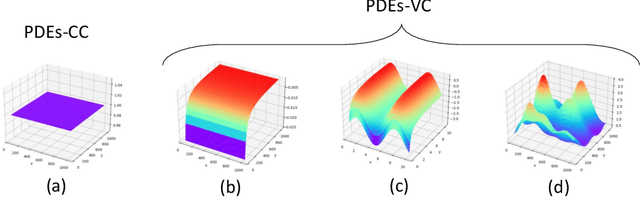
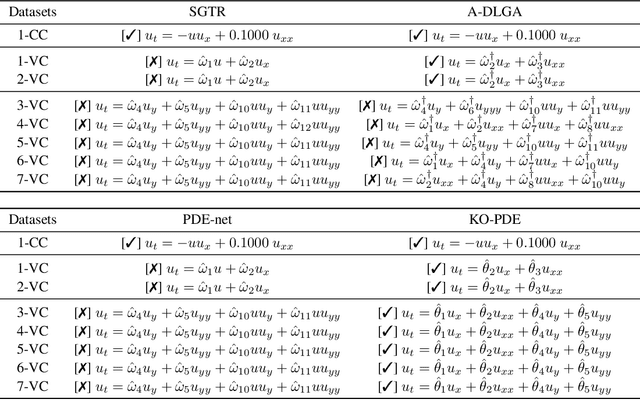
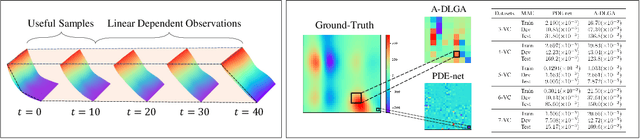
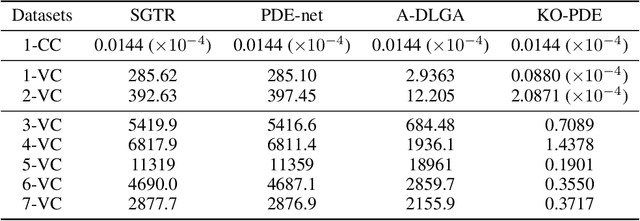
Partial differential equations (PDEs) fitting scientific data can represent physical laws with explainable mechanisms for various mathematically-oriented subjects. Most natural dynamics are expressed by PDEs with varying coefficients (PDEs-VC), which highlights the importance of PDE discovery. Previous algorithms can discover some simple instances of PDEs-VC but fail in the discovery of PDEs with coefficients of higher complexity, as a result of coefficient estimation inaccuracy. In this paper, we propose KO-PDE, a kernel optimized regression method that incorporates the kernel density estimation of adjacent coefficients to reduce the coefficient estimation error. KO-PDE can discover PDEs-VC on which previous baselines fail and is more robust against inevitable noise in data. In experiments, the PDEs-VC of seven challenging spatiotemporal scientific datasets in fluid dynamics are all discovered by KO-PDE, while the three baselines render false results in most cases. With state-of-the-art performance, KO-PDE sheds light on the automatic description of natural phenomenons using discovered PDEs in the real world.
Adversarial Training with Rectified Rejection
May 31, 2021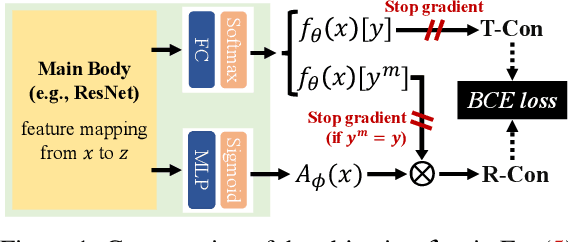
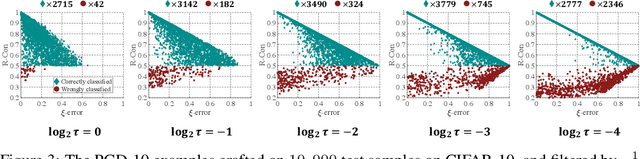
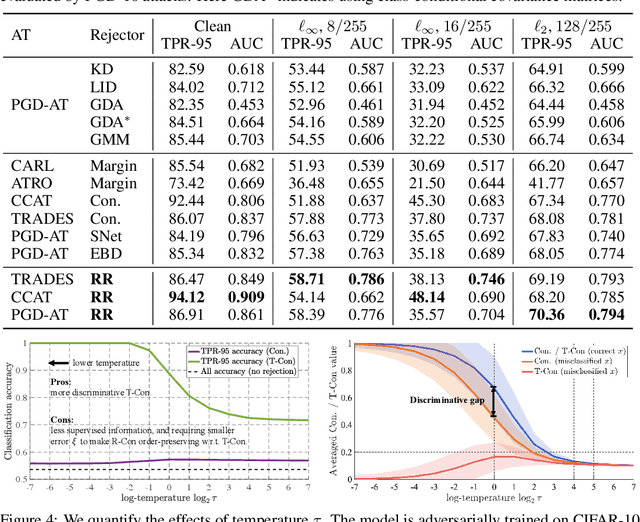
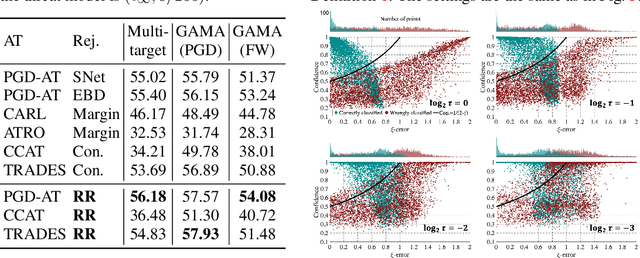
Adversarial training (AT) is one of the most effective strategies for promoting model robustness, whereas even the state-of-the-art adversarially trained models struggle to exceed 60% robust test accuracy on CIFAR-10 without additional data, which is far from practical. A natural way to break this accuracy bottleneck is to introduce a rejection option, where confidence is a commonly used certainty proxy. However, the vanilla confidence can overestimate the model certainty if the input is wrongly classified. To this end, we propose to use true confidence (T-Con) (i.e., predicted probability of the true class) as a certainty oracle, and learn to predict T-Con by rectifying confidence. We prove that under mild conditions, a rectified confidence (R-Con) rejector and a confidence rejector can be coupled to distinguish any wrongly classified input from correctly classified ones, even under adaptive attacks. We also quantify that training R-Con to be aligned with T-Con could be an easier task than learning robust classifiers. In our experiments, we evaluate our rectified rejection (RR) module on CIFAR-10, CIFAR-10-C, and CIFAR-100 under several attacks, and demonstrate that the RR module is well compatible with different AT frameworks on improving robustness, with little extra computation.
Unsupervised Part Segmentation through Disentangling Appearance and Shape
May 26, 2021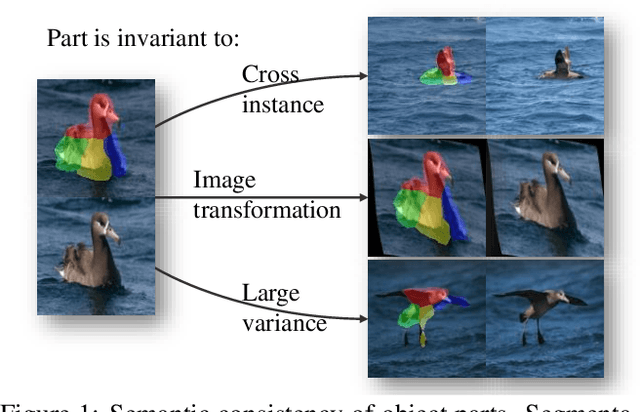
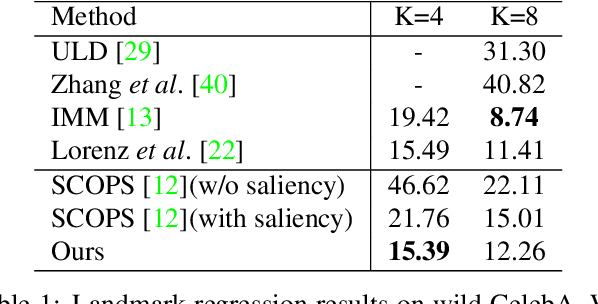
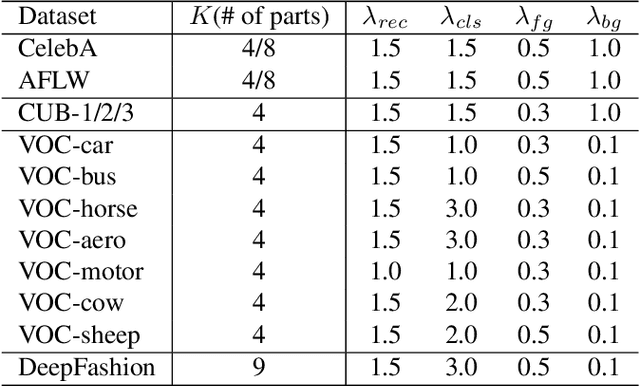
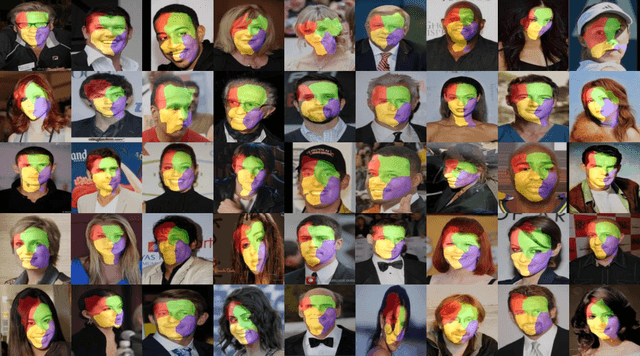
We study the problem of unsupervised discovery and segmentation of object parts, which, as an intermediate local representation, are capable of finding intrinsic object structure and providing more explainable recognition results. Recent unsupervised methods have greatly relaxed the dependency on annotated data which are costly to obtain, but still rely on additional information such as object segmentation mask or saliency map. To remove such a dependency and further improve the part segmentation performance, we develop a novel approach by disentangling the appearance and shape representations of object parts followed with reconstruction losses without using additional object mask information. To avoid degenerated solutions, a bottleneck block is designed to squeeze and expand the appearance representation, leading to a more effective disentanglement between geometry and appearance. Combined with a self-supervised part classification loss and an improved geometry concentration constraint, we can segment more consistent parts with semantic meanings. Comprehensive experiments on a wide variety of objects such as face, bird, and PASCAL VOC objects demonstrate the effectiveness of the proposed method.
Rethinking and Reweighting the Univariate Losses for Multi-Label Ranking: Consistency and Generalization
May 10, 2021
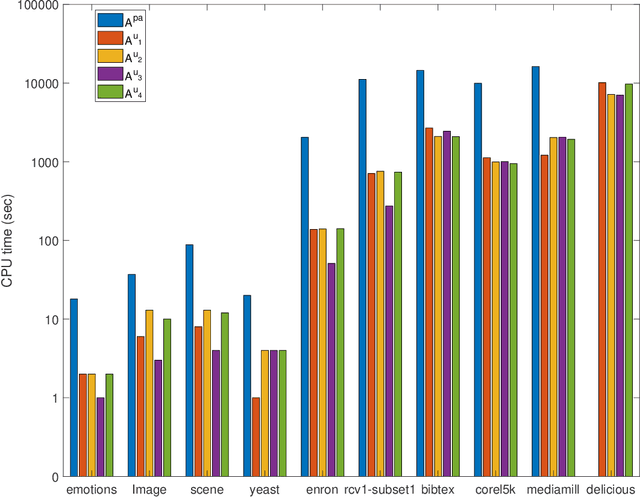
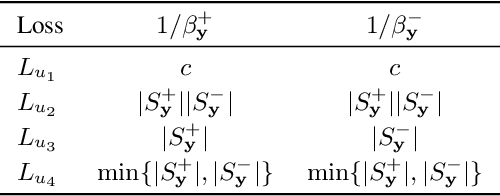
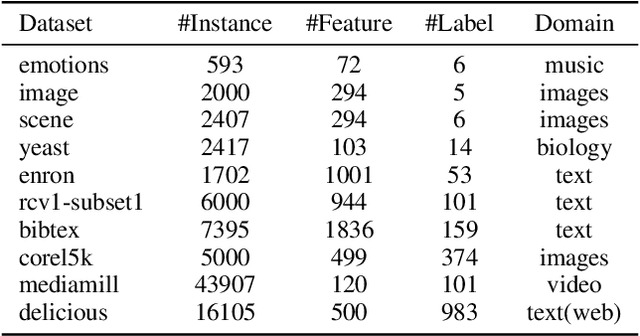
(Partial) ranking loss is a commonly used evaluation measure for multi-label classification, which is usually optimized with convex surrogates for computational efficiency. Prior theoretical work on multi-label ranking mainly focuses on (Fisher) consistency analyses. However, there is a gap between existing theory and practice -- some pairwise losses can lead to promising performance but lack consistency, while some univariate losses are consistent but usually have no clear superiority in practice. In this paper, we attempt to fill this gap through a systematic study from two complementary perspectives of consistency and generalization error bounds of learning algorithms. Our results show that learning algorithms with the consistent univariate loss have an error bound of $O(c)$ ($c$ is the number of labels), while algorithms with the inconsistent pairwise loss depend on $O(\sqrt{c})$ as shown in prior work. This explains that the latter can achieve better performance than the former in practice. Moreover, we present an inconsistent reweighted univariate loss-based learning algorithm that enjoys an error bound of $O(\sqrt{c})$ for promising performance as well as the computational efficiency of univariate losses. Finally, experimental results validate our theoretical analyses.
Automated Decision-based Adversarial Attacks
May 09, 2021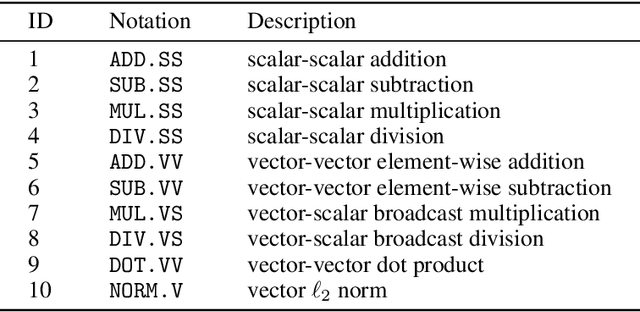

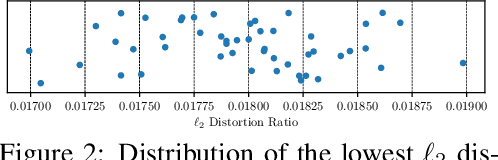
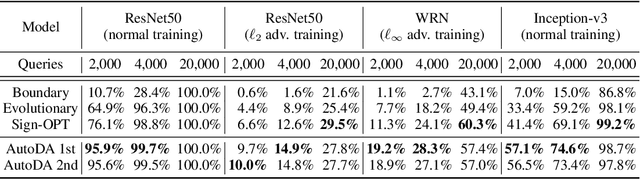
Deep learning models are vulnerable to adversarial examples, which can fool a target classifier by imposing imperceptible perturbations onto natural examples. In this work, we consider the practical and challenging decision-based black-box adversarial setting, where the attacker can only acquire the final classification labels by querying the target model without access to the model's details. Under this setting, existing works often rely on heuristics and exhibit unsatisfactory performance. To better understand the rationality of these heuristics and the limitations of existing methods, we propose to automatically discover decision-based adversarial attack algorithms. In our approach, we construct a search space using basic mathematical operations as building blocks and develop a random search algorithm to efficiently explore this space by incorporating several pruning techniques and intuitive priors inspired by program synthesis works. Although we use a small and fast model to efficiently evaluate attack algorithms during the search, extensive experiments demonstrate that the discovered algorithms are simple yet query-efficient when transferred to larger normal and defensive models on the CIFAR-10 and ImageNet datasets. They achieve comparable or better performance than the state-of-the-art decision-based attack methods consistently.