 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoFlow: Reinforcing Search Agent Via Reward Density Optimization
Oct 30, 2025Reinforcement Learning with Verifiable Rewards (RLVR) is a promising approach for enhancing agentic deep search. However, its application is often hindered by low \textbf{Reward Density} in deep search scenarios, where agents expend significant exploratory costs for infrequent and often null final rewards. In this paper, we formalize this challenge as the \textbf{Reward Density Optimization} problem, which aims to improve the reward obtained per unit of exploration cost. This paper introduce \textbf{InfoFlow}, a systematic framework that tackles this problem from three aspects. 1) \textbf{Subproblem decomposition}: breaking down long-range tasks to assign process rewards, thereby providing denser learning signals. 2) \textbf{Failure-guided hints}: injecting corrective guidance into stalled trajectories to increase the probability of successful outcomes. 3) \textbf{Dual-agent refinement}: employing a dual-agent architecture to offload the cognitive burden of deep exploration. A refiner agent synthesizes the search history, which effectively compresses the researcher's perceived trajectory, thereby reducing exploration cost and increasing the overall reward density. We evaluate InfoFlow on multiple agentic search benchmarks, where it significantly outperforms strong baselines, enabling lightweight LLMs to achieve performance comparable to advanced proprietary LLMs.
The Zero-Step Thinking: An Empirical Study of Mode Selection as Harder Early Exit in Reasoning Models
Oct 22, 2025Reasoning models have demonstrated exceptional performance in tasks such as mathematics and logical reasoning, primarily due to their ability to engage in step-by-step thinking during the reasoning process. However, this often leads to overthinking, resulting in unnecessary computational overhead. To address this issue, Mode Selection aims to automatically decide between Long-CoT (Chain-of-Thought) or Short-CoT by utilizing either a Thinking or NoThinking mode. Simultaneously, Early Exit determines the optimal stopping point during the iterative reasoning process. Both methods seek to reduce the computational burden. In this paper, we first identify Mode Selection as a more challenging variant of the Early Exit problem, as they share similar objectives but differ in decision timing. While Early Exit focuses on determining the best stopping point for concise reasoning at inference time, Mode Selection must make this decision at the beginning of the reasoning process, relying on pre-defined fake thoughts without engaging in an explicit reasoning process, referred to as zero-step thinking. Through empirical studies on nine baselines, we observe that prompt-based approaches often fail due to their limited classification capabilities when provided with minimal hand-crafted information. In contrast, approaches that leverage internal information generally perform better across most scenarios but still exhibit issues with stability. Our findings indicate that existing methods relying solely on the information provided by models are insufficient for effectively addressing Mode Selection in scenarios with limited information, highlighting the ongoing challenges of this task. Our code is available at https://github.com/Trae1ounG/Zero_Step_Thinking.
Towards Agentic Self-Learning LLMs in Search Environment
Oct 16, 2025



We study whether self-learning can scale LLM-based agents without relying on human-curated datasets or predefined rule-based rewards. Through controlled experiments in a search-agent setting, we identify two key determinants of scalable agent training: the source of reward signals and the scale of agent task data. We find that rewards from a Generative Reward Model (GRM) outperform rigid rule-based signals for open-domain learning, and that co-evolving the GRM with the policy further boosts performance. Increasing the volume of agent task data-even when synthetically generated-substantially enhances agentic capabilities. Building on these insights, we propose \textbf{Agentic Self-Learning} (ASL), a fully closed-loop, multi-role reinforcement learning framework that unifies task generation, policy execution, and evaluation within a shared tool environment and LLM backbone. ASL coordinates a Prompt Generator, a Policy Model, and a Generative Reward Model to form a virtuous cycle of harder task setting, sharper verification, and stronger solving. Empirically, ASL delivers steady, round-over-round gains, surpasses strong RLVR baselines (e.g., Search-R1) that plateau or degrade, and continues improving under zero-labeled-data conditions, indicating superior sample efficiency and robustness. We further show that GRM verification capacity is the main bottleneck: if frozen, it induces reward hacking and stalls progress; continual GRM training on the evolving data distribution mitigates this, and a small late-stage injection of real verification data raises the performance ceiling. This work establishes reward source and data scale as critical levers for open-domain agent learning and demonstrates the efficacy of multi-role co-evolution for scalable, self-improving agents. The data and code of this paper are released at https://github.com/forangel2014/Towards-Agentic-Self-Learning
MotivGraph-SoIQ: Integrating Motivational Knowledge Graphs and Socratic Dialogue for Enhanced LLM Ideation
Sep 26, 2025
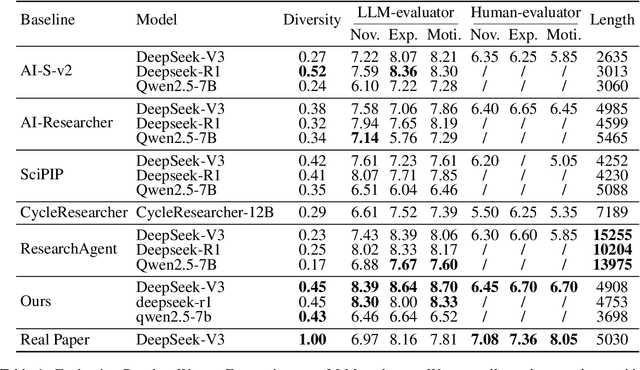
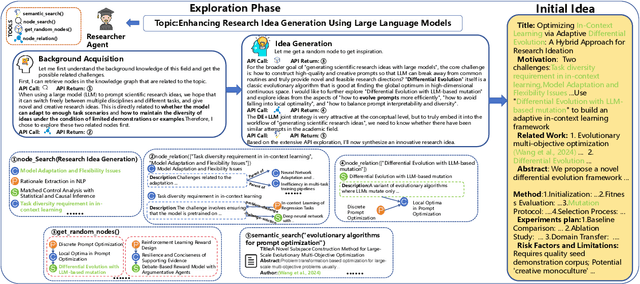
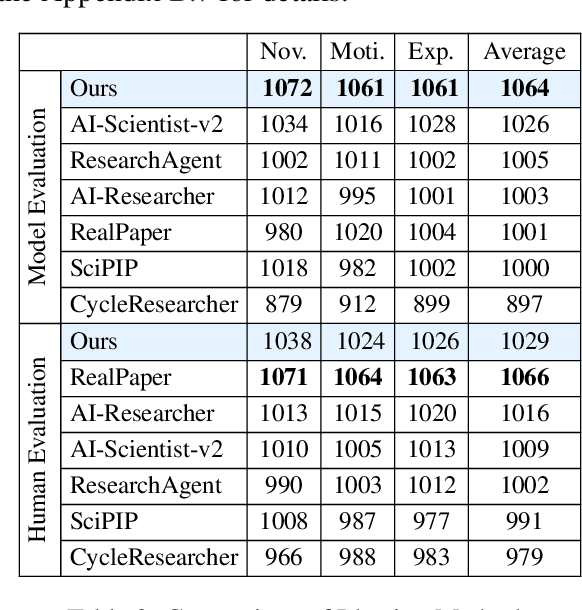
Large Language Models (LLMs) hold substantial potential for accelerating academic ideation but face critical challenges in grounding ideas and mitigating confirmation bias for further refinement. We propose integrating motivational knowledge graphs and socratic dialogue to address these limitations in enhanced LLM ideation (MotivGraph-SoIQ). This novel framework provides essential grounding and practical idea improvement steps for LLM ideation by integrating a Motivational Knowledge Graph (MotivGraph) with a Q-Driven Socratic Ideator. The MotivGraph structurally stores three key node types(problem, challenge and solution) to offer motivation grounding for the LLM ideation process. The Ideator is a dual-agent system utilizing Socratic questioning, which facilitates a rigorous refinement process that mitigates confirmation bias and improves idea quality across novelty, experimental rigor, and motivational rationality dimensions. On the ICLR25 paper topics dataset, MotivGraph-SoIQ exhibits clear advantages over existing state-of-the-art approaches across LLM-based scoring, ELO ranking, and human evaluation metrics.
FoundDiff: Foundational Diffusion Model for Generalizable Low-Dose CT Denoising
Aug 24, 2025Low-dose computed tomography (CT) denoising is crucial for reduced radiation exposure while ensuring diagnostically acceptable image quality. Despite significant advancements driven by deep learning (DL) in recent years, existing DL-based methods, typically trained on a specific dose level and anatomical region, struggle to handle diverse noise characteristics and anatomical heterogeneity during varied scanning conditions, limiting their generalizability and robustness in clinical scenarios. In this paper, we propose FoundDiff, a foundational diffusion model for unified and generalizable LDCT denoising across various dose levels and anatomical regions. FoundDiff employs a two-stage strategy: (i) dose-anatomy perception and (ii) adaptive denoising. First, we develop a dose- and anatomy-aware contrastive language image pre-training model (DA-CLIP) to achieve robust dose and anatomy perception by leveraging specialized contrastive learning strategies to learn continuous representations that quantify ordinal dose variations and identify salient anatomical regions. Second, we design a dose- and anatomy-aware diffusion model (DA-Diff) to perform adaptive and generalizable denoising by synergistically integrating the learned dose and anatomy embeddings from DACLIP into diffusion process via a novel dose and anatomy conditional block (DACB) based on Mamba. Extensive experiments on two public LDCT datasets encompassing eight dose levels and three anatomical regions demonstrate superior denoising performance of FoundDiff over existing state-of-the-art methods and the remarkable generalization to unseen dose levels. The codes and models are available at https://github.com/hao1635/FoundDiff.
SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning
Aug 21, 2025Long-context inference in large language models (LLMs) is increasingly constrained by the KV cache bottleneck: memory usage grows linearly with sequence length, while attention computation scales quadratically. Existing approaches address this issue by compressing the KV cache along the temporal axis through strategies such as token eviction or merging to reduce memory and computational overhead. However, these methods often neglect fine-grained importance variations across feature dimensions (i.e., the channel axis), thereby limiting their ability to effectively balance efficiency and model accuracy. In reality, we observe that channel saliency varies dramatically across both queries and positions: certain feature channels carry near-zero information for a given query, while others spike in relevance. To address this oversight, we propose SPARK, a training-free plug-and-play method that applies unstructured sparsity by pruning KV at the channel level, while dynamically restoring the pruned entries during attention score computation. Notably, our approach is orthogonal to existing KV compression and quantization techniques, making it compatible for integration with them to achieve further acceleration. By reducing channel-level redundancy, SPARK enables processing of longer sequences within the same memory budget. For sequences of equal length, SPARK not only preserves or improves model accuracy but also reduces KV cache storage by over 30% compared to eviction-based methods. Furthermore, even with an aggressive pruning ratio of 80%, SPARK maintains performance with less degradation than 5% compared to the baseline eviction method, demonstrating its robustness and effectiveness. Our code will be available at https://github.com/Xnhyacinth/SparK.
JoyTTS: LLM-based Spoken Chatbot With Voice Cloning
Jul 03, 2025JoyTTS is an end-to-end spoken chatbot that combines large language models (LLM) with text-to-speech (TTS) technology, featuring voice cloning capabilities. This project is built upon the open-source MiniCPM-o and CosyVoice2 models and trained on 2000 hours of conversational data. We have also provided the complete training code to facilitate further development and optimization by the community. On the testing machine seed-tts-zh, it achieves a SS (speaker similarity) score of 0.73 and a WER (Word Error Rate) of 5.09. The code and models, along with training and inference scripts, are available at https://github.com/jdh-algo/JoyTTS.git.
Know-MRI: A Knowledge Mechanisms Revealer&Interpreter for Large Language Models
Jun 10, 2025As large language models (LLMs) continue to advance, there is a growing urgency to enhance the interpretability of their internal knowledge mechanisms. Consequently, many interpretation methods have emerged, aiming to unravel the knowledge mechanisms of LLMs from various perspectives. However, current interpretation methods differ in input data formats and interpreting outputs. The tools integrating these methods are only capable of supporting tasks with specific inputs, significantly constraining their practical applications. To address these challenges, we present an open-source Knowledge Mechanisms Revealer&Interpreter (Know-MRI) designed to analyze the knowledge mechanisms within LLMs systematically. Specifically, we have developed an extensible core module that can automatically match different input data with interpretation methods and consolidate the interpreting outputs. It enables users to freely choose appropriate interpretation methods based on the inputs, making it easier to comprehensively diagnose the model's internal knowledge mechanisms from multiple perspectives. Our code is available at https://github.com/nlpkeg/Know-MRI. We also provide a demonstration video on https://youtu.be/NVWZABJ43Bs.
RULE: Reinforcement UnLEarning Achieves Forget-Retain Pareto Optimality
Jun 08, 2025The widespread deployment of Large Language Models (LLMs) trained on massive, uncurated corpora has raised growing concerns about the inclusion of sensitive, copyrighted, or illegal content. This has led to increasing interest in LLM unlearning: the task of selectively removing specific information from a model without retraining from scratch or degrading overall utility. However, existing methods often rely on large-scale forget and retain datasets, and suffer from unnatural responses, poor generalization, or catastrophic utility loss. In this work, we propose Reinforcement UnLearning (RULE), an efficient framework that formulates unlearning as a refusal boundary optimization problem. RULE is trained with a small portion of the forget set and synthesized boundary queries, using a verifiable reward function that encourages safe refusal on forget--related queries while preserving helpful responses on permissible inputs. We provide both theoretical and empirical evidence demonstrating the effectiveness of RULE in achieving targeted unlearning without compromising model utility. Experimental results show that, with only $12%$ forget set and $8%$ synthesized boundary data, RULE outperforms existing baselines by up to $17.5%$ forget quality and $16.3%$ naturalness response while maintaining general utility, achieving forget--retain Pareto optimality. Remarkably, we further observe that RULE improves the naturalness of model outputs, enhances training efficiency, and exhibits strong generalization ability, generalizing refusal behavior to semantically related but unseen queries.
MMR-V: What's Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Jun 04, 2025The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as "question frame") and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.