 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePair-In, Pair-Out: Latent Multi-Token Prediction for Efficient LLMs
May 26, 2026Long chain-of-thought reasoning has made autoregressive decoding the dominant inference cost of modern large language models. Existing methods target either the input side (latent compression) or the output side (speculative decoding and multi-token prediction, MTP), but the two lines of work have been pursued independently. Moreover, output-side methods must incur an expensive verifier pass to validate the unreliable draft tokens predicted by MTP. To address these issues, we propose \textbf{Pair-In, Pair-Out (PIPO)}, which unifies both sides by viewing a latent compressor and an MTP head as mirror-image operations: the compressor folds two input tokens into one latent representation, while the MTP head unfolds one hidden state into one additional output token. To remove the verifier cost without sacrificing reliability, PIPO trains a lightweight confidence head that decides whether draft tokens should be accepted. We observe that On-Policy Distillation (OPD) naturally matches the rejection-sampling criterion of speculative decoding, so the confidence head can be trained alongside OPD with negligible extra cost. Experiments on AIME 2025, GPQA-Diamond, LiveCodeBench v6, and LongBench v2 with Qwen3.5-4B and 9B backbones show that PIPO improves pass@4 over regular decoding by up to $+7.15$ points, while delivering up to $2.64\times$ first-token-latency and $2.07\times$ per-token-latency speedups.
Know-MRI: A Knowledge Mechanisms Revealer&Interpreter for Large Language Models
Jun 10, 2025As large language models (LLMs) continue to advance, there is a growing urgency to enhance the interpretability of their internal knowledge mechanisms. Consequently, many interpretation methods have emerged, aiming to unravel the knowledge mechanisms of LLMs from various perspectives. However, current interpretation methods differ in input data formats and interpreting outputs. The tools integrating these methods are only capable of supporting tasks with specific inputs, significantly constraining their practical applications. To address these challenges, we present an open-source Knowledge Mechanisms Revealer&Interpreter (Know-MRI) designed to analyze the knowledge mechanisms within LLMs systematically. Specifically, we have developed an extensible core module that can automatically match different input data with interpretation methods and consolidate the interpreting outputs. It enables users to freely choose appropriate interpretation methods based on the inputs, making it easier to comprehensively diagnose the model's internal knowledge mechanisms from multiple perspectives. Our code is available at https://github.com/nlpkeg/Know-MRI. We also provide a demonstration video on https://youtu.be/NVWZABJ43Bs.
If an LLM Were a Character, Would It Know Its Own Story? Evaluating Lifelong Learning in LLMs
Mar 30, 2025Large language models (LLMs) can carry out human-like dialogue, but unlike humans, they are stateless due to the superposition property. However, during multi-turn, multi-agent interactions, LLMs begin to exhibit consistent, character-like behaviors, hinting at a form of emergent lifelong learning. Despite this, existing benchmarks often fail to capture these dynamics, primarily focusing on static, open-ended evaluations. To address this gap, we introduce LIFESTATE-BENCH, a benchmark designed to assess lifelong learning in LLMs. It features two episodic datasets: Hamlet and a synthetic script collection, rich in narrative structure and character interactions. Our fact checking evaluation probes models' self-awareness, episodic memory retrieval, and relationship tracking, across both parametric and non-parametric approaches. Experiments on models like Llama3.1-8B, GPT-4-turbo, and DeepSeek R1, we demonstrate that nonparametric methods significantly outperform parametric ones in managing stateful learning. However, all models exhibit challenges with catastrophic forgetting as interactions extend, highlighting the need for further advancements in lifelong learning.
Capability Localization: Capabilities Can be Localized rather than Individual Knowledge
Feb 28, 2025



Large scale language models have achieved superior performance in tasks related to natural language processing, however, it is still unclear how model parameters affect performance improvement. Previous studies assumed that individual knowledge is stored in local parameters, and the storage form of individual knowledge is dispersed parameters, parameter layers, or parameter chains, which are not unified. We found through fidelity and reliability evaluation experiments that individual knowledge cannot be localized. Afterwards, we constructed a dataset for decoupling experiments and discovered the potential for localizing data commonalities. To further reveal this phenomenon, this paper proposes a Commonality Neuron Localization (CNL) method, which successfully locates commonality neurons and achieves a neuron overlap rate of 96.42% on the GSM8K dataset. Finally, we have demonstrated through cross data experiments that commonality neurons are a collection of capability neurons that possess the capability to enhance performance. Our code is available at https://github.com/nlpkeg/Capability-Neuron-Localization.
Reasons and Solutions for the Decline in Model Performance after Editing
Oct 31, 2024



Knowledge editing technology has received widespread attention for low-cost updates of incorrect or outdated knowledge in large-scale language models. However, recent research has found that edited models often exhibit varying degrees of performance degradation. The reasons behind this phenomenon and potential solutions have not yet been provided. In order to investigate the reasons for the performance decline of the edited model and optimize the editing method, this work explores the underlying reasons from both data and model perspectives. Specifically, 1) from a data perspective, to clarify the impact of data on the performance of editing models, this paper first constructs a Multi-Question Dataset (MQD) to evaluate the impact of different types of editing data on model performance. The performance of the editing model is mainly affected by the diversity of editing targets and sequence length, as determined through experiments. 2) From a model perspective, this article explores the factors that affect the performance of editing models. The results indicate a strong correlation between the L1-norm of the editing model layer and the editing accuracy, and clarify that this is an important factor leading to the bottleneck of editing performance. Finally, in order to improve the performance of the editing model, this paper further proposes a Dump for Sequence (D4S) method, which successfully overcomes the previous editing bottleneck by reducing the L1-norm of the editing layer, allowing users to perform multiple effective edits and minimizing model damage. Our code is available at https://github.com/nlpkeg/D4S.
* 14 pages, 8 figures
Commonsense Knowledge Editing Based on Free-Text in LLMs
Oct 31, 2024



Knowledge editing technology is crucial for maintaining the accuracy and timeliness of large language models (LLMs) . However, the setting of this task overlooks a significant portion of commonsense knowledge based on free-text in the real world, characterized by broad knowledge scope, long content and non instantiation. The editing objects of previous methods (e.g., MEMIT) were single token or entity, which were not suitable for commonsense knowledge in free-text form. To address the aforementioned challenges, we conducted experiments from two perspectives: knowledge localization and knowledge editing. Firstly, we introduced Knowledge Localization for Free-Text(KLFT) method, revealing the challenges associated with the distribution of commonsense knowledge in MLP and Attention layers, as well as in decentralized distribution. Next, we propose a Dynamics-aware Editing Method(DEM), which utilizes a Dynamics-aware Module to locate the parameter positions corresponding to commonsense knowledge, and uses Knowledge Editing Module to update knowledge. The DEM method fully explores the potential of the MLP and Attention layers, and successfully edits commonsense knowledge based on free-text. The experimental results indicate that the DEM can achieve excellent editing performance.
* 11 pages, 8 figures
PSG: Prompt-based Sequence Generation for Acronym Extraction
Dec 09, 2021
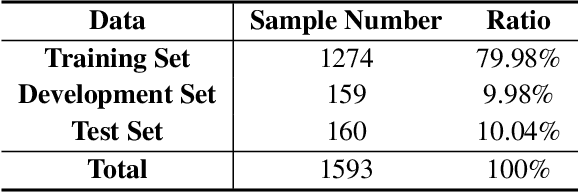
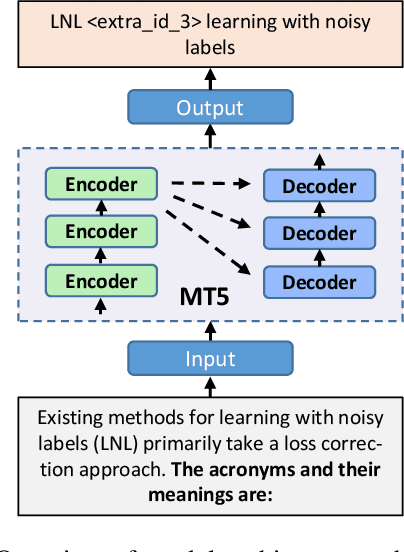
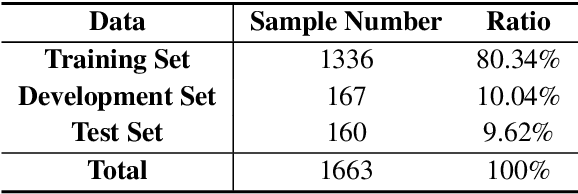
Acronym extraction aims to find acronyms (i.e., short-forms) and their meanings (i.e., long-forms) from the documents, which is important for scientific document understanding (SDU@AAAI-22) tasks. Previous works are devoted to modeling this task as a paragraph-level sequence labeling problem. However, it lacks the effective use of the external knowledge, especially when the datasets are in a low-resource setting. Recently, the prompt-based method with the vast pre-trained language model can significantly enhance the performance of the low-resourced downstream tasks. In this paper, we propose a Prompt-based Sequence Generation (PSG) method for the acronym extraction task. Specifically, we design a template for prompting the extracted acronym texts with auto-regression. A position extraction algorithm is designed for extracting the position of the generated answers. The results on the acronym extraction of Vietnamese and Persian in a low-resource setting show that the proposed method outperforms all other competitive state-of-the-art (SOTA) methods.
SimCLAD: A Simple Framework for Contrastive Learning of Acronym Disambiguation
Dec 09, 2021
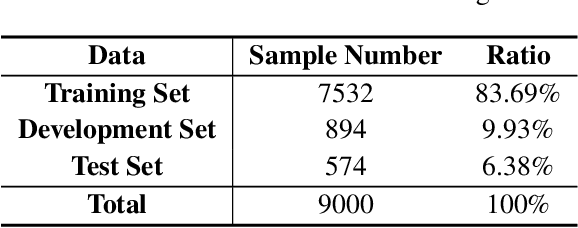
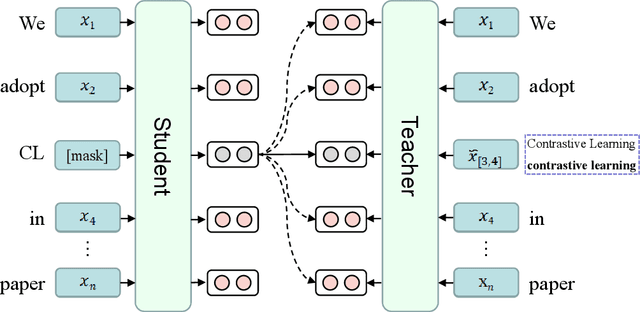
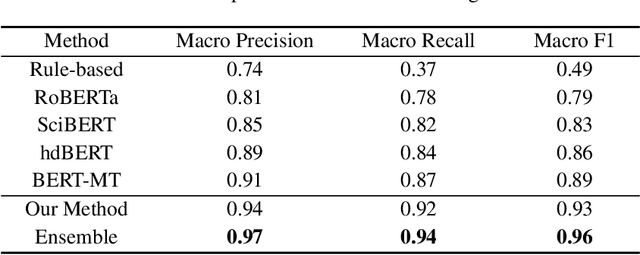
Acronym disambiguation means finding the correct meaning of an ambiguous acronym from the dictionary in a given sentence, which is one of the key points for scientific document understanding (SDU@AAAI-22). Recently, many attempts have tried to solve this problem via fine-tuning the pre-trained masked language models (MLMs) in order to obtain a better acronym representation. However, the acronym meaning is varied under different contexts, whose corresponding phrase representation mapped in different directions lacks discrimination in the entire vector space. Thus, the original representations of the pre-trained MLMs are not ideal for the acronym disambiguation task. In this paper, we propose a Simple framework for Contrastive Learning of Acronym Disambiguation (SimCLAD) method to better understand the acronym meanings. Specifically, we design a continual contrastive pre-training method that enhances the pre-trained model's generalization ability by learning the phrase-level contrastive distributions between true meaning and ambiguous phrases. The results on the acronym disambiguation of the scientific domain in English show that the proposed method outperforms all other competitive state-of-the-art (SOTA) methods.
ADBCMM : Acronym Disambiguation by Building Counterfactuals and Multilingual Mixing
Dec 08, 2021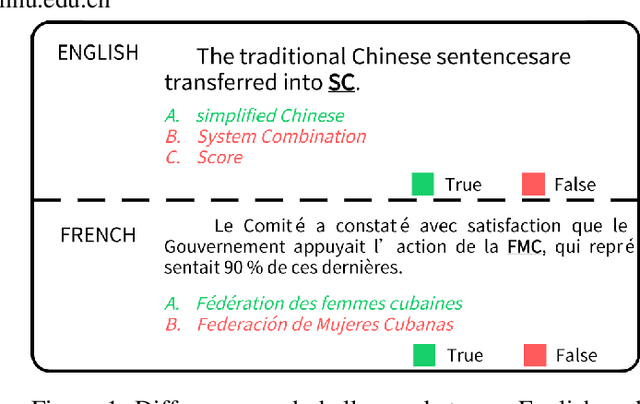
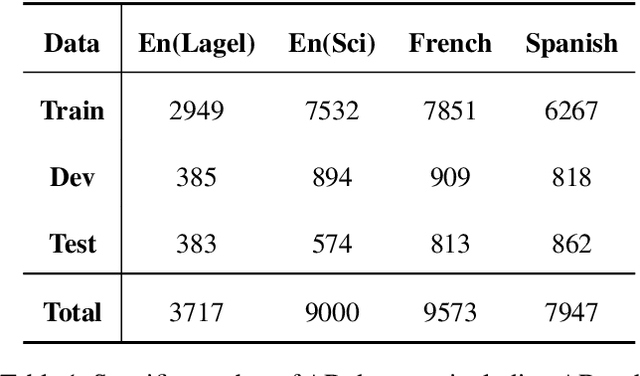
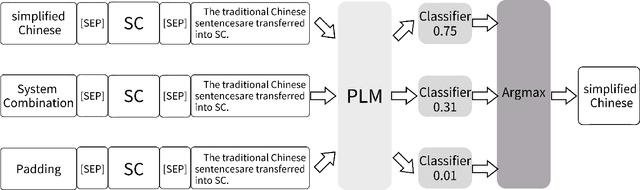
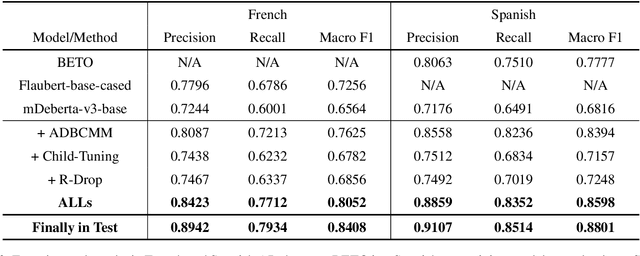
Scientific documents often contain a large number of acronyms. Disambiguation of these acronyms will help researchers better understand the meaning of vocabulary in the documents. In the past, thanks to large amounts of data from English literature, acronym task was mainly applied in English literature. However, for other low-resource languages, this task is difficult to obtain good performance and receives less attention due to the lack of large amount of annotation data. To address the above issue, this paper proposes an new method for acronym disambiguation, named as ADBCMM, which can significantly improve the performance of low-resource languages by building counterfactuals and multilingual mixing. Specifically, by balancing data bias in low-resource langauge, ADBCMM will able to improve the test performance outside the data set. In SDU@AAAI-22 - Shared Task 2: Acronym Disambiguation, the proposed method won first place in French and Spanish. You can repeat our results here https://github.com/WENGSYX/ADBCMM.