 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-context Ranking Preference Optimization
Apr 21, 2025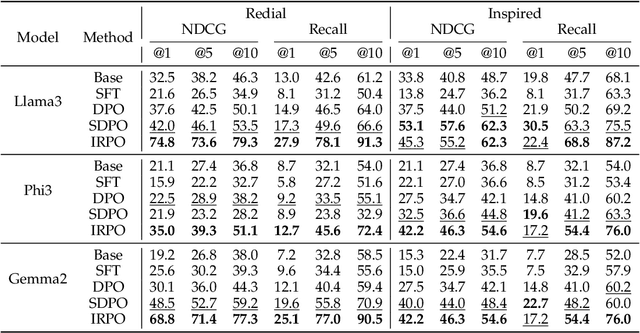
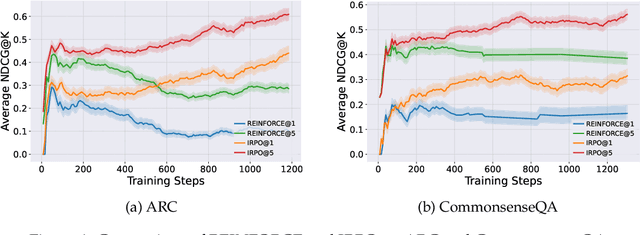
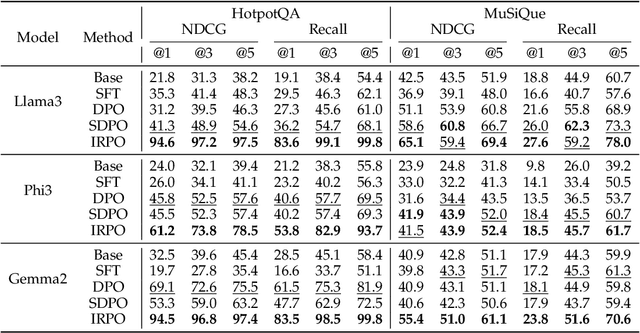
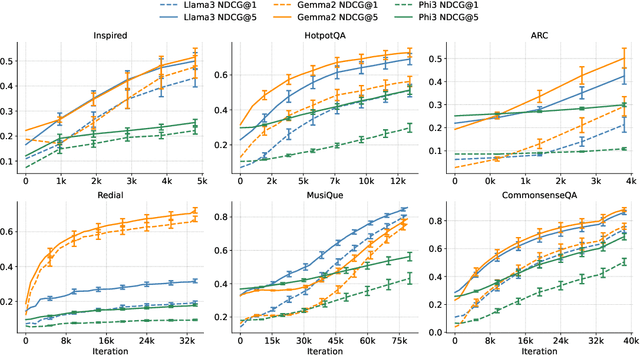
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.
Improving In-Context Learning with Reasoning Distillation
Apr 14, 2025



Language models rely on semantic priors to perform in-context learning, which leads to poor performance on tasks involving inductive reasoning. Instruction-tuning methods based on imitation learning can superficially enhance the in-context learning performance of language models, but they often fail to improve the model's understanding of the underlying rules that connect inputs and outputs in few-shot demonstrations. We propose ReDis, a reasoning distillation technique designed to improve the inductive reasoning capabilities of language models. Through a careful combination of data augmentation, filtering, supervised fine-tuning, and alignment, ReDis achieves significant performance improvements across a diverse range of tasks, including 1D-ARC, List Function, ACRE, and MiniSCAN. Experiments on three language model backbones show that ReDis outperforms equivalent few-shot prompting baselines across all tasks and even surpasses the teacher model, GPT-4o, in some cases. ReDis, based on the LLaMA-3 backbone, achieves relative improvements of 23.2%, 2.8%, and 66.6% over GPT-4o on 1D-ARC, ACRE, and MiniSCAN, respectively, within a similar hypothesis search space. The code, dataset, and model checkpoints will be made available at https://github.com/NafisSadeq/reasoning-distillation.git.
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models
Apr 09, 2025Personalized preference alignment for large language models (LLMs), the process of tailoring LLMs to individual users' preferences, is an emerging research direction spanning the area of NLP and personalization. In this survey, we present an analysis of works on personalized alignment and modeling for LLMs. We introduce a taxonomy of preference alignment techniques, including training time, inference time, and additionally, user-modeling based methods. We provide analysis and discussion on the strengths and limitations of each group of techniques and then cover evaluation, benchmarks, as well as open problems in the field.
Toward Holistic Evaluation of Recommender Systems Powered by Generative Models
Apr 09, 2025Recommender systems powered by generative models (Gen-RecSys) extend beyond classical item ranking by producing open-ended content, which simultaneously unlocks richer user experiences and introduces new risks. On one hand, these systems can enhance personalization and appeal through dynamic explanations and multi-turn dialogues. On the other hand, they might venture into unknown territory-hallucinating nonexistent items, amplifying bias, or leaking private information. Traditional accuracy metrics cannot fully capture these challenges, as they fail to measure factual correctness, content safety, or alignment with user intent. This paper makes two main contributions. First, we categorize the evaluation challenges of Gen-RecSys into two groups: (i) existing concerns that are exacerbated by generative outputs (e.g., bias, privacy) and (ii) entirely new risks (e.g., item hallucinations, contradictory explanations). Second, we propose a holistic evaluation approach that includes scenario-based assessments and multi-metric checks-incorporating relevance, factual grounding, bias detection, and policy compliance. Our goal is to provide a guiding framework so researchers and practitioners can thoroughly assess Gen-RecSys, ensuring effective personalization and responsible deployment.
LaViC: Adapting Large Vision-Language Models to Visually-Aware Conversational Recommendation
Mar 30, 2025



Conversational recommender systems engage users in dialogues to refine their needs and provide more personalized suggestions. Although textual information suffices for many domains, visually driven categories such as fashion or home decor potentially require detailed visual information related to color, style, or design. To address this challenge, we propose LaViC (Large Vision-Language Conversational Recommendation Framework), a novel approach that integrates compact image representations into dialogue-based recommendation systems. LaViC leverages a large vision-language model in a two-stage process: (1) visual knowledge self-distillation, which condenses product images from hundreds of tokens into a small set of visual tokens in a self-distillation manner, significantly reducing computational overhead, and (2) recommendation prompt tuning, which enables the model to incorporate both dialogue context and distilled visual tokens, providing a unified mechanism for capturing textual and visual features. To support rigorous evaluation of visually-aware conversational recommendation, we construct a new dataset by aligning Reddit conversations with Amazon product listings across multiple visually oriented categories (e.g., fashion, beauty, and home). This dataset covers realistic user queries and product appearances in domains where visual details are crucial. Extensive experiments demonstrate that LaViC significantly outperforms text-only conversational recommendation methods and open-source vision-language baselines. Moreover, LaViC achieves competitive or superior accuracy compared to prominent proprietary baselines (e.g., GPT-3.5-turbo, GPT-4o-mini, and GPT-4o), demonstrating the necessity of explicitly using visual data for capturing product attributes and showing the effectiveness of our vision-language integration. Our code and dataset are available at https://github.com/jeon185/LaViC.
Towards Agentic Recommender Systems in the Era of Multimodal Large Language Models
Mar 20, 2025Recent breakthroughs in Large Language Models (LLMs) have led to the emergence of agentic AI systems that extend beyond the capabilities of standalone models. By empowering LLMs to perceive external environments, integrate multimodal information, and interact with various tools, these agentic systems exhibit greater autonomy and adaptability across complex tasks. This evolution brings new opportunities to recommender systems (RS): LLM-based Agentic RS (LLM-ARS) can offer more interactive, context-aware, and proactive recommendations, potentially reshaping the user experience and broadening the application scope of RS. Despite promising early results, fundamental challenges remain, including how to effectively incorporate external knowledge, balance autonomy with controllability, and evaluate performance in dynamic, multimodal settings. In this perspective paper, we first present a systematic analysis of LLM-ARS: (1) clarifying core concepts and architectures; (2) highlighting how agentic capabilities -- such as planning, memory, and multimodal reasoning -- can enhance recommendation quality; and (3) outlining key research questions in areas such as safety, efficiency, and lifelong personalization. We also discuss open problems and future directions, arguing that LLM-ARS will drive the next wave of RS innovation. Ultimately, we foresee a paradigm shift toward intelligent, autonomous, and collaborative recommendation experiences that more closely align with users' evolving needs and complex decision-making processes.
BiasEdit: Debiasing Stereotyped Language Models via Model Editing
Mar 11, 2025



Previous studies have established that language models manifest stereotyped biases. Existing debiasing strategies, such as retraining a model with counterfactual data, representation projection, and prompting often fail to efficiently eliminate bias or directly alter the models' biased internal representations. To address these issues, we propose BiasEdit, an efficient model editing method to remove stereotypical bias from language models through lightweight networks that act as editors to generate parameter updates. BiasEdit employs a debiasing loss guiding editor networks to conduct local edits on partial parameters of a language model for debiasing while preserving the language modeling abilities during editing through a retention loss. Experiments on StereoSet and Crows-Pairs demonstrate the effectiveness, efficiency, and robustness of BiasEdit in eliminating bias compared to tangental debiasing baselines and little to no impact on the language models' general capabilities. In addition, we conduct bias tracing to probe bias in various modules and explore bias editing impacts on different components of language models.
Active Learning for Direct Preference Optimization
Mar 03, 2025Direct preference optimization (DPO) is a form of reinforcement learning from human feedback (RLHF) where the policy is learned directly from preferential feedback. Although many models of human preferences exist, the critical task of selecting the most informative feedback for training them is under-explored. We propose an active learning framework for DPO, which can be applied to collect human feedback online or to choose the most informative subset of already collected feedback offline. We propose efficient algorithms for both settings. The key idea is to linearize the DPO objective at the last layer of the neural network representation of the optimized policy and then compute the D-optimal design to collect preferential feedback. We prove that the errors in our DPO logit estimates diminish with more feedback. We show the effectiveness of our algorithms empirically in the setting that matches our theory and also on large language models.
Code to Think, Think to Code: A Survey on Code-Enhanced Reasoning and Reasoning-Driven Code Intelligence in LLMs
Feb 26, 2025



In large language models (LLMs), code and reasoning reinforce each other: code offers an abstract, modular, and logic-driven structure that supports reasoning, while reasoning translates high-level goals into smaller, executable steps that drive more advanced code intelligence. In this study, we examine how code serves as a structured medium for enhancing reasoning: it provides verifiable execution paths, enforces logical decomposition, and enables runtime validation. We also explore how improvements in reasoning have transformed code intelligence from basic completion to advanced capabilities, enabling models to address complex software engineering tasks through planning and debugging. Finally, we identify key challenges and propose future research directions to strengthen this synergy, ultimately improving LLM's performance in both areas.
Latent Factor Models Meets Instructions:Goal-conditioned Latent Factor Discovery without Task Supervision
Feb 21, 2025Instruction-following LLMs have recently allowed systems to discover hidden concepts from a collection of unstructured documents based on a natural language description of the purpose of the discovery (i.e., goal). Still, the quality of the discovered concepts remains mixed, as it depends heavily on LLM's reasoning ability and drops when the data is noisy or beyond LLM's knowledge. We present Instruct-LF, a goal-oriented latent factor discovery system that integrates LLM's instruction-following ability with statistical models to handle large, noisy datasets where LLM reasoning alone falls short. Instruct-LF uses LLMs to propose fine-grained, goal-related properties from documents, estimates their presence across the dataset, and applies gradient-based optimization to uncover hidden factors, where each factor is represented by a cluster of co-occurring properties. We evaluate latent factors produced by Instruct-LF on movie recommendation, text-world navigation, and legal document categorization tasks. These interpretable representations improve downstream task performance by 5-52% than the best baselines and were preferred 1.8 times as often as the best alternative, on average, in human evaluation.